


Undersøgelse afslører fejl i den populære genetiske metode
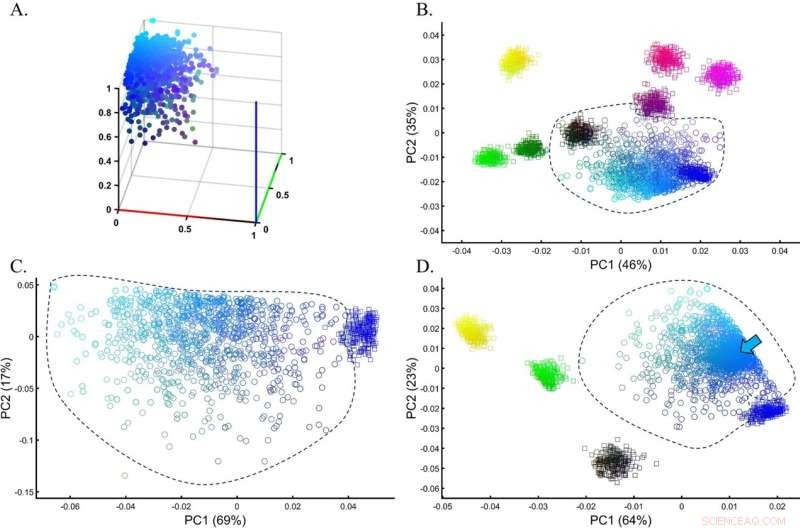
Evaluering af nøjagtigheden af PCA-klynger for en heterogen testpopulation i en simulering af en GWAS-indstilling. (A) Den sande fordeling af testcyanpopulationen (n = 1000). (B) PCA for testpopulationen med otte lige store (n = 250) prøver fra referencepopulationer. (C) PCA af testpopulationen med blå fra den tidligere analyse viser et minimalt overlap mellem kohorterne. (D) PCA for testpopulationen med fem lige store (n = 250) prøver fra referencepopulationer, inklusive cyan (markeret med en pil). Farver (B) fra top til bund og venstre mod højre inkluderer:Gul [1,1,0], lys rød [1,0,0.5], lilla [1,0,1], mørk lilla [0.5,0,0.5] ], Sort [0,0,0], mørkegrøn [0,0,5,0], Grøn [0,1,0] og blå [1,0,0]. Kredit:Scientific Reports (2022). DOI:10.1038/s41598-022-14395-4
Den mest almindelige analysemetode inden for populationsgenetik er dybt mangelfuld, viser en ny undersøgelse fra Lunds Universitet i Sverige. Dette kan have ført til forkerte resultater og misforståelser om etnicitet og genetiske forhold. Metoden er blevet brugt i hundredtusindvis af undersøgelser, der har påvirket resultater inden for medicinsk genetik og endda kommercielle herkomsttests. Undersøgelsen er publiceret i Scientific Reports .
Den hastighed, hvormed videnskabelige data kan indsamles, stiger eksponentielt, hvilket fører til massive og meget komplekse datasæt, kaldet "Big Data revolutionen." For at gøre disse data mere håndterbare bruger forskere statistiske metoder, der sigter mod at komprimere og forenkle dataene, mens de stadig beholder de fleste af nøgleoplysningerne. Den måske mest udbredte metode kaldes PCA (principal component analysis). Tænk analogt på PCA som en ovn med mel, sukker og æg som datainput. Ovnen kan altid gøre det samme, men resultatet, en kage, afhænger i høj grad af ingrediensernes forhold og hvordan de kombineres.
"Det forventes, at denne metode vil give korrekte resultater, fordi den er så hyppigt brugt. Men den er hverken en garanti for pålidelighed eller giver statistisk robuste konklusioner," siger Dr. Eran Elhaik, lektor i molekylær cellebiologi ved Lunds Universitet.
Ifølge Elhaik var metoden med til at skabe gamle opfattelser om race og etnicitet. Det spiller en rolle i fremstillingen af historiske fortællinger om, hvem og hvor folk kommer fra, ikke kun af det videnskabelige samfund, men også af kommercielle virksomheder. Et berømt eksempel er, da en fremtrædende amerikansk politiker tog en herkomsttest før præsidentkampagnen i 2020 for at støtte deres forfædres påstande. Et andet eksempel er misforståelsen af askenasiske jøder som en race eller en isoleret gruppe drevet af PCA-resultater.
"Denne undersøgelse viser, at disse resultater var upålidelige," siger Eran Elhaik.
PCA bruges på tværs af mange videnskabelige områder, men Elhaiks undersøgelse fokuserer på dets anvendelse i populationsgenetik, hvor eksplosionen i datasætstørrelser er særlig akut, hvilket er drevet af de reducerede omkostninger ved DNA-sekventering.
Området for palæogenomik, hvor vi ønsker at lære om gamle folk og individer såsom kobberalderens europæere, er stærkt afhængig af PCA. PCA bruges til at skabe et genetisk kort, der placerer den ukendte prøve sammen med kendte referenceprøver. Hidtil er de ukendte prøver blevet antaget at være relateret til den referencepopulation, de overlapper eller ligger tættest på på kortet.
Elhaik opdagede imidlertid, at den ukendte prøve kunne bringes til at ligge tæt på praktisk talt enhver referencepopulation blot ved at ændre antallet og typer af referenceprøverne, hvilket genererede praktisk talt uendelige historiske versioner, alle matematisk "korrekte", men kun én kan være biologisk korrekt .
I undersøgelsen har Elhaik undersøgt de tolv mest almindelige populationsgenetiske anvendelser af PCA. Han har brugt både simulerede og ægte genetiske data til at vise, hvor fleksible PCA-resultater kan være. Ifølge Elhaik betyder denne fleksibilitet, at konklusioner baseret på PCA ikke kan stoles på, da enhver ændring af referencen eller testprøverne vil give andre resultater.
Mellem 32.000 og 216.000 videnskabelige artikler i genetik alene har brugt PCA til at udforske og visualisere ligheder og forskelle mellem individer og populationer og baseret deres konklusioner på disse resultater.
"Jeg mener, at disse resultater skal revurderes," siger Elhaik.
Han håber, at det nye studie vil udvikle en bedre tilgang til at stille spørgsmålstegn ved resultater og dermed være med til at gøre videnskaben mere pålidelig. Han brugte en betydelig del af det sidste årti på at pionere sådanne metoder, såsom den geografiske befolkningsstruktur (GPS), til at forudsige biogeografi ud fra DNA, og Pairwise Matcher, som forbedrer case-control matches, der bruges i genetiske tests og lægemiddelforsøg.
"Teknikker, der tilbyder en sådan fleksibilitet tilskynder til dårlig videnskab og er særligt farlige i en verden, hvor der er et intenst pres for at publicere. Hvis en forsker kører PCA flere gange, vil fristelsen altid være at vælge det output, der giver den bedste historie," tilføjer Prof. William Amos, fra University of Cambridge, som ikke var involveret i undersøgelsen. + Udforsk yderligere
Forskere udvikler den første AI-baserede metode til at datere arkæologiske rester
 Varme artikler
Varme artikler
-
 Antibiotika-resistente infektioner hos kæledyrVeterinær klinisk medicin professor Dr. Jason Pieper, en veterinær hudlæge, ser patienter med antibiotika-resistente bakterieinfektioner næsten hver dag på jobbet. Kredit:L. Brian Stauffer Næsten
Antibiotika-resistente infektioner hos kæledyrVeterinær klinisk medicin professor Dr. Jason Pieper, en veterinær hudlæge, ser patienter med antibiotika-resistente bakterieinfektioner næsten hver dag på jobbet. Kredit:L. Brian Stauffer Næsten -
 Hvor finder respiration sted?Den kemiske reaktion kaldet respiration er afgørende for vækst, reparation og overlevelse af alle levende ting. Respiration sker i cellerne i planter, dyr og mennesker, hovedsageligt inden i mitokondr
Hvor finder respiration sted?Den kemiske reaktion kaldet respiration er afgørende for vækst, reparation og overlevelse af alle levende ting. Respiration sker i cellerne i planter, dyr og mennesker, hovedsageligt inden i mitokondr -
 Antallet af sneugle langt lavere end engang troedeI denne 14. dec. 2017-billede en sneugle stirrer, før den bliver sluppet ud langs kysten af Duxbury Beach i Duxbury, Mass. Uglen er en af 14 hidtil fanget denne vinter i Bostons Logan Lufthavn og
Antallet af sneugle langt lavere end engang troedeI denne 14. dec. 2017-billede en sneugle stirrer, før den bliver sluppet ud langs kysten af Duxbury Beach i Duxbury, Mass. Uglen er en af 14 hidtil fanget denne vinter i Bostons Logan Lufthavn og -
 Forsker rapporterer nøglekomponenter i honningbiens antivirale forsvarLaura Brutscher, som tog sin doktorgrad ved MSU i juli, fik publiceret sin afhandlingsforskning i tidsskriftet Scientific Reports i samme måned. Brutschers forskning handler om de mekanismer honningbi
Forsker rapporterer nøglekomponenter i honningbiens antivirale forsvarLaura Brutscher, som tog sin doktorgrad ved MSU i juli, fik publiceret sin afhandlingsforskning i tidsskriftet Scientific Reports i samme måned. Brutschers forskning handler om de mekanismer honningbi
- Robust fast katalysator giver høje udbytter af estere ved kontinuerlig strømning
- Social modstand fra bronzealdersamfund som reaktion på nye statssamfund på den iberiske halvø
- Hvad er urinstof?
- Tyngre stjerner eksploderer måske ikke som supernovaer, bare stille og roligt implodere i sorte hul…
- Kæmpe nedslag forårsagede forskel mellem månens halvkugler
- Nøgleprotein, der er relevant for virusinfektion og arvelig sygdom opdaget