


Overraskende præference for enkelhed findes i fælles model
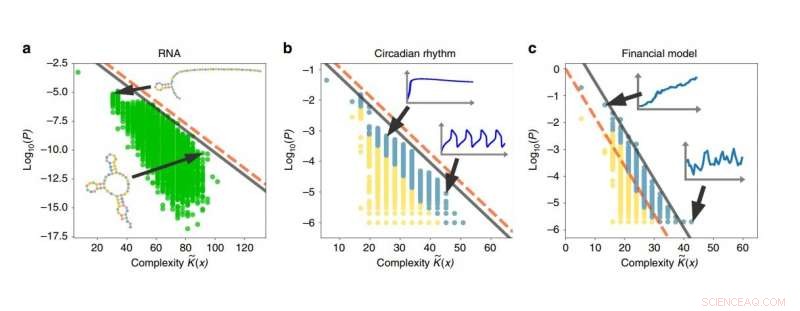
Eksempler på enkelhedsforskydning i RNA -sekvenser, døgnrytme, og økonomiske modeller. Jo højere kompleksiteten af et output, jo lavere er sandsynligheden for, at output vil blive genereret. Kredit:Dingle, et al. Udgivet i Naturkommunikation
Forskere har opdaget, at input-output-kort, som er meget udbredt inden for videnskab og teknik til at modellere systemer lige fra fysik til finansiering, er stærkt forudindtaget i retning af at producere enkle output. Resultaterne er overraskende, som naivt er der ingen grund til at mistanke om, at et output skal være mere sandsynligt end noget andet.
Forskerne, Kamaludin Dingle, Chico Q. Camargo, og Ard A. Louis, ved University of Oxford og ved Gulf University for Science and Technology, har offentliggjort et papir om deres resultater i et nyligt nummer af Naturkommunikation .
"Den største betydning af vores arbejde er vores forudsigelse om, at enkelhedens bias - at simple output eksponentielt er mere tilbøjelige til at blive genereret end komplekse output - holder for en lang række systemer inden for videnskab og teknik, "Fortalte Louis Phys.org . "Enkelhedsforskydningen indebærer, at for et system bestående af mange forskellige interagerende dele - sig f.eks. et kredsløb med mange komponenter, et netværk med mange kemiske reaktioner, osv. - de fleste kombinationer af parametre og input skal resultere i enkel adfærd. "
Arbejdet trækker fra feltet algoritmisk informationsteori (AIT), som omhandler forbindelserne mellem datalogi og informationsteori. Et vigtigt resultat af AIT er kodningssætningen. Ifølge denne sætning, når en universel Turing -maskine (en abstrakt computerenhed, der kan beregne enhver funktion) får et tilfældigt input, simple output har en eksponentielt større sandsynlighed for at blive genereret end komplekse output. Som forskerne forklarer, dette resultat er helt i modstrid med den naive forventning om, at alle output er lige sandsynlige.
På trods af disse spændende fund, hidtil er kodningssætningen sjældent blevet anvendt på nogen systemer i den virkelige verden. Dette skyldes, at sætningen kun er formuleret på en meget abstrakt måde, og en af dens nøglekomponenter - en kompleksitetsmåling kaldet Kolmogorov -kompleksiteten - er uberegnelig.
"Kodningssætningen til Solomonoff og Levin er et bemærkelsesværdigt resultat, der virkelig burde være meget bredere kendt, "Sagde Louis." Det forudsiger, at output med lav kompleksitet eksponentielt er mere tilbøjelige til at blive genereret af en universel Turing-maskine (UTM), end output med høj kompleksitet er. Da alt, der kan beregnes, kan beregnes på en UTM, det er en ret fantastisk forudsigelse!
"Imidlertid, kodningssætningen er forblevet uklar, fordi UTM'er er ret abstrakte, fordi det kun kan bevises at holde i den asymptotiske grænse for store kompleksiteter, og fordi Kolmogorov -målingen, der bruges til at bestemme kompleksiteten, grundlæggende er uforholdelig. Vores arbejde omgår disse problemer ved hjælp af en lidt svagere version af kodningssætningen, der er meget lettere at anvende. "
I det nye, svagere version af kodningssætningen, forskerne erstattede Kolmogorov-kompleksiteten med en tilnærmelseskompleksitet, som kan beregnes, samtidig med at den eksponentielle præference for enkelhed bevares. Den svagere kodningssætning kan let anvendes til at forudsige praktiske systemer.
"Vi bruger sproget i input-output-kort, hvilket kan lyde ret abstrakt, " sagde Louis. "Men, mange systemer, der studeres inden for videnskab og teknik, konverterer en form for input til en form for output via en algoritme. For eksempel, informationen kodet i en organismes DNA (dens genotype) kan ses som input, mens organismens karakteristika og adfærd (dens fænotype) kunne ses som output. I et sæt differentialligninger, input er parametrene for ligningerne, og output er løsningen på disse ligninger, givet nogle randbetingelser.
"Vi argumenterer for, at hvis du tilfældigt valgte inputparametre, så er sådanne systemer eksponentielt mere tilbøjelige til at producere simple output over komplekse output. Da denne forudsigelse gælder for en lang række kort, vi gør en bred påstand. Men det er en af dens styrker. Vores afledning kræver ikke at vide meget om, hvordan det pågældende kort (eller algoritmen) i virkeligheden fungerer.
"Så den vigtigste betydning af vores arbejde er, at vores svagere version af kodningssætningen omtrent opretholder den eksponentielle bias mod enkelheden af det originale kodningssætning, men er meget nemmere at anvende i praksis."
En konsekvens af resultaterne er, at det er muligt at forudsige sandsynligheden for et bestemt resultat baseret på dets kompleksitet. Selvom et enkelt output eksponentielt er mere tilbøjeligt til at fremstå end et komplekst output, forskerne bemærker, at dette ikke nødvendigvis betyder, at simple output er mere tilbøjelige til at forekomme end komplekse output generelt, da der generelt kan være mange mere komplekse output end simple.
For at illustrere nogle få anvendelser, forskerne brugte den modificerede kodningssætning til at analysere systemer af RNA -sekvenser, døgnrytme, og finansielle markeder, og viste, at alle disse systemer udviser enkelhedsforskydningen. I fremtiden, de planlægger også at anvende resultaterne på computeralgoritmer, biologisk evolution, og kaotiske systemer. Imidlertid, for en mere intuitiv forklaring på, hvad enkelhedsforskydning betyder, forskerne beskriver et scenario, der involverer vores primater slægtninge:
"Overvej det velkendte problem med aber, der skriver på en skrivemaskine, "Sagde Louis." Hvis aberne skriver på en virkelig tilfældig måde, og skrivemaskinen har N nøgler, derefter sandsynligheden for at få en bestemt længdesekvens k er bare 1/ N k , da der er en 1/ N chance for at få det rigtige tastetryk ved hver af k trin. Således hver sekvens af længde k er lige så sandsynligt eller usandsynligt.
"Tænk nu på det tilfælde, hvor aberne skriver ind i et computerprogram. De kan så ved et uheld skrive et kort program, der genererer et langt output. F.eks. der er en kode på 133 tegn i programmeringssproget C, der korrekt genererer de første 15, 000 cifre på π. Så i stedet for 1/ N 15, 000 , hvilket er sandsynligheden for, at aber får det rigtige på en skrivemaskine, oddsene er meget lavere, kun 1/ N 133 , at aberne genererer π på computeren.
Det viser sig, at de fleste numre ikke har korte programmer, der genererer dem, så det bedste, aberne på computeren kan gøre for disse tal, er at skrive et program ud som 'udskriv nummer, 'hvilket er tæt på sandsynligheden for, at de under alle omstændigheder ville få det rigtigt på en skrivemaskine. Men for simple output, sandsynligheden er meget højere end for skrivemaskinen. Per definition, simple output defineres som dem, der har korte programmer, der beskriver dem, og komplekse output er dem, der kun kan beskrives ved lange programmer. Så π er, Per definition, et tal med lav kompleksitet, og derfor er det meget mere sandsynligt, at det genereres ved, at aber skriver ind i et computerprogram end mange andre tal, der ikke er enkle.
"Hvad kodningssætningen gør er at gøre denne intuitive historie kvantitativ. Det er mere sandsynligt, at korte programmer bliver indtastet tilfældigt, og siden sandsynligheder for længde k programmer skaleres også som 1/ N k , simple output er eksponentielt meget mere tilbøjelige til at blive vist end komplekse. Vores bidrag er at demonstrere, hvordan man nemt kan beregne den eksponentielle sammenhæng mellem sandsynlighed og kompleksitet for mange praktiske systemer. Det gode er, at du ikke behøver at vide meget om kortet (eller tilsvarende algoritmen) for at finde ud af, om et output sandsynligvis vil blive vist eller ej. Til en god første tilnærmelse, jo mere komprimerbar en output er, jo mere sandsynligt er det, at det vises ved tilfældige input. "
© 2018 Phys.org
 Varme artikler
Varme artikler
-
 Smede nye veje inden for partikelfysikKredit:vchal, Shutterstock Alt, hvad vi ser omkring os, består af elementarpartikler, materiens byggesten. Vi ved, at protoner og neutroner består af partikler kaldet kvarker, og at elektroner er
Smede nye veje inden for partikelfysikKredit:vchal, Shutterstock Alt, hvad vi ser omkring os, består af elementarpartikler, materiens byggesten. Vi ved, at protoner og neutroner består af partikler kaldet kvarker, og at elektroner er -
 Temperatur, fugtighed, vind forudsiger anden pandemibølgeOverførselshastigheden af coronavirus varierer på den nordlige og sydlige halvkugle afhængigt af årstiden, peger på en vejrafhængighed. Kredit:Talib Dbouk og Dimitris Drikakis, Universitetet i Nicos
Temperatur, fugtighed, vind forudsiger anden pandemibølgeOverførselshastigheden af coronavirus varierer på den nordlige og sydlige halvkugle afhængigt af årstiden, peger på en vejrafhængighed. Kredit:Talib Dbouk og Dimitris Drikakis, Universitetet i Nicos -
 Forskere udvikler superledende kvantekøleskabSuperleder -køleskabet ligner et konventionelt køleskab, ved at det flytter et materiale mellem varme og kolde reservoirer. Imidlertid, i stedet for et kølemiddel, der skifter fra en flydende tilstand
Forskere udvikler superledende kvantekøleskabSuperleder -køleskabet ligner et konventionelt køleskab, ved at det flytter et materiale mellem varme og kolde reservoirer. Imidlertid, i stedet for et kølemiddel, der skifter fra en flydende tilstand -
 Optisk generering af ultralyd via fotoakustisk effektDenne skematisk illustrerer, hvordan skræddersyede overfladeprofiler kan skabe mønstrede optisk genererede akustiske felter i 3D. Kredit:Brown et al. Begrænsninger af de piezoelektriske array -tek
Optisk generering af ultralyd via fotoakustisk effektDenne skematisk illustrerer, hvordan skræddersyede overfladeprofiler kan skabe mønstrede optisk genererede akustiske felter i 3D. Kredit:Brown et al. Begrænsninger af de piezoelektriske array -tek
- Forskergruppen finder tegn på kobling mellem stof og stof
- Undersøgelse viser, at IPCC undersælger klimaændringer
- Arkæologer finder intakt ceremoniel vogn nær Pompeji
- NASA -satellitter ser den tropiske storm Muifa i det nordvestlige Stillehav
- Eksempler på konkurrence mellem organismer af de samme arter
- Gamle landbrugsaktiviteter forårsagede varige miljøændringer