


Dybfalsk lyd har en fortælling:Forskere bruger flydende dynamik til at spotte kunstige bedragerstemmer
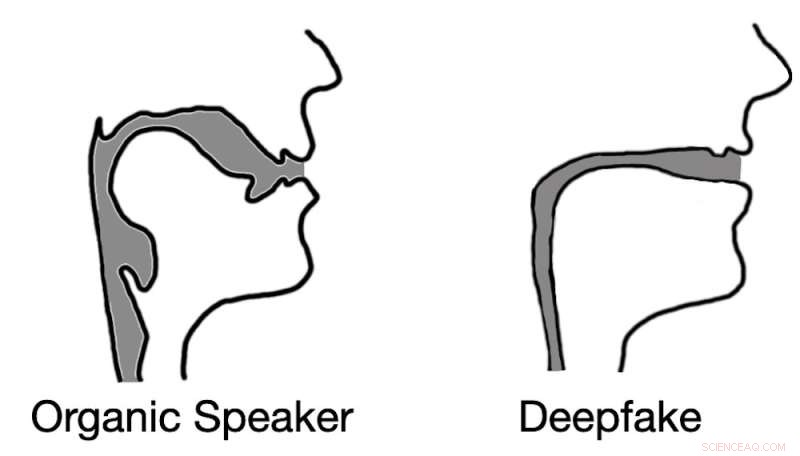
Dybt forfalsket lyd resulterer ofte i vokalkanalrekonstruktioner, der ligner sugerør snarere end biologiske vokalkanaler. Kredit:Logan Blue et al., CC BY-ND
Forestil dig følgende scenarie. En telefon ringer. En kontormedarbejder svarer på det og hører sin chef, i panik, fortælle ham, at hun glemte at overføre penge til den nye entreprenør, før hun tog afsted for dagen, og har brug for ham til at gøre det. Hun giver ham bankoverførselsoplysningerne, og med pengene overført er krisen blevet afværget.
Arbejderen læner sig tilbage i stolen, tager en dyb indånding og ser på, hvordan hans chef træder ind af døren. Stemmen i den anden ende af opkaldet var ikke hans chef. Faktisk var det ikke engang et menneske. Stemmen, han hørte, var en lyddeepfake, en maskingenereret lydeksempel designet til at lyde præcis som hans chef.
Angreb som dette ved hjælp af optaget lyd har allerede fundet sted, og deepfakes til samtalelyd er muligvis ikke langt væk.
Deepfakes, både lyd og video, har kun været mulige med udviklingen af sofistikerede maskinlæringsteknologier i de seneste år. Deepfakes har bragt et nyt niveau af usikkerhed med sig omkring digitale medier. For at opdage deepfakes har mange forskere vendt sig til at analysere visuelle artefakter - små fejl og uoverensstemmelser - fundet i video-deepfakes.
Audio deepfakes udgør potentielt en endnu større trussel, fordi folk ofte kommunikerer verbalt uden video – for eksempel via telefonopkald, radio og stemmeoptagelser. Disse talekommunikationer udvider i høj grad mulighederne for angribere for at bruge deepfakes.
For at detektere lyd dybe falske har vi og vores forskerkolleger ved University of Florida udviklet en teknik, der måler de akustiske og flydende dynamiske forskelle mellem stemmeprøver skabt organisk af menneskelige højttalere og dem, der genereres syntetisk af computere.
Økologiske vs. syntetiske stemmer
Mennesker vokaliserer ved at tvinge luft over de forskellige strukturer i stemmekanalen, herunder stemmelæber, tunge og læber. Ved at omarrangere disse strukturer ændrer du de akustiske egenskaber af din stemmekanal, så du kan skabe over 200 forskellige lyde eller fonemer. Men menneskelig anatomi begrænser fundamentalt den akustiske adfærd af disse forskellige fonemer, hvilket resulterer i et relativt lille udvalg af korrekte lyde for hver.
I modsætning hertil skabes lyddeepfakes ved først at tillade en computer at lytte til lydoptagelser af en målrettet offerhøjttaler. Afhængigt af de nøjagtige anvendte teknikker skal computeren muligvis lytte til så lidt som 10 til 20 sekunders lyd. Denne lyd bruges til at udtrække nøgleinformation om de unikke aspekter af ofrets stemme.
Angriberen vælger en sætning, som deepfake skal tale og genererer derefter ved hjælp af en modificeret tekst-til-tale-algoritme en lydprøve, der lyder som om offeret siger den valgte sætning. Denne proces med at skabe et enkelt dybt falsk lydeksempel kan udføres på få sekunder, hvilket potentielt giver angribere tilstrækkelig fleksibilitet til at bruge den dybe stemme i en samtale.
Opdagelse af lyddeepfakes
Det første trin i at skelne tale produceret af mennesker fra tale genereret af deepfakes er at forstå, hvordan man akustisk modellerer stemmekanalen. Heldigvis har videnskabsmænd teknikker til at vurdere, hvordan nogen - eller noget væsen som en dinosaur - ville lyde ud fra anatomiske målinger af dens stemmekanal.
Vi gjorde det omvendte. Ved at vende mange af de samme teknikker om, var vi i stand til at udtrække en tilnærmelse af en højttalers stemmekanal under et talesegment. Dette gjorde det muligt for os effektivt at kigge ind i anatomien af den højttaler, der skabte lydeksemplet.
Herfra antog vi, at deepfake lydprøver ikke ville blive begrænset af de samme anatomiske begrænsninger, som mennesker har. Med andre ord simulerede analysen af dybt forfalskede lydprøver vokalkanalformer, som ikke eksisterer hos mennesker.
Vores testresultater bekræftede ikke kun vores hypotese, men afslørede også noget interessant. Når vi udtog estimeringer af stemmekanalen fra deepfake-lyd, fandt vi ud af, at estimeringerne ofte var komisk forkerte. For eksempel var det almindeligt, at deepfake-lyd resulterede i stemmekanaler med samme relative diameter og konsistens som et sugerør, i modsætning til menneskelige stemmekanaler, som er meget bredere og mere varierende i form.
Denne erkendelse viser, at deepfake lyd, selv når den overbeviser for menneskelige lyttere, langt fra kan skelnes fra menneskeskabt tale. Ved at estimere den anatomi, der er ansvarlig for at skabe den observerede tale, er det muligt at identificere, om lyden blev genereret af en person eller en computer.
Hvorfor dette betyder noget
Dagens verden er defineret af digital udveksling af medier og information. Alt fra nyheder til underholdning til samtaler med pårørende foregår typisk via digitale udvekslinger. Selv i deres barndom underminerer dybfalsk video og lyd den tillid, folk har til disse udvekslinger, hvilket effektivt begrænser deres anvendelighed.
Hvis den digitale verden skal forblive en kritisk ressource for information i folks liv, er effektive og sikre teknikker til at bestemme kilden til en lydprøve afgørende. + Udforsk yderligere
Identifikation af falske stemmeoptagelser
Denne artikel er genudgivet fra The Conversation under en Creative Commons-licens. Læs den originale artikel. 
Sidste artikelLA Unified cyberangribere kræver løsesum
Næste artikelE-båndssendermodul baseret på GaN til 6G mobilkommunikation
 Varme artikler
Varme artikler
-
 Samsung Electronics flager et rekordstort driftsresultat på 14,7 miaSamsung Electronics havde et driftsoverskud i første kvartal på 15,6 billioner won ($14,7 milliarder), rekord for en periode på tre måneder, da det nød godt af den stigende efterspørgsel efter sine hu
Samsung Electronics flager et rekordstort driftsresultat på 14,7 miaSamsung Electronics havde et driftsoverskud i første kvartal på 15,6 billioner won ($14,7 milliarder), rekord for en periode på tre måneder, da det nød godt af den stigende efterspørgsel efter sine hu -
 British Airways annoncerer en enorm Boeing -ordreBritish Airways vil bestille fly til en værdi af milliarder dollars fra Boeing, lød det torsdag British Airways annoncerede torsdag en aftale på flere milliarder dollars om køb af op til 42 Boeing
British Airways annoncerer en enorm Boeing -ordreBritish Airways vil bestille fly til en værdi af milliarder dollars fra Boeing, lød det torsdag British Airways annoncerede torsdag en aftale på flere milliarder dollars om køb af op til 42 Boeing -
 Verdens anden EPR-atomreaktor begynder at arbejde i KinaDe to EPR-reaktorer på Taishan-atomkraftværket vil være de kraftigste i verden, når de er fuldt færdige og kan forsyne fem millioner kinesiske brugere, siger dets ejere En næste generation af EPR-
Verdens anden EPR-atomreaktor begynder at arbejde i KinaDe to EPR-reaktorer på Taishan-atomkraftværket vil være de kraftigste i verden, når de er fuldt færdige og kan forsyne fem millioner kinesiske brugere, siger dets ejere En næste generation af EPR- -
 PaintBot:En dyb lærende studerende, der træner og efterligner gamle mestreStyle -emulering ved hjælp af PaintBot:Forskerne bruger tre malerier (øverste række) af Pointillism -stilen som træningsdatasæt til deres forstærkningslæringsalgoritme. Ved hjælp af billederne vist i
PaintBot:En dyb lærende studerende, der træner og efterligner gamle mestreStyle -emulering ved hjælp af PaintBot:Forskerne bruger tre malerier (øverste række) af Pointillism -stilen som træningsdatasæt til deres forstærkningslæringsalgoritme. Ved hjælp af billederne vist i
- Klimakonferencen i Bangkok lyder alarm forud for FN-topmødet
- For at få kunderne til at købe mere i fremtiden, hjælpe dem med at købe en gave
- Vurdering af faren for droneangreb:unik testbænk til måling af kollisionspåvirkning
- Brug af solenergi i det daglige liv
- Forbereder fremtidige opdagelsesrejsende til en tilbagevenden til Månen
- FN-rapport for at fremhæve et presserende behov for en naturredningsplan