


Tidlige bestræbelser på vejen til pålidelig kvantemaskinlæring
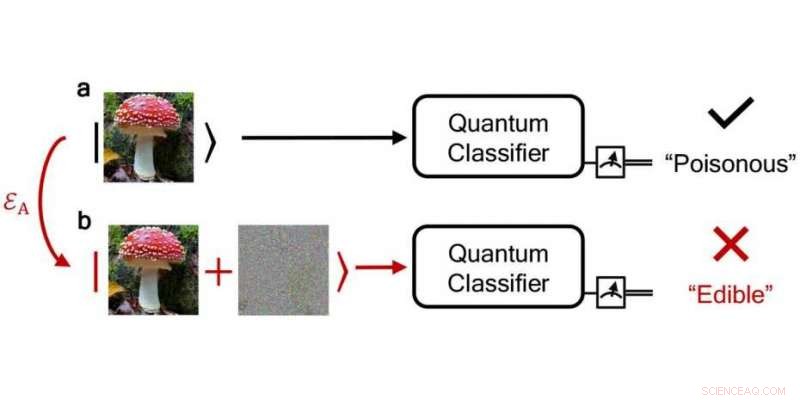
En pålidelig kvanteklassificeringsalgoritme klassificerer korrekt en giftig svamp som "giftig", mens en støjende, forstyrret klassificerer man det fejlagtigt som "spiselig". Kredit:npj Quantum Information / DS3Lab ETH Zürich
Enhver, der samler svampe, ved, at det er bedre at holde de giftige og de ikke-giftige fra hinanden. I sådanne "klassificeringsproblemer, "som kræver at adskille bestemte objekter fra hinanden og tildele de objekter, vi leder efter, til bestemte klasser ved hjælp af egenskaber, computere giver allerede nyttig support.
Intelligente maskinlæringsmetoder kan genkende mønstre eller objekter og automatisk plukke dem ud af datasæt. For eksempel, de kunne udvælge de billeder fra en fotodatabase, der viser ikke-giftige svampe. Især med meget store og komplekse datasæt, maskinlæring kan levere værdifulde resultater, som mennesker ikke ville være i stand til at bestemme uden megen tid og indsats. Imidlertid, til visse beregningsopgaver, selv de hurtigste computere, der er tilgængelige i dag, når deres grænser. Det er her det store løfte om kvantecomputere kommer i spil – en dag, de kunne udføre superhurtige beregninger, som klassiske computere ikke kan løse i en nyttig periode.
Årsagen til denne "kvanteoverherredømme" ligger i fysikken:Kvantecomputere beregner og behandler information ved at udnytte visse tilstande og interaktioner, der forekommer inden i atomer eller molekyler eller mellem elementarpartikler.
Det faktum, at kvantetilstande kan overlejre og sammenfiltre, skaber et grundlag, der giver kvantecomputere adgang til et fundamentalt rigere sæt af behandlingslogik. For eksempel, i modsætning til klassiske computere, kvantecomputere beregner ikke med binære koder eller bits, som kun behandler oplysninger som 0 eller 1, men med kvantebits eller qubits, som svarer til partiklernes kvantetilstande. Den afgørende forskel er, at qubits ikke kun kan realisere én tilstand – 0 eller 1 – pr. beregningstrin, men også en superposition af begge. Disse mere generelle metoder til informationsbehandling giver igen mulighed for en drastisk beregningsmæssig fremskyndelse af visse problemer.
Oversætter klassisk visdom til kvanteområdet
Disse hastighedsfordele ved kvanteberegning er også en mulighed for maskinlæringsapplikationer – når alt kommer til alt, kvantecomputere kunne beregne de enorme mængder data, som maskinlæringsmetoder har brug for for at forbedre nøjagtigheden af deres resultater meget hurtigere end klassiske computere.
Imidlertid, at virkelig udnytte potentialet ved kvanteberegning, det er nødvendigt at tilpasse klassiske maskinlæringsmetoder til kvantecomputeres særegenheder. For eksempel, algoritmer, dvs. de matematiske regler, der beskriver, hvordan en klassisk computer løser et bestemt problem, skal formuleres anderledes for kvantecomputere. At udvikle velfungerende kvantealgoritmer til maskinlæring er ikke helt trivielt, fordi der stadig er et par forhindringer at overvinde undervejs.
På den ene side, dette skyldes kvantehardwaren. Hos ETH Zürich, forskere har i øjeblikket kvantecomputere, der arbejder med op til 17 qubits (se "ETH Zürich og PSI fandt Quantum Computing Hub" af 3. maj 2021). Imidlertid, hvis kvantecomputere en dag skal realisere deres fulde potentiale, de har muligvis brug for tusinder til hundredtusinder af qubits.
Kvantestøj og uundgåeligheden af fejl
En udfordring, som kvantecomputere står over for, vedrører deres sårbarhed over for fejl. Dagens kvantecomputere opererer med et meget højt støjniveau, da fejl eller forstyrrelser er kendt i fagjargon. For American Physical Society, denne støj er "den største hindring for at opskalere kvantecomputere." Der findes ikke en samlet løsning til både at rette og afhjælpe fejl. Der er endnu ikke fundet nogen måde at producere fejlfri kvantehardware, og kvantecomputere med 50 til 100 qubits er for små til at implementere korrektionssoftware eller algoritmer.
I et vist omfang, fejl i kvanteberegning er i princippet uundgåelige, fordi de kvantetilstande, som de konkrete beregningstrin er baseret på, kun kan skelnes og kvantificeres med sandsynligheder. Hvad kan opnås, på den anden side, er procedurer, der begrænser omfanget af støj og forstyrrelser i en sådan grad, at beregningerne alligevel giver pålidelige resultater. Dataloger omtaler en pålideligt fungerende beregningsmetode som "robust, "og i denne sammenhæng, også tale om den nødvendige "fejltolerance".
Dette er, hvad forskningsgruppen ledet af Ce Zhang, ETH datalogi professor og medlem af ETH AI Center, har for nylig udforsket, på en eller anden måde "ved et uheld" under et forsøg på at ræsonnere om robustheden af klassiske distributioner med det formål at bygge bedre maskinlæringssystemer og platforme. Sammen med professor Nana Liu fra Shanghai Jiao Tong University og med professor Bo Li fra University of Illinois i Urbana, de har udviklet en ny tilgang, der beviser robusthedsbetingelserne for visse kvantebaserede maskinlæringsmodeller, hvor kvanteberegningen garanteres at være pålidelig og resultatet er korrekt. Forskerne har offentliggjort deres tilgang, som er en af de første af sin slags, i det videnskabelige tidsskrift npj Kvanteinformation .
Beskyttelse mod fejl og hackere
"Da vi indså, at kvantealgoritmer, ligesom klassiske algoritmer, er tilbøjelige til fejl og forstyrrelser, vi spurgte os selv, hvordan vi kan estimere disse kilder til fejl og forstyrrelser for visse maskinlæringsopgaver, og hvordan vi kan garantere robustheden og pålideligheden af den valgte metode, " siger Zhikuan Zhao, en postdoc i Ce Zhangs gruppe. "Hvis vi ved det, vi kan stole på beregningsresultaterne, selvom de larmer. "
Forskerne undersøgte dette spørgsmål ved at bruge kvanteklassifikationsalgoritmer som et eksempel - trods alt, fejl i klassificeringsopgaver er vanskelige, fordi de kan påvirke den virkelige verden, for eksempel hvis giftige svampe blev klassificeret som ikke-giftige. Måske vigtigst af alt, ved hjælp af teorien om kvantehypotesetest - inspireret af andre forskeres seneste arbejde med at anvende hypotesetest i de klassiske omgivelser - som gør det muligt at skelne mellem kvantetilstande, ETH-forskerne bestemte en tærskel, over hvilken tildelingerne af kvanteklassificeringsalgoritmen garanteres at være korrekte og dens forudsigelser robuste.
Med deres robusthedsmetode, forskerne kan endda kontrollere, om klassificeringen af en fejlagtig, støjende input giver samme resultat som en ren, støjfri input. Ud fra deres resultater, forskerne har også udviklet en beskyttelsesordning, der kan bruges til at specificere fejltolerancen for en beregning, uanset om en fejl har en naturlig årsag eller er resultatet af manipulation fra et hackingangreb. Deres robusthedskoncept fungerer til både hackingangreb og naturlige fejl.
"Metoden kan også anvendes på en bredere klasse af kvantealgoritmer, " siger Maurice Weber, en ph.d.-studerende med Ce Zhang og den første forfatter til publikationen. Da virkningen af fejl i kvanteberegning stiger, efterhånden som systemstørrelsen stiger, han og Zhao forsker nu i dette problem. "Vi er optimistiske over, at vores robusthedsforhold vil vise sig nyttige, for eksempel, i forbindelse med kvantealgoritmer designet til bedre at forstå den elektroniske struktur af molekyler."
Sidste artikelDynamik af kontaktelektrificering
Næste artikelDemonstration af kvantekommunikation over optiske fibre over 600 km
 Varme artikler
Varme artikler
-
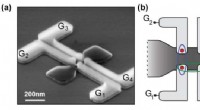 Vigtig milepæl i oprettelsen af en kvantecomputer(a) Scanningselektronbillede af en af de støberi-fremstillede kvantumpunkter. Fire kvantepunkter kan dannes i silicium (mørkegrå), ved hjælp af fire uafhængige styrekabler (lysegrå). Disse ledninger
Vigtig milepæl i oprettelsen af en kvantecomputer(a) Scanningselektronbillede af en af de støberi-fremstillede kvantumpunkter. Fire kvantepunkter kan dannes i silicium (mørkegrå), ved hjælp af fire uafhængige styrekabler (lysegrå). Disse ledninger -
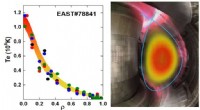 Kinesisk fusionsværktøj skubber forbi 100 millioner graderPlasmaelektrontemperaturen over 100 millioner grader opnået i 2018 på EAST. Kredit:EAST Team The Experimental Advanced Superconducting Tokamak (EAST), kaldet den kinesiske kunstige sol, opnåede e
Kinesisk fusionsværktøj skubber forbi 100 millioner graderPlasmaelektrontemperaturen over 100 millioner grader opnået i 2018 på EAST. Kredit:EAST Team The Experimental Advanced Superconducting Tokamak (EAST), kaldet den kinesiske kunstige sol, opnåede e -
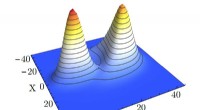 Kvantfaseovergang observeret for første gangSandsynlighedsfordeling, der viser lige stor sandsynlighed for, at hulrummet er gennemsigtigt og uigennemsigtigt på det kritiske punkt. Kredit:J. Fink En gruppe forskere ledet af Johannes Fink fra
Kvantfaseovergang observeret for første gangSandsynlighedsfordeling, der viser lige stor sandsynlighed for, at hulrummet er gennemsigtigt og uigennemsigtigt på det kritiske punkt. Kredit:J. Fink En gruppe forskere ledet af Johannes Fink fra -
 Forskere skaber bedre lysfangende enhederEn abstrakt skildring af den optiske resonators ni unikke topologiske ladninger. De separate afgifter er i stand til at fusionere sammen, beslægtet med hvordan bølger i havet kan styrte sammen og ente
Forskere skaber bedre lysfangende enhederEn abstrakt skildring af den optiske resonators ni unikke topologiske ladninger. De separate afgifter er i stand til at fusionere sammen, beslægtet med hvordan bølger i havet kan styrte sammen og ente
- Forskere finder en sammenhæng mellem patogenhistorie og graden af moralsk vitalisme
- NASAs InSight -mission opdager sit første skælv
- Hollandsk domstol siger, at Ryanair -pilotstrejke kan fortsætte
- Højfølsomme mikrosensorer i horisonten
- Hvad er kulstoffilmfossiler?
- Forskere giver indsigt i letvægtsmateriale, der udvider sig med varme