


Hvorfor deep-learning-metoder med sikkerhed genkender billeder, der er nonsens
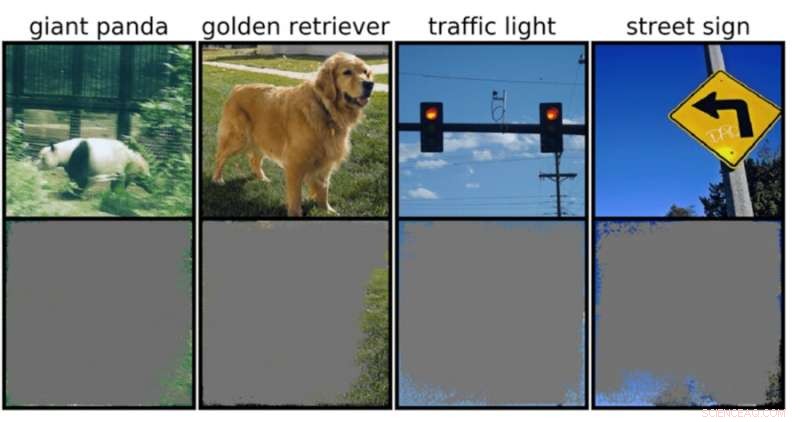
En dyb-billedklassifikator kan bestemme billedklasser med over 90 procent sikkerhed ved at bruge primært billedrammer snarere end selve et objekt. Kredit:Rachel Gordon
På trods af alt det, neurale netværk kan udrette, forstår vi stadig ikke rigtig, hvordan de fungerer. Selvfølgelig kan vi programmere dem til at lære, men at give mening om en maskines beslutningsproces er stadig meget som et fancy puslespil med et svimlende, komplekst mønster, hvor masser af integrerede brikker endnu mangler at blive monteret.
Hvis en model for eksempel forsøgte at klassificere et billede af det nævnte puslespil, kunne den støde på velkendte, men irriterende modstridende angreb eller endda flere almindelige data- eller behandlingsproblemer. Men en ny, mere subtil type fejl, som for nylig blev identificeret af MIT-forskere, er en anden grund til bekymring:"overfortolkning", hvor algoritmer laver sikre forudsigelser baseret på detaljer, der ikke giver mening for mennesker, såsom tilfældige mønstre eller billedkanter.
Dette kan være særligt bekymrende for miljøer med høj indsats, såsom beslutninger på et splitsekund for selvkørende biler og medicinsk diagnostik for sygdomme, der kræver mere øjeblikkelig opmærksomhed. Især autonome køretøjer er stærkt afhængige af systemer, der nøjagtigt kan forstå omgivelserne og derefter træffe hurtige, sikre beslutninger. Netværket brugte specifikke baggrunde, kanter eller særlige mønstre af himlen til at klassificere trafiklys og gadeskilte – uanset hvad der ellers var på billedet.
Holdet fandt ud af, at neurale netværk trænet på populære datasæt som CIFAR-10 og ImageNet led af overfortolkning. Modeller trænet på CIFAR-10 lavede for eksempel sikre forudsigelser, selv når 95 procent af inputbillederne manglede, og resten er meningsløse for mennesker.
"Overfortolkning er et datasætproblem, der er forårsaget af disse meningsløse signaler i datasæt. Ikke alene er disse højsikkerhedsbilleder uigenkendelige, men de indeholder mindre end 10 procent af det originale billede i uvigtige områder, såsom grænser. Vi fandt ud af, at disse billeder var meningsløse for mennesker, men alligevel kan modeller stadig klassificere dem med høj tillid," siger Brandon Carter, MIT Computer Science and Artificial Intelligence Laboratory Ph.D. studerende og hovedforfatter på et papir om forskningen.
Dybbilledklassificerere er meget brugt. Ud over medicinsk diagnose og boostning af autonome køretøjsteknologier er der brugssager inden for sikkerhed, spil og endda en app, der fortæller dig, om noget er eller ikke er en hotdog, for nogle gange har vi brug for tryghed. Teknikken i diskussionen fungerer ved at behandle individuelle pixels fra tonsvis af præ-mærkede billeder, så netværket kan "lære".
Billedklassificering er svær, fordi maskinlæringsmodeller har evnen til at låse fast i disse useriøse subtile signaler. Derefter, når billedklassifikatorer trænes på datasæt såsom ImageNet, kan de lave tilsyneladende pålidelige forudsigelser baseret på disse signaler.
Selvom disse meningsløse signaler kan føre til modelskørhed i den virkelige verden, er signalerne faktisk gyldige i datasættene, hvilket betyder, at overfortolkning ikke kan diagnosticeres ved hjælp af typiske evalueringsmetoder baseret på denne nøjagtighed.
For at finde begrundelsen for modellens forudsigelse på et bestemt input, starter metoderne i nærværende undersøgelse med det fulde billede og spørger gentagne gange, hvad kan jeg fjerne fra dette billede? I bund og grund bliver det ved med at dække over billedet, indtil du står tilbage med det mindste stykke, der stadig træffer en sikker beslutning.
Til det formål kunne det også være muligt at bruge disse metoder som en type valideringskriterier. For eksempel, hvis du har en selvkørende bil, der bruger en trænet maskinlæringsmetode til at genkende stopskilte, kan du teste denne metode ved at identificere den mindste input-delmængde, der udgør et stopskilt. Hvis det består af en trægren, et bestemt tidspunkt på dagen eller noget, der ikke er et stopskilt, kan du være bekymret for, at bilen kan stoppe et sted, den ikke skal.
Selvom det kan se ud til, at modellen er den sandsynlige synder her, er det mere sandsynligt, at datasættene har skylden. "Der er spørgsmålet om, hvordan vi kan ændre datasættene på en måde, der gør det muligt for modeller at blive trænet til i højere grad at efterligne, hvordan et menneske ville tænke på at klassificere billeder og derfor forhåbentlig generalisere bedre i disse scenarier i den virkelige verden, såsom autonom kørsel og medicinsk diagnose, så modellerne ikke har denne useriøse adfærd," siger Carter.
Dette kan betyde, at der oprettes datasæt i mere kontrollerede miljøer. I øjeblikket er det kun billeder, der er udtrukket fra offentlige domæner, der så klassificeres. Men hvis du for eksempel vil lave objektidentifikation, kan det være nødvendigt at træne modeller med objekter med en uinformativ baggrund.
 Varme artikler
Varme artikler
-
 Videokonferencer om privatliv og sikkerhed er langt fra perfekteVideokonferencesoftware kortlagt med hensyn til sikkerhed og beskyttelse af privatlivets fred. Kredit:Elizabeth Stoycheff, CC BY-ND Hvis, før COVID-19, du var bekymret for alle de data, som teknol
Videokonferencer om privatliv og sikkerhed er langt fra perfekteVideokonferencesoftware kortlagt med hensyn til sikkerhed og beskyttelse af privatlivets fred. Kredit:Elizabeth Stoycheff, CC BY-ND Hvis, før COVID-19, du var bekymret for alle de data, som teknol -
 Strækbare kredsløb:Ny proces forenkler produktionen af funktionelle prototyperVed at anvende deres nye tilgang producerede forskerne tre prototyper, hver tager mindre end 5 minutter. Kredit:Saar-Uni Strækbare kredsløb har den fordel, at de også fungerer i tekstiler såsom tø
Strækbare kredsløb:Ny proces forenkler produktionen af funktionelle prototyperVed at anvende deres nye tilgang producerede forskerne tre prototyper, hver tager mindre end 5 minutter. Kredit:Saar-Uni Strækbare kredsløb har den fordel, at de også fungerer i tekstiler såsom tø -
 London står i spidsen for europæiske investeringer i teknologisektoren:undersøgelseKredit:CC0 Public Domain Investeringer i teknologi i hele Europa nåede et rekordniveau i 2019, ifølge en undersøgelse offentliggjort onsdag, med London, der fastholder førstepladsen på trods af Br
London står i spidsen for europæiske investeringer i teknologisektoren:undersøgelseKredit:CC0 Public Domain Investeringer i teknologi i hele Europa nåede et rekordniveau i 2019, ifølge en undersøgelse offentliggjort onsdag, med London, der fastholder førstepladsen på trods af Br -
 Højovnsgasforbrænding:Et bæredygtigt alternativ til stålindustrien?Grafisk abstrakt. Kredit:ACS Omega (2022). DOI:10.1021/acsomega.2c02103 I øjeblikket skifter energiintensive industrier deres produktion og processer mod mere bæredygtige modeller. Således kan indu
Højovnsgasforbrænding:Et bæredygtigt alternativ til stålindustrien?Grafisk abstrakt. Kredit:ACS Omega (2022). DOI:10.1021/acsomega.2c02103 I øjeblikket skifter energiintensive industrier deres produktion og processer mod mere bæredygtige modeller. Således kan indu
- Toyotas kvartalsvise fortjeneste stiger på grund af stigende salg, omkostningsbesparelser
- Tilslutning af hørehjælpemolekyler til øreknoglen
- Bevarelse af en malers arv med nanomaterialer
- Taiwans pangoliner lider kraftigt af vildhundeangreb
- Hvordan man grader ved hjælp af en firkantet rodkurve
- CRISPR-bærende nanopartikler redigerer genomet