


Deep learning -teknikker lærer neurale modeller at spille retrosyntese
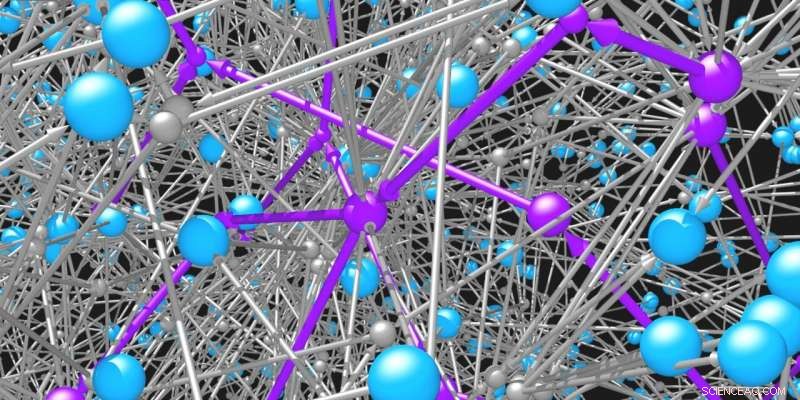
Molekyler (blå kugler) er forbundet med hinanden ved reaktionerne (grå kugler og pile), som de deltager i. Netværket af mulige organiske molekyler og reaktioner er umuligt stort. Intelligente søgealgoritmer er nødvendige for at identificere mulige veje (lilla) til syntetisering af ønskede molekyler. Kredit:Mikolaj Kowalik &Kyle Bishop/Columbia Engineering
Forskere, fra biokemikere til materialeforskere, har længe stolet på den rige variation af organiske molekyler for at løse presserende udfordringer. Nogle molekyler kan være nyttige til behandling af sygdomme, andre til belysning af vores digitale displays, endnu andre til pigmenter, maling, og plast. De unikke egenskaber ved hvert molekyle bestemmes af dets struktur - det vil sige, ved forbindelsen mellem dets bestanddele. Når først en lovende struktur er identificeret, der er stadig den vanskelige opgave at lave det målrettede molekyle gennem en række kemiske reaktioner. Men hvilke?
Organiske kemikere arbejder generelt baglæns fra målmolekylet til udgangsmaterialerne ved hjælp af en proces kaldet retrosyntetisk analyse. Under denne proces, kemikeren står over for en række komplekse og indbyrdes forbundne beslutninger. For eksempel, af titusinder af forskellige kemiske reaktioner, hvilken skal du vælge for at oprette målmolekylet? Når den beslutning er taget, du kan finde dig selv med flere reaktantmolekyler, der er nødvendige for reaktionen. Hvis disse molekyler ikke er tilgængelige til køb, hvordan vælger du så de passende reaktioner for at producere dem? Intelligent at vælge, hvad de skal gøre på hvert trin i denne proces, er afgørende for at navigere i det store antal mulige veje.
Forskere ved Columbia Engineering har udviklet en ny teknik baseret på forstærkningslæring, der træner en neural netværksmodel til korrekt at vælge den "bedste" reaktion på hvert trin i den retrosyntetiske proces. Denne form for AI danner en ramme for forskere til at designe kemiske synteser, der optimerer brugerspecificerede mål, f.eks. Synteseomkostninger, sikkerhed, og bæredygtighed. Den nye tilgang, udgivet 31. maj af ACS Central Science , er mere succesfuld (med ~ 60%) end eksisterende strategier til løsning af dette udfordrende søgeproblem.
"Forstærkningslæring har skabt computerafspillere, der er meget bedre end mennesker til at spille komplekse videospil. Måske er retrosyntese ikke anderledes! Denne undersøgelse giver os håb om, at forstærkningslæringsalgoritmer måske en dag er bedre end menneskelige spillere i 'spillet' retrosyntese, "siger Alán Aspuru-Guzik, professor i kemi og datalogi ved University of Toronto, der ikke var involveret i undersøgelsen.
Holdet fremstillede udfordringen med retrosyntetisk planlægning som et spil som skak og Go, hvor det kombinatoriske antal mulige valg er astronomisk og værdien af hvert valg usikker, indtil synteseplanen er afsluttet og dens omkostninger evalueret. I modsætning til tidligere undersøgelser, der brugte heuristiske scoringsfunktioner - enkle tommelfingerregler - til at guide retrosyntetisk planlægning, denne nye undersøgelse brugte forstærkningslæringsteknikker til at foretage vurderinger baseret på den neurale models egen erfaring.
"Vi er de første til at anvende forstærkningslæring på problemet med retrosyntetisk analyse, "siger Kyle Bishop, lektor i kemiteknik. "Ud fra en tilstand af fuldstændig uvidenhed, hvor modellen absolut intet ved om strategi og anvender reaktioner tilfældigt, modellen kan øve og øve, indtil den finder en strategi, der overgår en menneskelig defineret heurist. "
I deres undersøgelse, Biskops hold fokuserede på at bruge antallet af reaktionstrin som måling af, hvad der udgør en "god" syntetisk vej. De fik deres forstærkningslæringsmodel til at skræddersy sin strategi med dette mål for øje. Ved hjælp af simuleret erfaring, teamet uddannede modellens neurale netværk til at estimere den forventede syntesepris eller værdi af et givet molekyle baseret på en repræsentation af dets molekylære struktur.
Teamet planlægger at udforske forskellige mål i fremtiden, for eksempel, træning af modellen til at minimere omkostninger frem for antallet af reaktioner, eller for at undgå molekyler, der kan være giftige. Forskerne forsøger også at reducere antallet af simuleringer, der kræves for, at modellen kan lære sin strategi, da uddannelsesprocessen var ret beregningsmæssigt dyr.
"Vi forventer, at vores retrosyntesespil snart vil følge skak og Go's vej, hvor selvlærte algoritmer konsekvent overgår menneskelige eksperter, "Biskop bemærker." Og vi glæder os over konkurrence. Som med skak-computerprogrammer, konkurrence er motoren til forbedringer i den nyeste teknik, og vi håber, at andre kan bygge videre på vores arbejde med at demonstrere endnu bedre præstationer. "
Undersøgelsen har titlen "Læring af retrosyntetisk planlægning gennem simuleret erfaring."
Sidste artikelNy polymer tackler PFAS -forurening
Næste artikelBorgerforskere designer helt nye proteiner
 Varme artikler
Varme artikler
-
 Madlavningskemi minus varme er lig med ny ikke-giftig klæbemiddelDet naturlige klæbemiddel skabt af muslinger for at klæbe til hinanden og undervandsoverflader har inspireret til en ny giftfri lim. Kredit:Jonathan Wilker/Purdue Det ser ud til, at kagerne, der e
Madlavningskemi minus varme er lig med ny ikke-giftig klæbemiddelDet naturlige klæbemiddel skabt af muslinger for at klæbe til hinanden og undervandsoverflader har inspireret til en ny giftfri lim. Kredit:Jonathan Wilker/Purdue Det ser ud til, at kagerne, der e -
 Trækker stikket på coronavirus kopimaskineAntiviralt lægemiddel remdesivir udgør hovedlinjen i FDA-godkendt terapeutisk forsvar mod COVID-19-virussen. Forskere ved University of North Texas bruger Frontera-supercomputeren til at modellere, hv
Trækker stikket på coronavirus kopimaskineAntiviralt lægemiddel remdesivir udgør hovedlinjen i FDA-godkendt terapeutisk forsvar mod COVID-19-virussen. Forskere ved University of North Texas bruger Frontera-supercomputeren til at modellere, hv -
 Oplyser vejen til superopløsningsbilleddannelse med forbedrede rhodaminfarvestofferForskere fra DUT og SUTD udviklede en ny klasse af kvaternære piperazin-substituerede rhodaminer med fremragende kvanteudbytter (Φ =0,93) og overlegen lysstyrke (ε × Φ =8,1 × 104 L·mol-1·cm-1), til bi
Oplyser vejen til superopløsningsbilleddannelse med forbedrede rhodaminfarvestofferForskere fra DUT og SUTD udviklede en ny klasse af kvaternære piperazin-substituerede rhodaminer med fremragende kvanteudbytter (Φ =0,93) og overlegen lysstyrke (ε × Φ =8,1 × 104 L·mol-1·cm-1), til bi -
 Undersøgelse kan hjælpe med at booste peptiddesignKredit:CC0 Public Domain Peptider, som er korte rækker af aminosyrer, spiller en afgørende rolle i sundhed og industri med en lang række medicinske anvendelser, herunder i antibiotika, anti-inflam
Undersøgelse kan hjælpe med at booste peptiddesignKredit:CC0 Public Domain Peptider, som er korte rækker af aminosyrer, spiller en afgørende rolle i sundhed og industri med en lang række medicinske anvendelser, herunder i antibiotika, anti-inflam
- Forskere bruger videospil til at låse op for nye niveauer af AI
- Nordlige majsbladskimmelgener identificeret i ny undersøgelse
- Hvilke slags eksperimenter udføres på den internationale rumstation?
- Oxygen Bleach Vs. Chlor Bleach
- Drage tilbage, da last når rumstationen
- Vestkysten jordskælvsadvarselssystem nu i drift, med grænser