


Sporing af en epidemi kræver computermodeller - men hvad nu hvis disse modeller er forkerte?
1. Datakvalitet og tilgængelighed :Nøjagtigheden af computermodeller afhænger i høj grad af kvaliteten og tilgængeligheden af data. Ufuldstændige, unøjagtige eller manglende data kan føre til forkerte forudsigelser. Dataindsamling i realtid under en epidemi kan være vanskelig, især i ressourcebegrænsede indstillinger, hvilket kan kompromittere modellens nøjagtighed.
2. Oversimplificering af virkeligheden :Computermodeller forenkler ofte komplekse scenarier i den virkelige verden for at gøre beregninger mulige. Disse forenklinger kan overse afgørende faktorer, der påvirker sygdomsspredning, såsom individuel adfærd, social dynamik og miljøforhold.
3. Usikkerhed i parameterestimater :Modeller kræver estimater for forskellige parametre, såsom transmissionshastighed, inkubationsperiode og restitutionstid. Disse estimater er ofte baseret på begrænsede observationer og kan ændres, efterhånden som nye oplysninger dukker op. Usikkerhed i disse parametre kan forplante sig gennem modellen og påvirke dens nøjagtighed.
4. Adfærdsændringer :Menneskelig adfærd kan have betydelig indflydelse på sygdomsoverførsel. For eksempel kan ændringer i rejsemønstre, foranstaltninger til social distancering og maskebrug påvirke forløbet af en epidemi. At fange disse adfærdsændringer nøjagtigt i en computermodel kan være udfordrende, hvilket fører til potentielle uoverensstemmelser mellem modelforudsigelser og observationer fra den virkelige verden.
5. Uforudsigelige hændelser :Epidemier kan blive påvirket af uforudsigelige begivenheder såsom naturkatastrofer, politiske ændringer eller folkesundhedsindgreb. Disse hændelser kan forstyrre sygdomsforløbet og gøre modeller, der ikke tager højde for dem, ugyldige.
6. Begrænsede historiske data for nye patogener :I tilfælde af nye patogener, såsom en ny virusstamme, kan der være begrænsede historiske data til rådighed til at træne og validere computermodeller. Uden tilstrækkelige data kan modeller producere upålidelige forudsigelser.
7. Modelkompleksitet vs. fortolkning :Det er vigtigt at finde en balance mellem modelkompleksitet og fortolkning. Komplekse modeller kan give mere detaljerede oplysninger, men kan være svære at forstå og kommunikere til politikere og offentligheden. Enklere modeller kan være lettere at fortolke, men kan mangle de nødvendige detaljer og nøjagtighed til effektiv beslutningstagning.
8. Modelvalidering og -kalibrering :Validering og kalibrering af computermodeller ved hjælp af data fra den virkelige verden er afgørende for at sikre deres pålidelighed. Kontinuerlig validering og kalibrering kan dog være udfordrende, især når data er knappe, eller når epidemien udvikler sig hurtigt.
9. Overtilpasning og generaliserbarhed :Modeller, der er skræddersyet til en specifik kontekst eller datasæt, generaliserer muligvis ikke godt til forskellige populationer eller miljøer. Overtilpasning til specifikke data kan føre til forudsigelser, der ikke er anvendelige i bredere situationer.
For at øge pålideligheden af computermodeller til epidemisporing er det vigtigt at bruge flere modeller, inkorporere ekspertviden, løbende opdatere data, validere og kalibrere modeller regelmæssigt og overveje de begrænsninger og usikkerheder, der er forbundet med modelforudsigelser. En kombination af modellering og observationer fra den virkelige verden er afgørende for effektiv epidemisk overvågning og respons.
 Varme artikler
Varme artikler
-
 Hvordan et vendt gen hjalp sommerfugle med at udvikle mimikFlere forskellige svalehale sommerfuglevariationer, der viser mimik og polymorfi, eller forskellige former af samme art. I centrum, en hun Papilio polytes der ikke efterligner en anden art. Kredit:M
Hvordan et vendt gen hjalp sommerfugle med at udvikle mimikFlere forskellige svalehale sommerfuglevariationer, der viser mimik og polymorfi, eller forskellige former af samme art. I centrum, en hun Papilio polytes der ikke efterligner en anden art. Kredit:M -
 Beyond AlphaFold:AI udmærker sig ved at skabe nye proteinerProteiner designet med et ultrahurtigt softwareværktøj kaldet ProteinMPNN var meget mere tilbøjelige til at folde op efter hensigten. Kredit:Ian Haydon, UW Medicine Institute for Protein Design I l
Beyond AlphaFold:AI udmærker sig ved at skabe nye proteinerProteiner designet med et ultrahurtigt softwareværktøj kaldet ProteinMPNN var meget mere tilbøjelige til at folde op efter hensigten. Kredit:Ian Haydon, UW Medicine Institute for Protein Design I l -
 Militser, krybskytter forårsager kaos på det centrale Afrikas dyreliv:monitorElefantbestanden er stabil eller stigende i det østlige og sydlige Afrika, men krybskytteri er fortsat højt i midten af kontinentet Sudans Janjaweed, Ugandas Lords Resistance Army og andre beryg
Militser, krybskytter forårsager kaos på det centrale Afrikas dyreliv:monitorElefantbestanden er stabil eller stigende i det østlige og sydlige Afrika, men krybskytteri er fortsat højt i midten af kontinentet Sudans Janjaweed, Ugandas Lords Resistance Army og andre beryg -
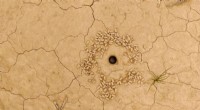 Hvordan parrer skovlus sig, når rovdyr lurer i nærheden? Rovdyrs indvirkning på mand-hun-parringIsopod hule. Kredit:Tali Aronsky Ørkenisopoder står måske ikke øverst på listen over mest indtagende dyr, men disse små (op til to centimeter lange) væsner, med deres segmenterede kroppe og syv par
Hvordan parrer skovlus sig, når rovdyr lurer i nærheden? Rovdyrs indvirkning på mand-hun-parringIsopod hule. Kredit:Tali Aronsky Ørkenisopoder står måske ikke øverst på listen over mest indtagende dyr, men disse små (op til to centimeter lange) væsner, med deres segmenterede kroppe og syv par
- Undersøgelse afslører en ny ensartet belægningsproces af p-ALD
- Teslas administrerende direktør Musk håner shortsælgere under juridisk undersøgelse
- Alle ting kunne være en del af Internet of Things med nyt RFID-system
- Klare tidsmæssige afgrænsninger for rav, kopal og harpiks hjælper i undersøgelser af tab af biod…
- Forskere laver en fotografisk film af en molekylær switch
- Indien opsender raket med dusinvis af satellitter