


Kunstig intelligens klassificerer supernovaeksplosioner med hidtil uset nøjagtighed

Cassiopeia A, eller Cas A, er en supernova-rest placeret 10, 000 lysår væk i stjernebilledet Cassiopeia, og er en rest af en engang så massiv stjerne, der døde i en voldsom eksplosion for omkring 340 år siden. Dette billede har infrarøde lag, synlig, og røntgendata for at afsløre filamentære strukturer af støv og gas. Cas A er blandt de 10 procent af supernovaer, som videnskabsmænd er i stand til at studere nærmere. CfAs nye maskinlæringsprojekt vil hjælpe med at klassificere tusinder, og til sidst millioner, af potentielt interessante supernovaer, som ellers aldrig ville blive undersøgt. Kredit:NASA/JPL-Caltech/STScI/CXC/SAO
Kunstig intelligens klassificerer virkelige supernovaeksplosioner uden den traditionelle brug af spektre, takket være et hold af astronomer ved Center for Astrofysik | Harvard og Smithsonian. De komplette datasæt og resulterende klassifikationer er offentligt tilgængelige til åben brug.
Ved at træne en maskinlæringsmodel til at kategorisere supernovaer baseret på deres synlige egenskaber, astronomerne var i stand til at klassificere rigtige data fra Pan-STARRS1 Medium Deep Survey for 2, 315 supernovaer med en nøjagtighed på 82 procent uden brug af spektre.
Astronomerne udviklede et softwareprogram, der klassificerer forskellige typer supernovaer baseret på deres lyskurver, eller hvordan deres lysstyrke ændrer sig over tid. "Vi har cirka 2, 500 supernovaer med lyskurver fra Pan-STARRS1 Medium Deep Survey, og af dem, 500 supernovaer med spektre, der kan bruges til klassificering, " sagde Griffin Hosseinzadeh, en postdoc-forsker ved CfA og hovedforfatter på det første af to artikler udgivet i The Astrophysical Journal . "Vi trænede klassificereren ved at bruge de 500 supernovaer til at klassificere de resterende supernovaer, hvor vi ikke var i stand til at observere spektret."
Edo Berger, en astronom ved CfA forklarede, at ved at bede den kunstige intelligens om at besvare specifikke spørgsmål, resultaterne bliver mere og mere præcise. "Maskinlæringen leder efter en sammenhæng med de originale 500 spektroskopiske etiketter. Vi beder den om at sammenligne supernovaerne i forskellige kategorier:farve, udviklingshastighed, eller lysstyrke. Ved at fodre den med ægte eksisterende viden, det fører til den højeste nøjagtighed, mellem 80 og 90 procent."
Selvom dette ikke er det første maskinlæringsprojekt til klassificering af supernovaer, det er første gang, at astronomer har haft adgang til et reelt datasæt, der er stort nok til at træne en kunstig intelligens-baseret supernovaklassifikator, gør det muligt at skabe maskinlæringsalgoritmer uden brug af simuleringer.
"Hvis du laver en simuleret lyskurve, det betyder, at du laver en antagelse om, hvordan supernovaer vil se ud, og din klassificering vil så også lære disse antagelser, " sagde Hosseinzadeh. "Naturen vil altid give nogle yderligere komplikationer, som du ikke har taget højde for, hvilket betyder, at din klassificering ikke vil klare sig så godt på rigtige data, som den gjorde på simulerede data. Fordi vi brugte rigtige data til at træne vores klassifikatorer, det betyder, at vores målte nøjagtighed sandsynligvis er mere repræsentativ for, hvordan vores klassifikatorer vil præstere på andre undersøgelser." Når klassificereren kategoriserer supernovaerne, sagde Berger, "Vi vil være i stand til at studere dem både i retrospekt og i realtid for at udvælge de mest interessante begivenheder til detaljeret opfølgning. Vi vil bruge algoritmen til at hjælpe os med at udvælge nålene og også til at se på høstakken."
Projektet har ikke kun konsekvenser for arkivdata, men også for data, der vil blive indsamlet af fremtidige teleskoper. Vera C. Rubin Observatory forventes at gå online i 2023, og vil føre til opdagelsen af millioner af nye supernovaer hvert år. Dette giver både muligheder og udfordringer for astrofysikere, hvor begrænset teleskoptid fører til begrænsede spektrale klassifikationer.
"Når Rubin Observatory går online, vil det øge vores opdagelsesrate af supernovaer med 100 gange, men vores spektroskopiske ressourcer vil ikke stige, " sagde Ashley Villar, Simons Junior Fellow ved Columbia University og hovedforfatter på den anden af de to artikler, tilføjer, at mens omkring 10, 000 supernovaer opdages i øjeblikket hvert år, videnskabsmænd tager kun spektre af omkring 10 procent af disse objekter. "Hvis dette holder, det betyder, at kun 0,1 procent af supernovaer opdaget af Rubin Observatory hvert år vil få en spektroskopisk etiket. De resterende 99,9 procent af data vil være ubrugelige uden metoder som vores."
I modsætning til tidligere bestræbelser, hvor datasæt og klassifikationer kun har været tilgængelige for et begrænset antal astronomer, datasættene fra den nye maskinlæringsalgoritme vil blive gjort offentligt tilgængelige. Astronomerne har skabt letanvendelige, tilgængelig software, og frigav også alle data fra Pan-STARRS1 Medium Deep Survey sammen med de nye klassifikationer til brug i andre projekter. Hosseinzadeh sagde, "Det var virkelig vigtigt for os, at disse projekter var nyttige for hele supernovasamfundet, ikke kun for vores gruppe. Der er så mange projekter, der kan udføres med disse data, at vi aldrig kunne gøre dem alle selv." Berger tilføjede, "Disse projekter er åbne data for åben videnskab."
Sidste artikelLængste intergalaktiske gasfilament opdaget
Næste artikelKan hvide dværge hjælpe med at løse det kosmologiske lithiumproblem?
 Varme artikler
Varme artikler
-
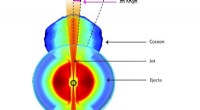 Radioobservationer bekræfter en superhurtig stråle af materiale fra neutronstjernefusionEftervirkninger af fusionen af to neutronstjerner. Ejecta fra en indledende eksplosion dannede en skal omkring det sorte hul dannet fra fusionen. En stråle af materiale drevet frem fra en skive, der
Radioobservationer bekræfter en superhurtig stråle af materiale fra neutronstjernefusionEftervirkninger af fusionen af to neutronstjerner. Ejecta fra en indledende eksplosion dannede en skal omkring det sorte hul dannet fra fusionen. En stråle af materiale drevet frem fra en skive, der -
 Astrofysikere simulerer mikroskopiske klynger fra Big BangResultaterne af simuleringen viser væksten af bittesmå, ekstremt tætte strukturer meget hurtigt efter inflationsfasen af det meget tidlige univers. Mellem start- og sluttilstanden i simuleringen (
Astrofysikere simulerer mikroskopiske klynger fra Big BangResultaterne af simuleringen viser væksten af bittesmå, ekstremt tætte strukturer meget hurtigt efter inflationsfasen af det meget tidlige univers. Mellem start- og sluttilstanden i simuleringen ( -
 En del af universets manglende stof fundetObservation af en del af universet takket være MUSE. Til venstre:Afgrænsning af kvasaren og galaksen studeret her, Gal1. Center:Tåge bestående af magnesium repræsenteret med en størrelsesskala. Til hø
En del af universets manglende stof fundetObservation af en del af universet takket være MUSE. Til venstre:Afgrænsning af kvasaren og galaksen studeret her, Gal1. Center:Tåge bestående af magnesium repræsenteret med en størrelsesskala. Til hø -
 En ny søgning efter ekstrasolare planeter fra Arecibo ObservatoryKredit:Planetary Habitability Laboratory National Science Foundations Arecibo Observatory og Planetary Habitability Laboratory ved University of Puerto Rico i Arecibo sluttede sig til Red Dots-pro
En ny søgning efter ekstrasolare planeter fra Arecibo ObservatoryKredit:Planetary Habitability Laboratory National Science Foundations Arecibo Observatory og Planetary Habitability Laboratory ved University of Puerto Rico i Arecibo sluttede sig til Red Dots-pro
- Alibaba køber NetEases import e-handelsenhed for $ 2 mia
- Mod en bedre forudsigelse af soludbrud
- Nanotråde udviser kæmpe piezoelektricitet
- Gør virksomheder krisesikker
- Forbedret forståelse af banebrydende 2-D-teknik med flydende metal
- Hvorfor mennesker rundt om i verden frygter klimaændringer mere end amerikanere gør