


En letvægts og præcis dyb læringsmodel til audiovisuel følelsesgenkendelse
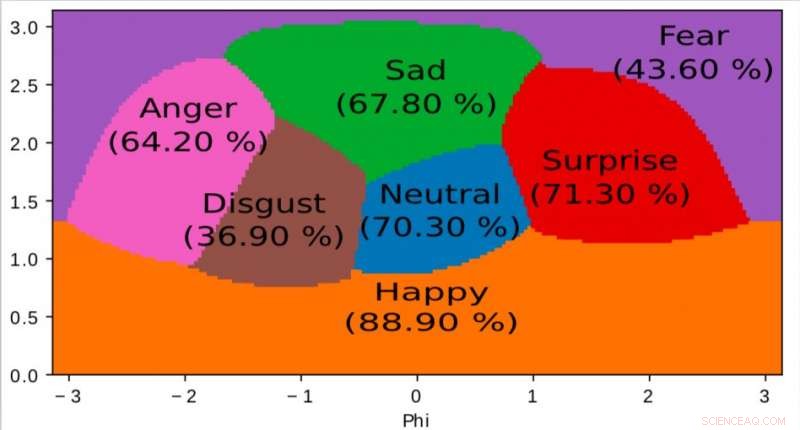
En repræsentation af det indre rum lært af vores algoritme og brugt til at kortlægge følelser i et kontinuerligt 2D rum. Det er interessant at bemærke, at selvom træningsdata kun indeholder diskrete følelsesmærker, netværket lærer et kontinuerligt rum, giver ikke kun mulighed for fint at beskrive menneskers følelsesmæssige tilstand, men også at positionere følelser i forhold til hinanden. Dette rum har stærk lighed med ophidselsesvalensrummet defineret af moderne psykologi. Kredit:Jurie et al.
Forskere ved Orange Labs og Normandie University har udviklet en ny dyb neural model til audiovisuel følelsesgenkendelse, der fungerer godt med små træningssæt. Deres studie, som var forudgivet den arXiv , følger en filosofi om enkelhed, væsentligt at begrænse de parametre, som modellen tilegner sig fra datasæt, og ved at bruge simple læringsteknikker.
Neurale netværk til følelsesgenkendelse har en række nyttige anvendelser inden for sundhedssektoren, kundeanalyse, overvågning, og endda animation. Mens state-of-the-art dyb læringsalgoritmer har opnået bemærkelsesværdige resultater, de fleste er stadig ikke i stand til at nå den samme forståelse af følelser, som mennesker opnår.
"Vores overordnede mål er at lette menneske-computer interaktion ved at gøre computere i stand til at opfatte forskellige subtile detaljer udtrykt af mennesker, "Frédéric Jurie, en af de forskere, der har udført undersøgelsen, fortalte TechXplore. "At opfatte følelser indeholdt i billeder, video, stemme og lyd falder inden for denne sammenhæng."
For nylig, undersøgelser har sammensat multimodale og tidsmæssige datasæt, der indeholder kommenterede videoer og audiovisuelle klip. Alligevel indeholder disse datasæt typisk et relativt lille antal kommenterede prøver, samtidig med at de skal præstere godt, de fleste eksisterende deep learning-algoritmer kræver større datasæt.
Forskerne forsøgte at løse dette problem ved at udvikle en ny ramme for audiovisuel følelsesgenkendelse, som kombinerer analysen af visuelle og lydoptagelser, bevare et højt niveau af nøjagtighed selv med relativt små træningsdatasæt. De trænede deres neurale model på AFEW, et datasæt med 773 audiovisuelle klip udtrukket fra film og kommenteret med diskrete følelser.

Illustration af, hvordan dette 2D-rum kan bruges til at kontrollere følelser udtrykt af ansigter, på en kontinuerlig måde, ved hjælp af adversarial generative networks (GAN). Kredit:Jurie et al.
"Man kan se denne model som en sort boks, der behandler videoen og automatisk udleder folks følelsesmæssige tilstand, " Jurie forklarede. "En stor fordel ved sådanne dybe neurale modeller er, at de selv lærer, hvordan man behandler videoen ved at analysere eksempler, og kræver ikke, at eksperter leverer specifikke behandlingsenheder."
Den model, som forskerne har udtænkt, følger Occams razor filosofiske princip, hvilket antyder, at mellem to tilgange eller forklaringer, den enkleste er det bedste valg. I modsætning til andre deep learning-modeller for følelsesgenkendelse, derfor, deres model holdes relativt simpel. Det neurale netværk lærer et begrænset antal parametre fra datasættet og anvender grundlæggende læringsstrategier.
"Det foreslåede netværk er lavet af kaskadede behandlingslag, der abstraherer informationen, fra signalet til dets fortolkning, " sagde Jurie. "Lyd og video behandles af to forskellige kanaler på netværket og kombineres på det seneste i processen, næsten til sidst."
Når testet, deres lysmodel opnåede en lovende følelsesgenkendelsesnøjagtighed på 60,64 procent. Det blev også rangeret som fjerde ved 2018 Emotion Recognition in the Wild (EmotiW)-udfordringen, afholdt på ACM International Conference on Multimodal Interaction (ICMI), i Colorado.

Illustration af, hvordan dette 2D-rum kan bruges til at kontrollere følelser udtrykt af ansigter, på en kontinuerlig måde, ved hjælp af adversarial generative networks (GAN). Kredit:Jurie et al.
"Vores model er et bevis på, at efter Occams barbermaskineprincip, dvs. ved altid at vælge de enkleste alternativer til at designe neurale netværk, det er muligt at begrænse størrelsen af modellerne og opnå meget kompakte, men state-of-the-art neurale netværk, som er nemmere at træne, " sagde Jurie. "Dette står i kontrast til forskningstrenden med at gøre neurale netværk større og større."
Forskerne vil nu fortsætte med at udforske måder at opnå høj nøjagtighed i følelsesgenkendelse ved samtidig at analysere visuelle og auditive data, ved hjælp af de begrænsede kommenterede træningsdatasæt, der er tilgængelige i øjeblikket.
"Vi er interesserede i flere forskningsretninger, såsom hvordan man bedre kan fusionere de forskellige modaliteter, hvordan man repræsenterer følelser ved at kompakte semantisk betydningsfulde deskriptorer (og ikke kun klasseetiketter) eller hvordan man gør vores algoritmer i stand til at lære med mindre, eller endda uden, annoterede data, " sagde Jurie.
© 2018 Tech Xplore
 Varme artikler
Varme artikler
-
 Boeing indstiller produktionen i Washington -kompleksetBoeing 777 samlebåndet i Everett, Washington er afbilledet i 2012 Boeing meddelte mandag, at det midlertidigt vil standse produktionen på et fabrikskompleks i staten Washington, der fremstiller la
Boeing indstiller produktionen i Washington -kompleksetBoeing 777 samlebåndet i Everett, Washington er afbilledet i 2012 Boeing meddelte mandag, at det midlertidigt vil standse produktionen på et fabrikskompleks i staten Washington, der fremstiller la -
 Tre udfordringer for vindenergipotentialetVindenergiens store videnskabelige udfordringer spænder over store skalaer både med hensyn til rum og tid. At mestre fysikken og imødekomme de relaterede forskningsbehov på tværs af disse skalaer vil
Tre udfordringer for vindenergipotentialetVindenergiens store videnskabelige udfordringer spænder over store skalaer både med hensyn til rum og tid. At mestre fysikken og imødekomme de relaterede forskningsbehov på tværs af disse skalaer vil -
 Social engineering driver cyberkriminalitet mod virksomhederI denne 27. aug. 2019 foto, Tyler Olson poserer på sit kontor på University of St. Thomas - Minneapolis campus. Olson er lige ved at starte et cybersikkerhedsfirma. (AP Photo/Jim Mone) Den cyberkr
Social engineering driver cyberkriminalitet mod virksomhederI denne 27. aug. 2019 foto, Tyler Olson poserer på sit kontor på University of St. Thomas - Minneapolis campus. Olson er lige ved at starte et cybersikkerhedsfirma. (AP Photo/Jim Mone) Den cyberkr -
 Titanic -kampen om Sky kulminerer på auktionVelkommen til en sjælden auktion En titanisk overtagelseskamp for den europæiske tv -operatør Sky mellem Rupert Murdochs 21. århundrede Fox og den amerikanske kabelgigant Comcast kulminerer lørdag
Titanic -kampen om Sky kulminerer på auktionVelkommen til en sjælden auktion En titanisk overtagelseskamp for den europæiske tv -operatør Sky mellem Rupert Murdochs 21. århundrede Fox og den amerikanske kabelgigant Comcast kulminerer lørdag
- Verdens hurtigste eksfoliering af materiale kan bruges til produktion af fotoaktuatorer
- Hjælperobot lærer at fodre
- Foreslået kvante-nano-MRI kunne generere billeder med opløsning på angstrom-niveau
- Amerikansk politis racistiske rødder:Fra slavepatruljer til trafikstop
- ABS af molekylære motorer
- Routing af dal exciton-emission af et monolag via in-plane inversion-symmetri brudte PhC-plader