


TACC bygger problemfri software til videnskabelig innovation
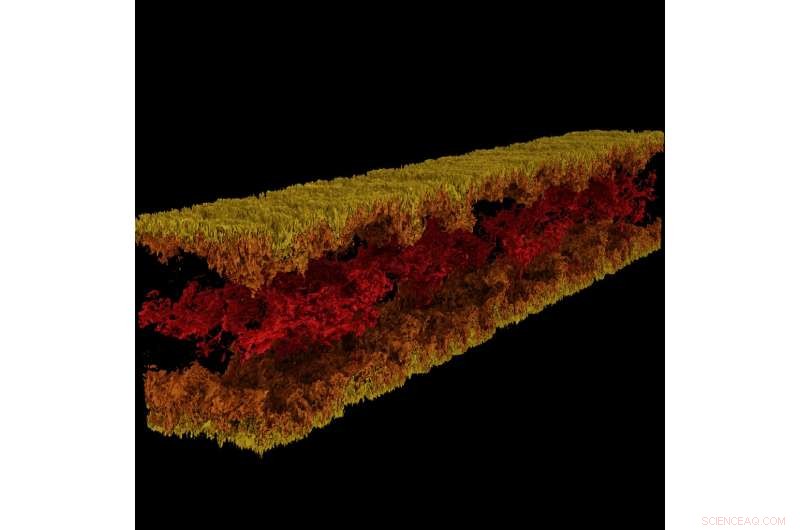
Turbulent kanalflowvisualisering produceret ved hjælp af GraviT. Kredit:Visualisering:Texas Advanced Computing Center. Data:ICES, University of Texas i Austin.
Stor, effektfuld videnskab kræver et helt teknologisk økosystem for at udvikle sig. Dette inkluderer avancerede computersystemer, lager med høj kapacitet, højhastighedsnetværk, strøm, køling... listen bliver ved og ved.
Kritisk, det kræver også avanceret software:programmer, der arbejder problemfrit sammen for at give videnskabsmænd og ingeniører mulighed for at besvare svære spørgsmål, dele deres løsninger, og udføre forskning med maksimal effektivitet og minimal smerte.
For at pleje denne kritiske måde for videnskabelig fremgang, i 2012 etablerede NSF programmet Software Infrastructure for Sustained Innovation (SI2), med det mål at transformere innovationer inden for forskning og uddannelse til vedvarende softwareressourcer, der er en integreret del af cyberinfrastrukturen.
"Videnskabelig opdagelse og innovation skrider frem ad fundamentalt nye veje åbnet af udvikling af stadig mere sofistikeret software, " skrev National Science Foundation (NSF) i SI2-programmets anmodning. "Software er også direkte ansvarlig for øget videnskabelig produktivitet og betydelig forbedring af forskernes kapacitet."
Med fem aktuelle SI2-priser, og samarbejdsroller på flere flere, Texas Advanced Computing Center (TACC) er blandt de nationale førende inden for udvikling af software til videnskabelig databehandling. Principal investigators fra TACC vil præsentere deres arbejde fra den 30. april til den 2. maj på NSF SI2 Principal investigators Meeting 2018 i Washington, D.C.
"En del af TACC's mission er at øge produktiviteten hos forskere, der bruger vores systemer, " sagde Bill Barth, TACC-direktør for high performance computing og en tidligere SI2-bevillingsmodtager. "SI2-programmet har hjulpet os med at gøre det ved at støtte bestræbelserne på at udvikle nye værktøjer og udvide eksisterende værktøjer med yderligere ydeevne og brugervenlige funktioner."
Fra rammer til storskala visualisering til automatiske paralleliseringsværktøjer og mere, TACC-udviklet software ændrer, hvordan forskere regner i fremtiden.
Interaktivt paralleliseringsværktøj
Supercomputeres magt ligger primært i deres evne til at løse matematiske ligninger parallelt. Tag et hårdt problem, opdele det i dets bestanddele, løs hver del individuelt og bring svarene sammen igen - dette er parallel computing i sin essens. Imidlertid, opgaven med at organisere sit problem, så det kan løses af en supercomputer, er ikke let, selv for erfarne computerforskere.
Ritu Arora, en forsker ved TACC, har arbejdet på at sænke barren til parallel computing ved at udvikle et værktøj, der kan dreje en seriel kode, som kun kan bruge en enkelt processor ad gangen, ind i en parallel kode, der kan bruge titusinder til tusindvis af processorer. Værktøjet analyserer en seriel applikation, anmoder om yderligere oplysninger fra brugeren, anvender indbygget heuristik, og genererer en parallel version af den serielle inputapplikation.
Arora og hendes samarbejdspartnere implementerede den nuværende version af IPT i skyen, så forskere nemt kan bruge den gennem en webbrowser. Forskere kan generere parallelle versioner af deres kode semi-automatisk og teste parallelkoden for nøjagtighed og ydeevne på TACC- og XSEDE-ressourcer, inklusive Stampede2, Lonestar5, og Comet.
"Størrelsen af den samfundsmæssige påvirkning af IPT er en direkte funktion af vigtigheden af HPC i STEM og nye ikke-traditionelle domæner, og de stejle udfordringer, som domæneeksperter og studerende står over for, når de klatrer op på læringskurven for parallel programmering, " sagde Arora. "Udover at reducere tiden til udvikling og eksekveringstiden for applikationerne på HPC-platforme, IPT vil reducere energiforbruget og maksimere ydeevnen leveret af HPC-platformene gennem dets evne til at generere hybridkode."

GraviT gjorde det muligt for forskere at producere strålesporingsvisualiseringer ved hjælp af data produceret fra Enzo, en simuleringskode designet til rig, multifysik hydrodynamiske astrofysiske beregninger. Kredit:University of Texas i Austin
Som et eksempel på IPT's muligheder, Arora peger på en nylig indsats for at parallelisere en molekylær dynamik (MD) applikation. Ved at parallelisere den serielle applikation ved hjælp af OpenMP på et højt abstraktionsniveau - dvs. uden at brugeren kendte OpenMP's syntaks på lavt niveau – de opnåede en 88% fremskyndelse i koden.
De kvantificerede også virkningen af IPT med hensyn til brugerproduktivitet ved at måle antallet af kodelinjer, som en forsker skal skrive under processen med at parallelisere en applikation manuelt versus at bruge IPT.
"I vores testsager, IPT øgede brugerens produktivitet med mere end 90 %, sammenlignet med at skrive koden manuelt, og genererede den parallelle kode, der er inden for 10 % af ydeevnen af den bedst tilgængelige håndskrevne parallelkode til disse applikationer, " sagde Arora. "Vi er meget glade for dens succes indtil videre."
TACC udvider IPT til at understøtte yderligere typer af serielle applikationer såvel som applikationer, der udviser uregelmæssige beregnings- og kommunikationsmønstre.
(Se en videodemonstration af IPT, hvor TACC viser processen med at parallelisere en molekylær dynamikapplikation med OpenMP-programmeringsmodellen.)
GraviT
Videnskabelig visualisering - processen med at transformere rå data til fortolkelige billeder - er et nøgleaspekt af forskning. Imidlertid, det kan være udfordrende, når du prøver at visualisere datasæt i petabyte-skala spredt blandt mange noder i en computerklynge. Endnu mere, når du prøver at bruge avancerede visualiseringsmetoder som ray tracing - en teknik til at generere et billede ved at spore lysets vej som pixels i et billedplan og simulere virkningerne af dets møder med virtuelle objekter.
For at løse dette problem, Paul Navratil, direktør for visualisering hos TACC, har ledet et forsøg på at skabe GraviT, en skalerbar, distributed-memory ray tracing framework og softwarebibliotek til applikationer, der omfatter data så store, at de ikke kan ligge i hukommelsen på en enkelt computerknude. Samarbejdspartnere på projektet omfatter Hank Childs (University of Oregon), Chuck Hansen (University of Utah), Matt Turk (National Center for Supercomputing Applications) og Allen Malony (ParaTools).
GraviT fungerer på tværs af en række hardwareplatforme, inklusive Intel Xeon-processorer og NVIDIA GPU'er. It can also function in heterogeneous computing environments, for eksempel, hybrid CPU and GPU systems. GraviT has been successfully integrated into the GLuRay OpenGL-based ray tracing interface, the VisIt visualization toolkit, the VTK visualization toolkit, and the yt visualization framework.
"High-fidelity rendering techniques like ray tracing improve visual analysis by providing the same spatial cues of light and shadow that we see in the world around us, but these are challenging to use in distributed contexts, " said Navratil. "GraviT enables these techniques to be used efficiently across distributed computing resources, unlocking their potential for large scale analysis and to be used in situ, where data is not written to disk prior to analysis."
(The GraviT source code is available at the TACC GitHub site ).
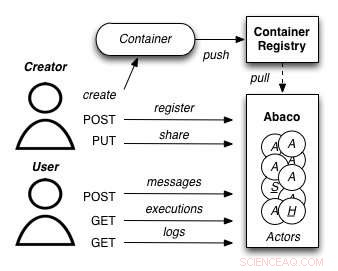
A diagram showing how the Abaco "Actor" model works. Credit:University of Texas at Austin
Abaco
The increased availability of data has enabled entirely new kinds of analyses to emerge, yielding answers to many important questions. Imidlertid, these analyses are complex and frequently require advanced computer science expertise to run correctly.
Joe Stubbs, who leads TACC's Cloud and Interactive Computing (CIC) group, is working on a project that simplifies how researchers create analysis tools that are reliable and scalable. Projektet, known as Abaco, adapts the "Actor" model, whereby software systems are designed as a collection of simple functions, which can then be provided as a cloud-based capability on high performance computing environments.
"Abaco significantly simplifies the way scientific software is developed and used, " said Stubbs. "Scientific software developers will find it much easier to design and implement a system. Yderligere, scientists and researchers that use software will be able to easily compose collections of actors with pre-determined functionality in order to get the computation and data they need."
The Abaco API (application programming interface) combines technologies and techniques from cloud computing, including Linux Containers and the "functions-as-a-service" paradigm, with the Actor model for concurrent computation. Investigators addressing grand challenge problems in synthetic biology, earthquake engineering and food safety are already using the tool to advance their work. Stubbs is working to extend Abaco's ability to do data federation and discoverability, so Abaco programs can be used to build federated datasets consisting of separate datasets from all over the internet.
"By reducing the barriers to developing and using such services, this project will boost the productivity of scientists and engineers working on the problems of today, and better prepare them to tackle the new problems of tomorrow, " Stubbs said.
Expanding volunteer computing
Volunteer computing uses donated computing time on consumer devices such as home computers and smartphones to conduct scientific investigations. Early successes from this approach include the discovery of the structure of an enzyme involved in reproduction of HIV by FoldIt participants; and the detection of pulsars using Einstein@Home.
Volunteer computing can provide greater computing power, at lower cost, than conventional approaches such as organizational computing centers and commercial clouds, but participation in volunteer computing efforts is yet to reach its full potential.
TACC is partnering with the University of California at Berkeley and Purdue University to build new capabilities for BOINC (the most common software framework used for volunteer computing) to grow this promising mode of distributed computing. The project involves two complementary development efforts. Først, it adds BOINC-based volunteer computing conduits to two major high-performance computing providers:TACC and nanoHUB, a web portal for nano science that provides computing capabilities. På denne måde the project benefits the thousands of scientists who use these facilities and creates technologies that make it easy for other HPC providers to add their own volunteer computing capability to their systems.
Sekund, the team will develop a unified interface for volunteer computing, tentatively called Science United, where donors can register to participate and scientists can market their volunteer computing projects to the public.
TACC is currently setting up a BOINC server on Jetstream and using containerization technologies, such as Docker and VirtualBox, to build and package popular applications that can run in high-throughput computing mode on the devices of volunteers. Initial applications being tested include AutoDock Vina, used for drug discovery, and OpenSees, used by the natural hazards community. Som et næste skridt, TACC will develop the plumbing required for selecting and routing qualified jobs from TACC resources to the BOINC server.
"By creating a huge pool of low-cost computing power that will benefit thousands of scientists, and increasing public awareness of and interest in science, the project plans to establish volunteer computing as a central and long-term part of the U.S. scientific cyber infrastructure, " said David Anderson, the lead principal investigator on the project from UC Berkeley.
 Varme artikler
Varme artikler
-
 Dommerregler Lyft skal følge New Yorks regler for chaufførs mindstelønNew Yorks borgmester Bill de Blasio roste en dommers beslutning om, at ridefirmaet Lyft skal følge nye regler om at betale chauffører en mindsteløn Kørselsfirmaet Lyft skal overholde en ny regel i
Dommerregler Lyft skal følge New Yorks regler for chaufførs mindstelønNew Yorks borgmester Bill de Blasio roste en dommers beslutning om, at ridefirmaet Lyft skal følge nye regler om at betale chauffører en mindsteløn Kørselsfirmaet Lyft skal overholde en ny regel i -
 Aktier eksploderer, da Chinas Nasdaq debutererDen nye bestyrelse markerer Kinas mest betydningsfulde markedsreformer, og embedsmænd håber, at den en dag vil være lige så kendt som Nasdaq Aktierne på Shanghais nye teknologi bord i Nasdaq-stil
Aktier eksploderer, da Chinas Nasdaq debutererDen nye bestyrelse markerer Kinas mest betydningsfulde markedsreformer, og embedsmænd håber, at den en dag vil være lige så kendt som Nasdaq Aktierne på Shanghais nye teknologi bord i Nasdaq-stil -
 Facebook køber producent af hit VR-spil Beat SabreEn mand spiller Beat Sabre under E3 Video Game Convention i Los Angeles i juni 2019 Facebook-ejede Oculus sagde tirsdag, at det køber studiet bag det populære virtual reality-spil Beat Sabre, da d
Facebook køber producent af hit VR-spil Beat SabreEn mand spiller Beat Sabre under E3 Video Game Convention i Los Angeles i juni 2019 Facebook-ejede Oculus sagde tirsdag, at det køber studiet bag det populære virtual reality-spil Beat Sabre, da d -
 Lavprisnavigationssystem til ubemandede luftsystemerKredit:CC0 Public Domain Et EU-finansieret initiativ har udviklet et billigt positionerings- og navigationssystem til ubemandede luftsystemer (UAS). Brug af flere antenner, enheden er baseret på h
Lavprisnavigationssystem til ubemandede luftsystemerKredit:CC0 Public Domain Et EU-finansieret initiativ har udviklet et billigt positionerings- og navigationssystem til ubemandede luftsystemer (UAS). Brug af flere antenner, enheden er baseret på h
- Femte klasse videnskabelige fairprojekter med målbare data
- Nanovidenskabsfolk foreslår brug af støvsugere til at overvinde grænserne for konventionel silici…
- Molekylær spredning forbedrer kvasi-dobbeltlags organiske solceller
- At skelne ægte mønstre fra simple menneskelige fejlopfattelser
- Formålet med bufferen i elektroforese
- Video:Højtflyvende, iøjnefaldende droner indsamler data fra storme