


En modelfri dybforstærkningslæringsmetode til at tackle neurale kontrolproblemer
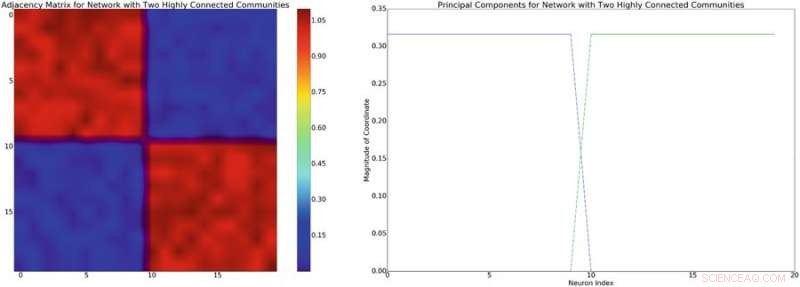
Til venstre:eksempel på en adjacensmatrix med omtrentlig blokdiagonal struktur. Forudsat en lineær blandingsmodel af neuronale interaktioner, denne netværksstruktur vil fremkalde en tilnærmelsesvis blokdiagonal kovarians af lignende struktur. Til højre:hovedkomponenterne i tilknytning til matricen til venstre. Kredit:Mitchell &Petzold
Brian Mitchell og Linda Petzold, to forskere ved University of California, for nylig har anvendt modelfri dyb forstærkningslæring på modeller af neuraldynamik, opnå meget lovende resultater.
Forstærkningslæring er et område inden for maskinlæring inspireret af behavioristisk psykologi, der træner algoritmer til effektivt at udføre bestemte opgaver, ved hjælp af et system baseret på belønning og straf. En fremtrædende milepæl på dette område har været udviklingen af Deep-Q-Network (DQN), som oprindeligt blev brugt til at træne en computer til at spille Atari -spil.
Modelfri forstærkningslæring er blevet anvendt på en række forskellige problemer, men DQN bruges generelt ikke. Den primære årsag til dette er, at DQN kan foreslå et begrænset antal handlinger, mens fysiske problemer generelt kræver en metode, der kan foreslå et kontinuum af handlinger.
Mens man læser eksisterende litteratur om neuralkontrol, Mitchell og Petzold lagde mærke til den udbredte brug af et klassisk paradigme til løsning af neurale kontrolproblemer med maskinlæringsstrategier. Først, ingeniøren og eksperimentatoren er enige om formålet og designet af deres undersøgelse. Derefter, sidstnævnte kører eksperimentet og indsamler data, som senere vil blive analyseret af ingeniøren og bruges til at bygge en model af systemet af interesse. Endelig, ingeniøren udvikler en controller til modellen, og enheden implementerer denne controller.
Resultater af eksperimentet, der kontrollerer oscillation i faserummet defineret af en enkelt hovedkomponent. Det første plot fra toppen er et plot af input til den aktiverede celle over tid; det andet plot fra toppen er et plot af pigge i hele netværket, hvor forskellige farver svarer til forskellige celler; det tredje plot ovenfra svarer til cellens membranpotentiale over tid; det fjerde fra det øverste plot viser måloscillationen; det nederste plot viser den observerede svingning. Politikken, på trods af at levere input til kun en enkelt celle, er i stand til omtrent at inducere måloscillationen i det observerede faseområde. Kredit:Mitchell &Petzold 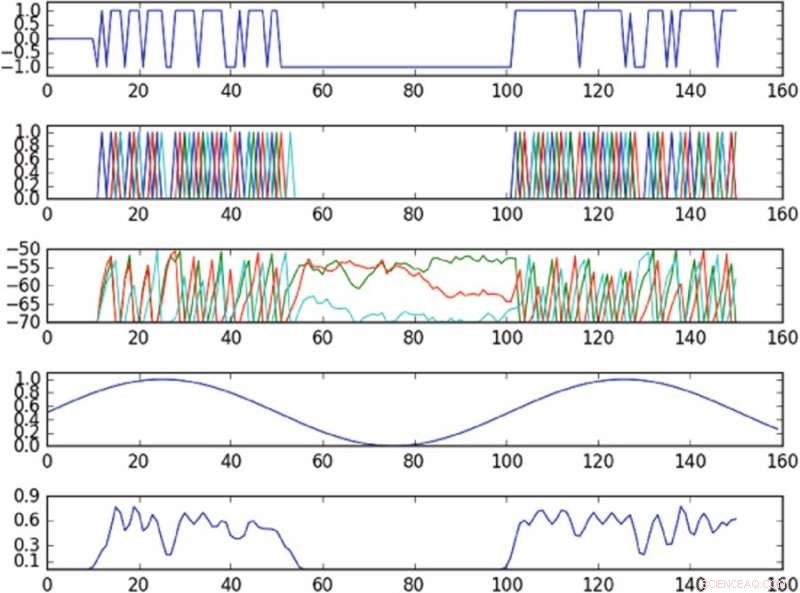
Forskerne tilpassede en modelfri forstærkningslæringsmetode kaldet "deep deterministic policy gradients" (DDPG) og anvendte den på modeller af neurale dynamikker på lavt og højt niveau. De valgte specifikt DDPG, fordi det tilbyder en meget fleksibel ramme, hvilket ikke kræver, at brugeren modellerer systemdynamik.
Nyere forskning har fundet ud af, at modelfrie metoder generelt har brug for for mange eksperimenter med miljøet, gør det sværere at anvende dem på mere praktiske problemer. Ikke desto mindre, forskerne fandt ud af, at deres modelfrie tilgang fungerede bedre end nuværende modelbaserede metoder og var i stand til at løse vanskeligere neurale dynamikproblemer, såsom kontrol af baner gennem et latent faserum i et under aktiveret netværk af neuroner.
"For de problemer, vi overvejede i dette papir, modelfrie tilgange var ganske effektive og krævede slet ikke meget eksperimenter, tyder på, at for neurale problemer, state-of-the-art controllere er mere praktisk nyttige end folk måske havde troet, "sagde Mitchell.
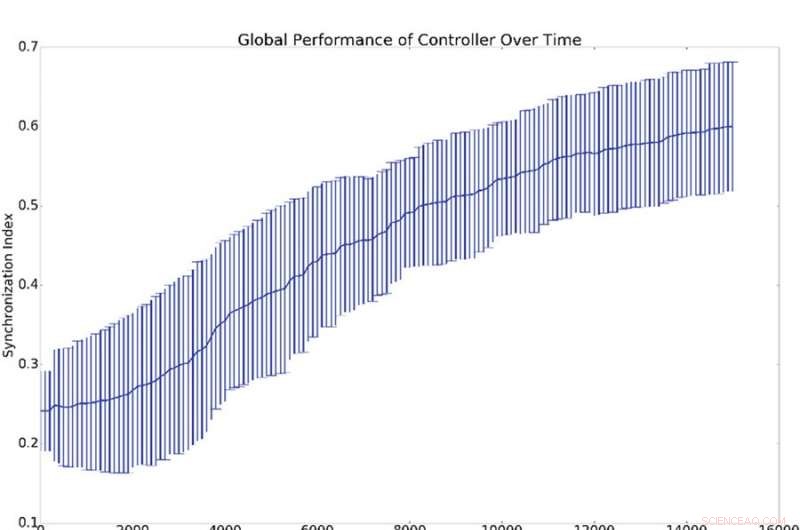
Resuméresultater af 10 synkroniseringsforsøg. (a) skildrer middelværdien og standardafvigelsen for den globale synkronisering, (dvs. q fra ligning 16), mod antallet af træningsperioder for den dataansvarlige. (b) Viser histogrammer, der viser synkroniseringsniveauet for alle netværksoscillatorer med referenceoscillatoren (dvs. qi fra ligning 16). Det er, et punkt på enten de blå eller grønne kurver viser sandsynligheden for at have en given værdi for qi. Det blå histogram viser tællinger før træning, mens det grønne histogram viser tællinger efter træning. Den gennemsnitlige synkronisering med referencen, qi, er meget højere end global synkronisering, q, hvilket forklares ved, at synkronisering med referencen er lettere at fremkalde end global synkronisering. Kredit:Mitchell &Petzold
Mitchell og Petzold udførte deres undersøgelse som en simulering, derfor skal vigtige praktiske og sikkerhedsmæssige aspekter overvejes, før deres metode kan introduceres inden for kliniske rammer. Yderligere forskning, der inkorporerer modeller i modelfrie tilgange, eller det sætter grænser for modelfrie controllere, kunne bidrage til at øge sikkerheden, før disse metoder går ind i kliniske indstillinger.
I fremtiden, forskerne planlægger også at undersøge, hvordan neurale systemer tilpasser sig kontrol. Menneskelige hjerner er meget dynamiske organer, der tilpasser sig deres omgivelser og ændrer sig som reaktion på ekstern stimulering. Dette kan forårsage en konkurrence mellem hjernen og kontrolleren, især når deres mål ikke er i overensstemmelse.
"I mange tilfælde, vi vil have controlleren til at vinde, og designet af controllere, der altid vinder, er et vigtigt og interessant problem, "sagde Mitchell." For eksempel, i det tilfælde, hvor det væv, der kontrolleres, er en syg region i hjernen, denne region kan have en vis progression, som controlleren forsøger at rette. Ved mange sygdomme, denne progression kan modstå behandling (f.eks. en tumor, der tilpasser sig udvisning af kemoterapi, er et kanonisk eksempel), men de nuværende modelfrie tilgange tilpasser sig ikke godt til den slags ændringer. Forbedring af modelfrie controllere til bedre at håndtere tilpasning fra hjernens side er en interessant retning, som vi ser på. "
Forskningen er publiceret i Videnskabelige rapporter .
© 2018 Tech Xplore
 Varme artikler
Varme artikler
-
 Et følelsesmæssigt deep alignment netværk (DAN) til at klassificere og visualisere følelserKredit:Tautkutè &Trzcinski Forskere ved det polsk-japanske akademi for informationsteknologi og Warszawas teknologiske universitet har udviklet en DAN-model (deep alignment network) til at klassif
Et følelsesmæssigt deep alignment netværk (DAN) til at klassificere og visualisere følelserKredit:Tautkutè &Trzcinski Forskere ved det polsk-japanske akademi for informationsteknologi og Warszawas teknologiske universitet har udviklet en DAN-model (deep alignment network) til at klassif -
 Verdensbanken satser stort på batterier til solenergi-boostSolpaneler i George Lufthavn, Sydafrikas første solcelledrevne lufthavn Solenergi kan være en enorm energikilde i Afrika, men dets potentiale er blevet hæmmet af batterier, der er for dyre og util
Verdensbanken satser stort på batterier til solenergi-boostSolpaneler i George Lufthavn, Sydafrikas første solcelledrevne lufthavn Solenergi kan være en enorm energikilde i Afrika, men dets potentiale er blevet hæmmet af batterier, der er for dyre og util -
 GymCam sporer øvelser, som bærbare skærme ikke kanForskere ved Carnegie Mellon University har udviklet et visionsbaseret system til overvågning af træningsøvelser. De testede det i et travlt gymnasium på universitetet, demonstrerer, at systemet samti
GymCam sporer øvelser, som bærbare skærme ikke kanForskere ved Carnegie Mellon University har udviklet et visionsbaseret system til overvågning af træningsøvelser. De testede det i et travlt gymnasium på universitetet, demonstrerer, at systemet samti -
 Pyeongchang OL viser koreanske selvkørende bilerI denne mandag, 12. februar kl. 2018, Foto, Hyundais autonome brændselscelle el -køretøj Nexo køres ad en vej nær Pyeongchang olympiske stadion i Pyeongchang, Sydkorea. Ved vinter -OL i Pyeongchang, d
Pyeongchang OL viser koreanske selvkørende bilerI denne mandag, 12. februar kl. 2018, Foto, Hyundais autonome brændselscelle el -køretøj Nexo køres ad en vej nær Pyeongchang olympiske stadion i Pyeongchang, Sydkorea. Ved vinter -OL i Pyeongchang, d