


Quantum computing - bryder igennem 49 qubit simuleringsbarrieren
Kredit:IBM
Quantum computing er på tærsklen til at tackle vigtige problemer, der ikke effektivt eller praktisk kan beregnes af andre, mere klassiske midler. At komme forbi denne tærskel kræver, at vi bygger, test og betjen pålidelige kvantecomputere med 50 eller flere qubits.
At opnå dette potentiale vil kræve store fremskridt inden for både videnskab og teknik. For at hjælpe med at gøre disse spring, metoder er nødvendige for at teste kvanteenheder og sammenligne observeret adfærd med ønsket adfærd, så designet, fremstilling, og driften af disse enheder kan forbedres over tid. I særdeleshed, at teste, om de målte resultater observeret på en kvanteenhed er i overensstemmelse med det kvantekredsløb, der udføres, man har brug for evnen til at beregne forventede kvanteamplituder (komplekse tal, der bruges til at beskrive systemers adfærd) for disse resultater for at teste vilkårlige kredsløb. Kvantekredsløb kan betragtes som sæt af instruktioner (porte), der sendes til kvanteenheder for at udføre beregninger.
Det behov gav os et problem. Ved cirka 50 qubits, eksisterende metoder til beregning af kvanteamplituder kræver enten for meget beregning til at være praktisk, eller mere hukommelse end der er tilgængelig på en eksisterende supercomputer, eller begge. IBM Research sammensatte et team i år for at undersøge dette problem, målrettet mod kortdybde kredsløb til systemer på 49 qubits og derover. Vi har offentliggjort vores tilgang til at løse dette problem til arXiv:arxiv.org/abs/1710.05867.
Jeg var en del af dette team og kom med en nøgleidé i et tilsyneladende ubetydeligt øjeblik.
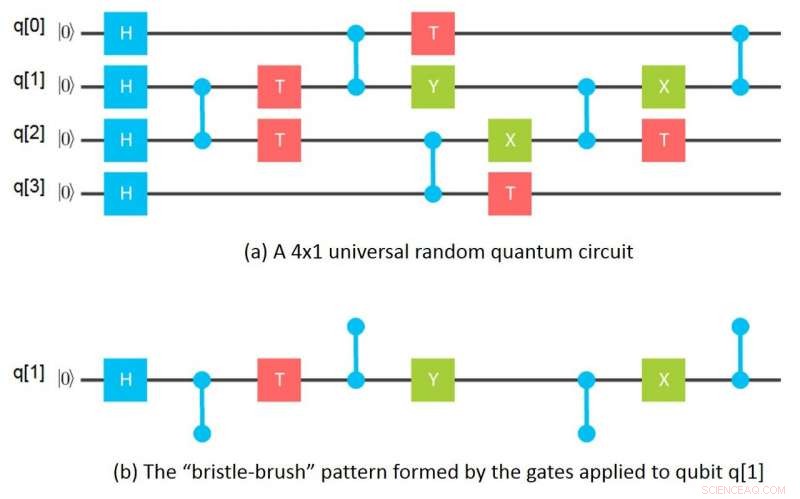
Visualisering af kvanteporte som en børste
En qubit, eller kvantebit, er den grundlæggende informationsenhed i kvanteberegning, ligesom lidt er i klassisk computing. En qubit, imidlertid, kan repræsentere både 0 og 1 samtidigt - faktisk i vægtede kombinationer (f.eks. 37%-0, 63%-1). To qubits kan repræsentere fire værdier samtidigt:00, 01, 10, og 11, igen i vægtede kombinationer. Tilsvarende tre qubits kan repræsentere 2^3, eller otte værdier samtidigt:000, 001, 010, 011, 100, 101, 110, 111. Halvtreds qubits kan repræsentere mere end en kvadrillion værdier samtidigt, og 100 qubits over en kvadrillion i kvadrat.
Når qubits måles, deres kvantetilstande falder sammen til kun en af disse repræsenterede værdier, hvor værdierne af værdierne - kvanteamplituderne - definerer sandsynligheden for at observere disse værdier. Det store løfte om quantum computing er potentialet til at udføre parallelle beregninger over eksponentielt mange mulige resultater, at give kvantetilstande, hvor de ønskede resultater af beregninger har store amplituder og, derfor, vil blive observeret med stor sandsynlighed, når qubits måles.
Mit tilsyneladende ubetydelige øjeblik kom en nat, mens jeg vaskede retter og brugte en børste til at rense et højt glas. Det gik pludselig op for mig, at hvis man ser på de porte, der er påført en given qubit i et netkredsløb, portene danner et børstehårsmønster, hvor børsterne er de sammenfiltrede porte, der påføres den qubit. Matematisk, at "børstehår" af porte svarer til en tensor og børsterne til tensorindekser. En tensor i matematik svarer i det væsentlige til en n-dimensionel matrix inden for datalogi.
Denne indsigt førte straks til ideen om at trække et gitterkredsløb fra hinanden til individuelle "børstehårbørster, "en for hver qubit, derefter beregne de tilsvarende tensorer, og endelig kombinere tensorerne for hver qubit for at beregne kvanteamplituderne for det samlede kredsløb. Næste morgen havde jeg fundet ud af, hvordan man beregner amplituder for en 64 -qubit, dybde 10 kredsløb ved kun at bruge en Gigabyte hukommelse ved at trække grupper på 16 qubits fra hinanden. Derfra sneboldede ideen til mere generelle måder at opdele kredsløb i underkredse på, simulere underkredsløb separat og kombinere resultaterne af underkredsløb i forskellige ordrer for at beregne ønskede amplituder.
Nettoresultatet er en metode til beregning af kvanteamplituder, der kræver størrelsesordener mindre hukommelse end tidligere metoder, mens den stadig kan sammenlignes med den bedste af disse metoder, med hensyn til den udførte beregning pr. amplitude. Disse mindre hukommelseskrav opnås ved hjælp af tensorsnit i kombination med ovenstående indsigt til at beregne outputamplituder for kredsløb i skiver, uden at skulle beregne og/eller gemme alle amplituder på én gang.
Ved beregning af amplituder for målte resultater, kun de skiver, der svarer til de faktiske målte resultater, skal beregnes. Med andre ord, med henblik på at evaluere ydelsen af en kvanteenhed baseret på målte resultater en fuld simulering er ikke nødvendig, og man behøver ikke pådrage sig beregningsomkostninger, der er eksponentielle i antallet af qubits. Dette er en vigtig fordel ved vores tilgang.
Imidlertid, hvis man faktisk er interesseret i at udføre fulde simuleringer, vores opskæringsmetode har en yderligere fordel ved, at skiver kan beregnes helt uafhængigt på en pinligt parallel måde-hvilket betyder, at de let kan adskilles-så beregninger kan distribueres på tværs af et netværk af løst koblede højtydende computerressourcer. Denne mulighed ændrer fuldstændigt økonomien i fulde simuleringer, gør det muligt at simulere kvantekredsløb, der tidligere blev antaget at være umulige at simulere.
Simulerer 49 og 56 qubit kredsløb ved hjælp af en supercomputer
Vores forskergruppe kontaktede Lawrence Livermore National Laboratory (LLNL) og University of Illinois for at gøre denne sidste mulighed til virkelighed. Ved hjælp af Vulcan -supercomputeren på LLNL og Cyclops Tensor Framework oprindeligt udviklet ved University of California, Berkeley til at udføre tensor -manipulationerne, vi valgte først at simulere et 49 -qubit universelt tilfældigt kredsløb med dybde 27, som er blevet foreslået som en demonstration af såkaldt kvanteoverherredømme. Til denne simulering, beregningerne blev opdelt i 2^11 skiver med 2^38 amplituder beregnet pr. skive; 4,5 Terabyte var påkrævet for at holde tensorværdierne. Skiveberegninger blev pinligt paralleliseret på tværs af seks grupper på fire stativer af processorer, hvor hver gruppe på fire stativer omfattede 4, 096 behandlingsnoder med i alt 64 Terabyte hukommelse. Sådanne 49-qubit kredsløb blev tidligere antaget at være umulige at simulere, fordi tidligere metoder ville have krævet otte petabyte hukommelse, som overstiger eksisterende supercomputers kapacitet.
Til vores næste demonstration, vi valgte et 56 -qubit universelt tilfældigt kredsløb med dybde 23, hvilket ville have været umuligt at simulere ved hjælp af tidligere metoder, fordi en Exabyte hukommelse ville have været påkrævet. Beregninger blev opdelt i 2^19 skiver med hver 2^37 amplituder. Men i dette tilfælde valgte vi at beregne amplituder for kun et vilkårligt valgt skive til demonstrationsformål; 3,0 Terabyte var påkrævet for at holde tensorværdier, og beregninger blev udført på to stativer på 2, 048 behandlingsnoder med i alt 32 Terabyte hukommelse.
Ud over disse demonstrationer, vi opdagede også måder at opdele 49-qubit kredsløbet på, så der kun er brug for 96 Gigabyte hukommelse til dets simulering, med kun lidt mere end det dobbelte af beregningskravene. Vi opdagede også en partitionering, der kræver 162 Gigabyte, for hvilke der næsten ikke er nogen stigning i beregningskrav. Der er derfor mulighed for nu at udføre disse simuleringer på klynger af avancerede servere, i stedet for at bruge supercomputere.
Fremskridt inden for simulering vil hjælpe fremskridt inden for kvantehardware
Selvom det fulde omfang af det, der nu klassisk kan beregnes ved hjælp af vores metoder, stadig mangler at blive bestemt, det er klart, at dette fremskridt har gjort det muligt for os at krydse en tærskel i simuleringen af kvantekredsløb med korte dybder på 49 qubits og større. Pragmatisk, metoderne vil lette test og forståelse af driften af fysiske enheder. De vil også lette udviklingen og fejlfinding af kortdybde algoritmer til problemer, hvor kvanteberegning har potentiale til at give reel fordel i forhold til konventionelle metoder.
I hvert fald for kvanteenheder, der nu er under udvikling eller på tegnebrættene, evnen til at udføre disse simuleringer er nu blevet et spørgsmål om mængden af beregningsressourcer, der økonomisk kan skaffes og ikke om simuleringerne overhovedet kan udføres fysisk. For eksempel, i tilfælde af vores 56-qubit simulering, en fuld simulering blev ikke udført blot fordi vores tidsfordeling på Vulcan var løbet tør. Der er ingen tvivl om, at en fuld 56-qubit kortdybdesimulering nu fysisk kan udføres. Løbetiden for disse simuleringer er heller ikke fysisk begrænset af de ressourcer, der er tilgængelige på isolerede computersystemer. Fordi skiveberegninger kan være pinligt parallelle, de kan distribueres på tværs af netværk af løst koblede systemer med minimal kommunikation, gør det muligt at opnå en stærk skalerbarhed op til antallet af skiver. Cloudbaseret kvantesimulering kan i sidste ende tillade simulering af temmelig store kvantekredsløb.
Betyder det, at vi ikke har brug for egentlige kvantecomputere? Slet ikke. Vi får absolut brug for dem! Afhængigt af den særlige applikationstype, vi får brug for fysiske kvantecomputere til at udføre beregninger, der enten vil kræve for meget hukommelse, eller for meget processorkraft til økonomisk udførelse på klassiske computere. Og, på et tidspunkt, vi vil virkelig have beviser for, at kvantecomputere vil have en fordel i forhold til klassiske computere til nogle praktiske applikationer, i en virkelig virkelighedens forstand.
Dette er ikke en kunstig forestilling om "kvanteoverherredømme". Hellere, vi er nu i en periode, hvor vi er ved at blive kvanteklare til at drage fuld fordel af kvantehardwaren, software og ingeniørmuligheder, som vi lægger online. Simulering er allerede en integreret del af denne kvanteklare fase.
IBM har stillet adgang til simulatorer og egentlig hardware på fem og 16 qubits til rådighed som en del af IBM Q -oplevelsen, som giver ressourcer til at lære og eksperimentere med. Vi har også en kvante -SDK, eller Quantum Information Software Kit (QISKit) for at gøre det let at bygge kredsløb. For at lære mere om, hvordan du kommer i gang, vi har leveret Jupyter notebook -eksempler på github.
Efterhånden som enhedsteknologien skrider frem, vi vil bevæge os ind i en periode med kvantefordele, hvor en bred vifte af virksomheder, forskere og ingeniører vil fuldt ud udnytte hardwaren og kraften i quantum computing til fortsat at løse stadig mere vanskelige og komplekse problemer. I løbet af denne kvantefordelfase, avancerede simuleringskapaciteter vil være nødvendige for at understøtte både forskning og udvikling af nye kvantealgoritmer samt fremskridt i selve enhedsteknologien.
Sidste artikelSpider-web labyrinter kan hjælpe med at reducere støjforurening
Næste artikelFysik øger kunstige intelligensmetoder
 Varme artikler
Varme artikler
-
 Undersøgelse opnår en ny rekordfiber QKD transmissionsafstand på over 509 kmKredit:Chen et al. Sende-eller-ikke-sende twin-field (SNS-TF) -protokollen har hidtil vist sig at være en meget lovende strategi for at opnå høje takster over lange afstande i quantum key distribu
Undersøgelse opnår en ny rekordfiber QKD transmissionsafstand på over 509 kmKredit:Chen et al. Sende-eller-ikke-sende twin-field (SNS-TF) -protokollen har hidtil vist sig at være en meget lovende strategi for at opnå høje takster over lange afstande i quantum key distribu -
 Bag dødvandsfænomenetHvad får skibe til på mystisk vis at bremse eller endda stoppe, mens de rejser, selvom deres motorer fungerer korrekt? Dette blev først observeret i 1893 og blev beskrevet eksperimentelt i 1904 uden a
Bag dødvandsfænomenetHvad får skibe til på mystisk vis at bremse eller endda stoppe, mens de rejser, selvom deres motorer fungerer korrekt? Dette blev først observeret i 1893 og blev beskrevet eksperimentelt i 1904 uden a -
 Hvorfor er der overhovedet noget stof i universet? Ny undersøgelse kaster lysChris Abel og Nick Ayres fra University of Sussex foran neutroneksperiment. Kredit:Paul Scherrer Institute Forskere ved University of Sussex har målt en egenskab ved neutronen - en fundamental par
Hvorfor er der overhovedet noget stof i universet? Ny undersøgelse kaster lysChris Abel og Nick Ayres fra University of Sussex foran neutroneksperiment. Kredit:Paul Scherrer Institute Forskere ved University of Sussex har målt en egenskab ved neutronen - en fundamental par -
 Fysikken i ægdråpsvidenskabsprojekterÆggedråpseksperimentet - et videnskabsprojekt, hvor studerende skaber måder at forhindre et æg i at bryde, når det falder fra en bestemt højde - er et højdepunkt i de fleste fysikklasser. Læs videre f
Fysikken i ægdråpsvidenskabsprojekterÆggedråpseksperimentet - et videnskabsprojekt, hvor studerende skaber måder at forhindre et æg i at bryde, når det falder fra en bestemt højde - er et højdepunkt i de fleste fysikklasser. Læs videre f
- Underdog-telefonproducenter forsøger at undslippe skyggen af giganter på topmessen
- Sjove tricks mulige med Google vidensbokse, der er uden grin for nogle
- Nylons Egenskaber & Anvendelser
- Plastposer kunne være mere miljøvenlige end papir- og bomuldsposer i byer som Singapore
- Hvad hvis vi dækkede en by i en kæmpe glaskuppel?
- En ny måde at producere rent brintbrændstof fra vand ved hjælp af sollys