


Den usikre enhjulede cykel, der lærte sig selv, og hvordan den hjælper AI med at træffe gode beslutninger

Kredit:Distriktet
Cambridge-forskere er banebrydende for en form for maskinlæring, der starter med kun lidt forhåndsviden og løbende lærer af verden omkring sig.
I midten af skærmen er en lillebitte ethjulet cykel. Animationen starter, ethjulet slingrer frem og falder. Dette er prøve #1. Det er nu prøve #11, og der er en ændring - en næsten umærkelig forsinkelse i efteråret, måske et forsøg på at rette sig op før det uundgåelige styrt. "Det er at lære af erfaring, " nikker professor Carl Edward Rasmussen.
Efter et minut, unicyklen vugger forsigtigt frem og tilbage, mens den cirkler på stedet. Det har fundet ud af, hvordan dette ekstremt ustabile system fungerer og har mestret sit mål. "Enhjulingen starter med at vide intet om, hvad der foregår - det er kun blevet fortalt, at dens mål er at blive i centrum på en oprejst måde. Når den begynder at falde frem og tilbage, det begynder at lære, " forklarer Rasmussen, der leder Computational and Biological Learning Lab i Institut for Ingeniørvidenskab. "Vi havde en rigtig ethjulsrobot, men den var faktisk ret farlig – den var stærk – og så nu bruger vi data fra den rigtige til at køre simuleringer, og vi har en miniversion."
Rasmussen bruger den selvlærte ethjulet cykel til at demonstrere, hvordan en maskine kan starte med meget lidt data og lære dynamisk, at forbedre sin viden, hver gang den modtager ny information fra sit miljø. Konsekvenserne af at justere dens motoriserede momentum og balance hjælper enhjulet til at lære, hvilke bevægelser der var vigtige for at hjælpe den med at forblive oprejst i midten.
"Det er ligesom et menneske ville lære, " forklarer professor Zoubin Ghahramani, der leder Machine Learning Group i Institut for Ingeniørvidenskab. "Vi begynder ikke at vide alt. Vi lærer tingene gradvist, kun ud fra nogle få eksempler, og vi ved, hvornår vi endnu ikke er sikre på vores forståelse."
Ghahramanis team er banebrydende for en gren af AI kaldet kontinuerlig maskinlæring. Han forklarer, at mange af de nuværende former for maskinlæring er baseret på neurale netværk og deep learning-modeller, der bruger komplekse algoritmer til at finde mønstre i enorme datasæt. Almindelige applikationer omfatter oversættelse af sætninger til forskellige sprog, genkende mennesker og genstande i billeder, og opdager usædvanlige forbrug på kreditkort.
"Disse systemer skal trænes i millioner af mærkede eksempler, som tager tid og meget computerhukommelse, " forklarer han. "Og de har fejl. Når du tester dem uden for de data, de blev trænet i, har de en tendens til at præstere dårligt. førerløse biler, for eksempel, kan trænes på et enormt datasæt af billeder, men de er muligvis ikke i stand til at generalisere til tågede forhold.
"Værre end det, de nuværende deep learning-systemer kan nogle gange give os selvsikkert forkerte svar, og give begrænset indsigt i, hvorfor de har truffet bestemte beslutninger. Det er det, der generer mig. Det er okay at tage fejl, men det er ikke i orden at tage selvsikkert fejl."
Nøglen er, hvordan du håndterer usikkerhed – usikkerheden ved rodet og manglende data, og usikkerheden ved at forudsige, hvad der kan ske næste gang. "Usikkerhed er ikke en god ting - det er noget, man bekæmper, men du kan ikke bekæmpe det ved at ignorere det, ", siger Rasmussen. "Vi er interesserede i at repræsentere usikkerheden."
Det viser sig, at der er en matematisk teori, der fortæller dig, hvad du skal gøre. Det blev først beskrevet af den engelske statistiker Thomas Bayes fra det 18. århundrede. Ghahramanis gruppe var en af de tidligste adoptanter i AI af Bayesiansk sandsynlighedsteori, som beskriver, hvordan sandsynligheden for, at en hændelse indtræffer (såsom at forblive oprejst i midten) opdateres, efterhånden som flere beviser (såsom den beslutning, enhjulet sidst tog før den væltede) bliver tilgængelig.
Dr. Richard Turner forklarer, hvordan Bayes' regel håndterer kontinuerlig læring:"systemet tager sin forudgående viden, vægter det efter, hvor nøjagtigt det tror, at viden er, kombinerer det derefter med nye beviser, der også vægtes af dets nøjagtighed.
"Dette er meget mere dataeffektivt end den måde et standard neuralt netværk fungerer på, " tilføjer han. "Ny information kan få et neuralt netværk til at glemme alt det, det har lært tidligere – kaldet katastrofal forglemmelse – hvilket betyder, at det skal se på alle dets mærkede eksempler igen, som at genlære reglerne og ordlisten for et sprog, hver gang du lærer et nyt ord.
"Vores system behøver ikke at gense alle de data, det har set før – ligesom mennesker ikke husker alle tidligere oplevelser; i stedet lærer vi en oversigt, og vi opdaterer den, efterhånden som tingene fortsætter." Ghahramani tilføjer:"Det fantastiske ved Bayesiansk maskinlæring er, at systemet træffer beslutninger baseret på evidens - det opfattes nogle gange som 'automatisering af den videnskabelige metode' - og fordi det er baseret på sandsynlighed, den kan fortælle os, når den er uden for sin komfortzone."
Ghahramani er også Chief Scientist hos Uber. Han ser en fremtid, hvor maskiner løbende lærer, ikke kun individuelt, men som en del af en gruppe. "Uanset om det er virksomheder som Uber, der optimerer udbud og efterspørgsel, eller autonome køretøjer, der advarer hinanden om, hvad der er forude på vejen, eller robotter, der arbejder sammen om at løfte en tung byrde – samarbejde, og nogle gange konkurrence, i AI vil hjælpe med at løse problemer på tværs af en lang række industrier."
En af de virkelig spændende grænser er at kunne modellere sandsynlige resultater i fremtiden, som Turner beskriver. "Usikkerhedens rolle bliver meget tydelig, når vi begynder at tale om at forudsige fremtidige problemer som klimaændringer."
Turner arbejder sammen med klimaforskerne Dr. Emily Shuckburgh og Dr. Scott Hosking ved British Antarctic Survey for at spørge, om maskinlæringsteknikker kan forbedre forståelsen af risici for klimaændringer i fremtiden.
"Vi er nødt til at kvantificere den fremtidige risiko og virkningerne af ekstremt vejr på lokal skala for at informere politiske reaktioner på klimaændringer, " forklarer Shuckburgh. "De traditionelle computersimuleringer af klimaet giver os en god forståelse af de gennemsnitlige klimaforhold. Det, vi sigter efter at gøre med dette arbejde, er at kombinere den viden med observationsdata fra satellitter og andre kilder for at få bedre styr på, for eksempel, risikoen for vejrbegivenheder med lav sandsynlighed, men med stor indflydelse."
"Det er faktisk en fascinerende maskinlæringsudfordring, " siger Turner, hvem er med til at identificere, hvilket område af klimamodellering der er mest egnet til at bruge Bayesiansk sandsynlighed. "Dataene er ekstremt komplekse, og nogle gange mangler og umærket. Usikkerhederne er mange." Et væsentligt element af usikkerhed er det faktum, at forudsigelserne er baseret på vores fremtidige reduktion af emissioner, hvis omfang er endnu ukendt.
"En interessant del af dette for politiske beslutningstagere, bortset fra prognoseværdien, er, at du kan forestille dig at have en maskine, der hele tiden lærer af konsekvenserne af afbødningsstrategier såsom reduktion af emissioner – eller manglen på dem – og justerer sine forudsigelser i overensstemmelse hermed, " tilføjer Turner.
Det, han beskriver, er en maskine, der – ligesom ethjulet – lever af usikkerhed, lærer løbende af den virkelige verden, og vurderer og revurderer derefter alle mulige resultater. Når det kommer til klima, imidlertid, det er også en maskine med alle mulige fremtider.
 Varme artikler
Varme artikler
-
 Forskere udvikler et referencemål for orbitalsatellitter, der kalibrererÅbent reflektansmål. Kredit:Ural Federal University For første gang, et internationalt team af forskere fra Rusland, Estland og Finland har analyseret driften af et målpanel bygget i den sydøstl
Forskere udvikler et referencemål for orbitalsatellitter, der kalibrererÅbent reflektansmål. Kredit:Ural Federal University For første gang, et internationalt team af forskere fra Rusland, Estland og Finland har analyseret driften af et målpanel bygget i den sydøstl -
 Sky -aktier stiger ved Comcast -overtagelsesejrenLedelsen hos Sky har anbefalet sine aktionærer straks at acceptere Comcasts bud Aktier i den britiske tv-station Sky steg mandag, efter at den amerikanske kabelgigant Comcast overgik Rupert Murdoc
Sky -aktier stiger ved Comcast -overtagelsesejrenLedelsen hos Sky har anbefalet sine aktionærer straks at acceptere Comcasts bud Aktier i den britiske tv-station Sky steg mandag, efter at den amerikanske kabelgigant Comcast overgik Rupert Murdoc -
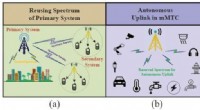 Forskere udvikler en intelligent spektrumfølingsteknik til 5G -kommunikationTre typiske spektrumføler involverede scenarier i 5G -kommunikation. Kredit:SARI Spektrumsregistrering spiller en vigtig rolle i fremtidens trådløse kommunikationssystemer, da det hjælper med at l
Forskere udvikler en intelligent spektrumfølingsteknik til 5G -kommunikationTre typiske spektrumføler involverede scenarier i 5G -kommunikation. Kredit:SARI Spektrumsregistrering spiller en vigtig rolle i fremtidens trådløse kommunikationssystemer, da det hjælper med at l -
 Hvad spiser Apple egentlig – og hvorfor Steve Jobs ikke ville klare sig meget bedreJobs værd? Kredit:franz12 Apple har startet det nye år med at skuffe investorer med sin første profit-advarsel i 17 år. Virksomheden sagde, at dårligt salg af dets seneste serie af iPhones har vær
Hvad spiser Apple egentlig – og hvorfor Steve Jobs ikke ville klare sig meget bedreJobs værd? Kredit:franz12 Apple har startet det nye år med at skuffe investorer med sin første profit-advarsel i 17 år. Virksomheden sagde, at dårligt salg af dets seneste serie af iPhones har vær
- Indviklet magnetisk konfiguration af 3-D nanoskala gyroide netværk afsløret
- Strålingstryk med rekyl:Eksperimentelt bevis for en 90 år gammel teori
- Frygt for naturbrande inspirerer fremadstormende samfund
- Hvordan private fængselsvirksomheder påvirker immigrationspolitikken
- Understøttede flydende metalkatalysatorer - en ny generation af reaktionsacceleratorer
- Fra kameraer til computere, nyt materiale kan ændre den måde, vi arbejder og leger på