


Brug af data mining til at give mening om klimaændringer

Kredit:Georgia Institute of Technology
Big data og data mining har givet flere gennembrud inden for områder som sundhedsinformatik, smarte byer og marketing. De samme teknikker, imidlertid, ikke har leveret konsekvente centrale fund for klimaændringer.
Der er et par grunde til. Den vigtigste er, at tidligere data mining arbejder inden for klimavidenskab, og især i analysen af klimatelekonnektioner, har støttet sig på metoder, der tilbyder temmelig forenklet "ja eller nej" svar.
"Det er ikke så enkelt i klimaet, "sagde Annalisa Bracco, en professor i Georgia Tech's School of Earth and Atmospheric Sciences. "Selv svage forbindelser mellem meget forskellige regioner på kloden kan skyldes et underliggende fysisk fænomen. Indførelse af tærskler og smide svage forbindelser ville standse alt. I stedet vil en klimaforskers ekspertise er det centrale skridt til at finde fællestræk på tværs af meget forskellige datasæt eller felter for at undersøge, hvor robuste de er. "
Og med millioner af datapunkter spredt rundt om i verden, Bracco sagde, at de nuværende modeller stoler for meget på menneskelig ekspertise til at give mening om output. Hun og hendes kolleger ønskede at udvikle en metode, der mere afhænger af faktiske data frem for en forskers fortolkning.
Derfor har Georgia Tech-teamet udviklet en ny måde at minedata fra klimadatasæt, der er mere selvstændig end traditionelle værktøjer. Metoden frembringer fællestræk i datasæt uden så meget ekspertise fra brugeren, tillader forskere at stole på dataene og få mere robuste - og gennemsigtige - resultater.
Metoden er open source og i øjeblikket tilgængelig for forskere rundt om i verden. Georgia Tech -forskerne bruger det allerede til at undersøge havoverfladetemperatur og skyfeldata, to aspekter, der har stor indflydelse på planetens klima.
"Der er så mange faktorer - skydata, aerosoler og vindfelter, for eksempel - der interagerer for at generere klima og drive klimaforandringer, sagde Athanasios Nenes, en anden videnskabelig kollegiprofessor om projektet. "Afhængigt af det modelaspekt, du fokuserer på, de kan gengive klimafunktioner effektivt - eller slet ikke. Nogle gange er det meget svært at vide, om en model virkelig er bedre end en anden, eller om den forudsiger klima af de rigtige grunde. "
Nenes siger, at Georgia Tech -metoden ser på alt på en mere robust måde, bryde den flaskehals, der er typisk for andre modelevaluerings- og analysealgoritmer. Metoden, han siger, kan bruges til observationer, og forskere behøver ikke at vide noget om computerkode og modeller.
"Metoden reducerer kompleksiteten af millioner af datapunkter til det helt essentielle - nogle gange så få som 10 regioner, der interagerer med hinanden, "sagde Nenes." Vi skal have værktøjer, der reducerer kompleksiteten af modeloutput for at forstå dem bedre og evaluere, om de giver de korrekte resultater af de rigtige grunde. "
For at udvikle metodikken, klimaforskerne indgik et samarbejde med Constantine Dovrolis og andre datavidenskabsfolk i Georgia Tech's College of Computing. Dovrolis sagde, at det er spændende at anvende algoritmisk og beregningsmæssig tænkning i problemer, der påvirker alle på store måder, såsom global opvarmning. "
"Klimavidenskab er en 'datatung' disciplin med mange intellektuelt interessante spørgsmål, der kan drage fordel af beregningsmodellering og forudsigelse, "sagde Dovrolis, en professor på School of Computer Science, "Tværfaglige samarbejde er i første omgang udfordrende-hver disciplin har sit eget sprog, foretrukne tilgang og forskningskultur - men de kan i sidste ende være ganske givende. "
Papiret, "Fremme af klima videnskab med viden-opdagelse gennem data mining, "udgives i Klima og atmosfærisk videnskab .
Sidste artikelRodfund kan føre til afgrøder, der har brug for mindre gødning
Næste artikelKina siger, at luftkvaliteten er forbedret i 2017
 Varme artikler
Varme artikler
-
 Undersøgelse viser, at markedsbaserede strategier for økosystembevarelse er stigendeI Malaysia, embedsmænd arbejdede med private parter for at genoprette og vedligeholde regnskove, hjemsted for en af verdens højeste koncentrationer af orangutanger. Kredit:Mokhamad Edliadi/CIFOR
Undersøgelse viser, at markedsbaserede strategier for økosystembevarelse er stigendeI Malaysia, embedsmænd arbejdede med private parter for at genoprette og vedligeholde regnskove, hjemsted for en af verdens højeste koncentrationer af orangutanger. Kredit:Mokhamad Edliadi/CIFOR -
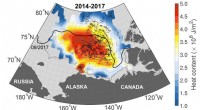 Arkiveret varme er nået dybt ind i det arktiske indre, siger forskereVarme, der i øjeblikket er fanget under overfladen, har potentiale til at smelte hele den arktiske regions havis, hvis den når overfladen, ifølge forskere. Kredit:Yale University Arktisk havis er
Arkiveret varme er nået dybt ind i det arktiske indre, siger forskereVarme, der i øjeblikket er fanget under overfladen, har potentiale til at smelte hele den arktiske regions havis, hvis den når overfladen, ifølge forskere. Kredit:Yale University Arktisk havis er -
 Unikt sensornetværk til måling af drivhusgasserMåleanordning for MUCCnet-sensornetværket oprettet af prof. Jia Chen, formand for miljømåling og modellering, ved TUM Department of Electrical and Computer Engineering ved det tekniske universitet i M
Unikt sensornetværk til måling af drivhusgasserMåleanordning for MUCCnet-sensornetværket oprettet af prof. Jia Chen, formand for miljømåling og modellering, ved TUM Department of Electrical and Computer Engineering ved det tekniske universitet i M -
 CO2 -mangel - hvorfor kan vi ikke bare trække kuldioxid ud af luften?Kredit:Shutterstock Flere mennesker end nogensinde er helt klar over, at stigende niveauer af kuldioxid (CO₂) i atmosfæren fremskynder klimaændringer og global opvarmning. Og alligevel har fødevar
CO2 -mangel - hvorfor kan vi ikke bare trække kuldioxid ud af luften?Kredit:Shutterstock Flere mennesker end nogensinde er helt klar over, at stigende niveauer af kuldioxid (CO₂) i atmosfæren fremskynder klimaændringer og global opvarmning. Og alligevel har fødevar