


Et computersystem i hukommelsen baseret på stablede 3D-resistive hukommelser
Figur, der opsummerer evalueringen og ydeevnen af forskernes computing-in-memory makro. Kredit:Huo et al (Nature Electronics , 2022).
Maskinlæringsarkitekturer baseret på konvolutionelle neurale netværk (CNN'er) har vist sig at være yderst værdifulde for en bred vifte af applikationer, lige fra computersyn til analyse af billeder og behandling eller generering af menneskeligt sprog. For at tackle mere avancerede opgaver bliver disse arkitekturer dog stadig mere komplekse og beregningskrævende.
I de senere år har mange elektronikingeniører verden over således forsøgt at udvikle enheder, der kan understøtte lagring og beregningsmæssig belastning af komplekse CNN-baserede arkitekturer. Dette inkluderer tættere hukommelsesenheder, der kan understøtte store mængder vægte (dvs. de parametre, der kan trænes og ikke-trænes, der tages i betragtning af de forskellige lag af CNN'er).
Forskere ved det kinesiske videnskabsakademi, Beijing Institute of Technology og andre universiteter i Kina har for nylig udviklet et nyt computing-in-memory system, der kan hjælpe med at køre mere komplekse CNN-baserede modeller mere effektivt. Deres hukommelseskomponent, introduceret i et papir udgivet i Nature Electronics , er baseret på ikke-flygtige computing-in-memory makroer lavet af 3D memristor arrays.
"Skalering af sådanne systemer til 3D-arrays kunne give højere parallelitet, kapacitet og tæthed til de nødvendige vektor-matrix multiplikationsoperationer," skrev Qiang Huo og hans kolleger i deres papir. "Skalering til tre dimensioner er imidlertid udfordrende på grund af produktions- og enhedsvariabilitetsproblemer. Vi rapporterer en to-kilobit ikke-flygtig computing-in-memory makro, der er baseret på en tredimensionel vertikal resistiv tilfældig adgangshukommelse fremstillet ved hjælp af en 55 nm komplementær metal-oxid-halvlederproces."
Resistive hukommelser med tilfældig adgang, eller RRAM'er, er ikke-flygtige (dvs. bevarer data selv efter strømafbrydelser) lagerenheder baseret på memristorer. Memristorer er elektroniske komponenter, der kan begrænse eller regulere strømmen af elektrisk strøm i kredsløb, mens de registrerer mængden af ladning, der tidligere strømmede gennem dem.
RRAM'er fungerer i det væsentlige ved at variere modstanden på tværs af en memristor. Mens tidligere undersøgelser har vist det store potentiale af disse hukommelsesenheder, er konventionelle versioner af disse enheder adskilt fra computermotorer, hvilket begrænser deres mulige anvendelser.
Computing-in-memory RRAM-enheder blev designet til at overvinde denne begrænsning ved at indlejre beregningerne i hukommelsen. Dette kan i høj grad reducere overførslen af data mellem hukommelser og processorer, hvilket i sidste ende forbedrer det overordnede systems energieffektivitet.
Computing-in-memory-enheden skabt af Huo og hans kolleger er en 3D RRAM med lodret stablede lag og perifere kredsløb. Enhedens kredsløb blev fremstillet ved hjælp af 55 nm CMOS-teknologi, teknologien, der understøtter de fleste integrerede kredsløb på markedet i dag.
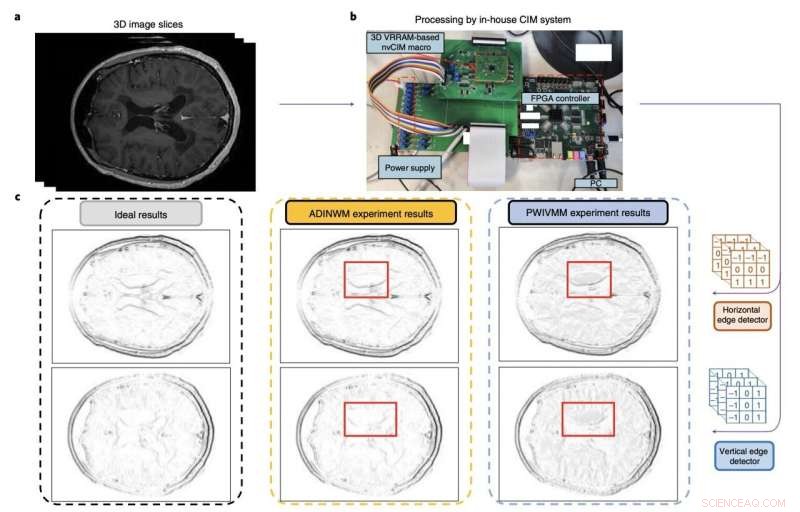
Forskerne evaluerede deres enhed ved at bruge den til at udføre komplekse operationer og til at køre en model til at opdage kanter i MR-hjernescanninger. Holdet trænede deres modeller ved at bruge to eksisterende MRI-datasæt til træning af billedgenkendelsesværktøjer, kendt som MNIST- og CIFAR-10-datasættene.
"Vores makro kan udføre 3D vektor-matrix multiplikationsoperationer med en energieffektivitet på 8,32 tera-operationer pr. –2 ," skrev forskerne i deres papir. "Vi viser, at makroen tilbyder mere nøjagtig hjerne-MRI-kantdetektion og forbedret slutningsnøjagtighed på CIFAR-10-datasættet end konventionelle metoder."
I de indledende tests opnåede det lodrette RRAM-system med computere i hukommelsen skabt af Huo og hans kolleger bemærkelsesværdige resultater, der overgik konventionelle RRAM-tilgange. I fremtiden kan det således vise sig at være yderst værdifuldt til at køre komplekse CNN-baserede modeller mere energieffektivt, samtidig med at det muliggør bedre nøjagtighed og ydeevne. + Udforsk yderligere
En fire-megabit nvCIM-makro til edge AI-enheder
© 2022 Science X Network
 Varme artikler
Varme artikler
-
 Forbedring af bevægelsen af små robotter med mikrohjulMikrobots kan have flere nyttige applikationer, især inden for biomedicinske og sundhedsmæssige rammer. For eksempel, på grund af deres lille størrelse, disse små maskiner kunne indsættes i den mennes
Forbedring af bevægelsen af små robotter med mikrohjulMikrobots kan have flere nyttige applikationer, især inden for biomedicinske og sundhedsmæssige rammer. For eksempel, på grund af deres lille størrelse, disse små maskiner kunne indsættes i den mennes -
 Olie til solenergi:Saudierne presser på for at blive kraftcenter for vedvarende energiSaudiarabisk kronprins Mohammed bin Salman har løftet sløret for planer om at udvikle klodens største solenergiprojekt for 200 milliarder dollars i samarbejde med Japans SoftBank-koncern Saudiarab
Olie til solenergi:Saudierne presser på for at blive kraftcenter for vedvarende energiSaudiarabisk kronprins Mohammed bin Salman har løftet sløret for planer om at udvikle klodens største solenergiprojekt for 200 milliarder dollars i samarbejde med Japans SoftBank-koncern Saudiarab -
 Bach og Adele:Slå jer ud på MuseNetKredit:CC0 Public Domain OpenAI introducerer et musikalsk MuseNet, den musikgenererende AI, der var i nyhederne tidligere på ugen. Nogle AI -seere kaldte musikken OpenAI, der bare blev afsløret so
Bach og Adele:Slå jer ud på MuseNetKredit:CC0 Public Domain OpenAI introducerer et musikalsk MuseNet, den musikgenererende AI, der var i nyhederne tidligere på ugen. Nogle AI -seere kaldte musikken OpenAI, der bare blev afsløret so -
 Mål spiller til styrke, kombinere digitalt salg og butikkerDenne 29. juni, 2016-filbillede viser en Target-butik i Hialeah, Fla. Målkunder udnyttede til fulde forhandlerens afhentnings- og kørselstjenester i løbet af feriesæsonen, klatring 60 procent fra et å
Mål spiller til styrke, kombinere digitalt salg og butikkerDenne 29. juni, 2016-filbillede viser en Target-butik i Hialeah, Fla. Målkunder udnyttede til fulde forhandlerens afhentnings- og kørselstjenester i løbet af feriesæsonen, klatring 60 procent fra et å
- 100-årig fysikmodel replikerer moderne arktisk issmeltning
- Mangel på offentlig påskønnelse bidrager til ensomhed i landbruget, viser undersøgelse
- Komplekse molekyler kan rumme hemmeligheden bag at identificere fremmede liv
- Prognose:40 % chance for, at Jorden snart bliver varmere end Paris-målet
- Opgraderet vandrisikofilter hjælper virksomheder med at reagere på forværrede vandrisici
- Popularitetsafstanden mellem en restaurantplacering og en persons hjemby skæmmer vurderingerne