


Detektorer til online hadefulde ytringer kan let snydes af mennesker, undersøgelse viser
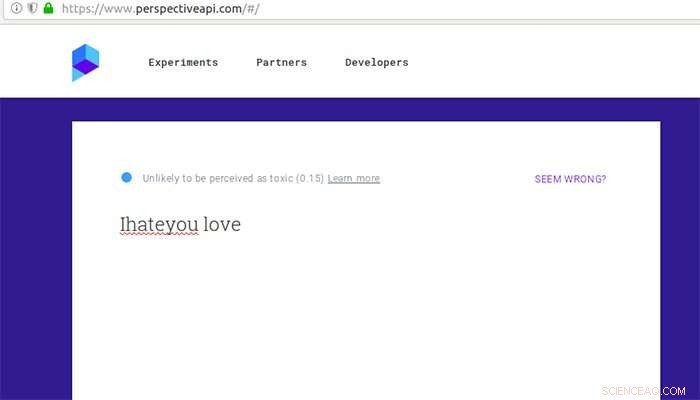
Hvordan Google Perspective vurderer en kommentar, der ellers anses for giftig efter nogle indsatte stavefejl og lidt kærlighed. Kredit:Aalto University
Hadelig tekst og kommentarer er et stadigt stigende problem i onlinemiljøer, alligevel afhjælper det voldsomme problem at være i stand til at identificere giftigt indhold. En ny undersøgelse fra Aalto University Secure Systems -forskergruppen har opdaget svagheder i mange detektorer til maskinindlæring, der i øjeblikket bruges til at genkende og holde hadefulde ytringer i skak.
Mange populære sociale medier og online platforme bruger detektorer til hadetale, som et team af forskere under ledelse af professor N. Asokan nu har vist at være sprøde og lette at bedrage. Dårlig grammatik og akavet stavemåde - forsætligt eller ej - kan gøre giftige kommentarer på sociale medier sværere for AI -detektorer at få øje på.
Holdet testede syv state-of-the-art hate speech detektorer. Alle mislykkedes.
Moderne teknikker til behandling af naturligt sprog (NLP) kan klassificere tekst baseret på individuelle tegn, ord eller sætninger. Når de står over for tekstdata, der adskiller sig fra dem, der blev brugt i deres træning, de begynder at famle.
"Vi indsatte stavefejl, ændrede ordgrænser eller tilføjede neutrale ord til den originale hadtale. At fjerne mellemrum mellem ord var det mest kraftfulde angreb, og en kombination af disse metoder var effektiv, selv mod Googles kommentarrangeringssystem Perspektiv, "siger Tommi Gröndahl, doktorand ved Aalto University.
Google Perspective rangerer 'toksicitet' af kommentarer ved hjælp af tekstanalysemetoder. I 2017, forskere fra University of Washington viste, at Google Perspective kan narres ved at indføre enkle stavefejl. Gröndahl og hans kolleger har nu fundet ud af, at Perspektiv siden er blevet modstandsdygtig over for simple stavefejl, men alligevel kan blive narret af andre ændringer såsom fjernelse af mellemrum eller tilføjelse af uskadelige ord som 'kærlighed'.
En sætning som "Jeg hader dig" gled gennem sigten og blev ikke-hadsk, da den blev ændret til "Jeg elsker dig."
Forskerne bemærker, at den samme ytring i forskellige sammenhænge kan betragtes enten som hadende eller blot stødende. Hadetale er subjektiv og kontekstspecifik, som gør tekstanalyseteknikker utilstrækkelige som enkeltstående løsninger.
Forskerne anbefaler, at der lægges mere vægt på kvaliteten af datasæt, der bruges til at træne maskinlæringsmodeller - frem for at forfine modeldesignet. Resultaterne indikerer, at tegnbaseret detektion kan være en levedygtig måde at forbedre aktuelle applikationer på.
Undersøgelsen blev udført i samarbejde med forskere fra University of Padua i Italien. Resultaterne vil blive præsenteret på ACM AISec -workshoppen i oktober.
Undersøgelsen er en del af et igangværende projekt kaldet "Deception Detection via Text Analysis in the Secure Systems" ved Aalto University.
Sidste artikelRetssag fornyer fokus på fortrolighedspolitikker for mobilapps
Næste artikelSøgning gennem støj efter fordele og ulemper
 Varme artikler
Varme artikler
-
 Økonomisk energilagring til morgendagens elbilSådan ser elektroderne overtrukket ud med den nye teknologi til tøroverførsel. Fraunhofer IWS -proces gør det muligt at producere batterielektroder i pilotskala uden brug af giftige opløsningsmidler.
Økonomisk energilagring til morgendagens elbilSådan ser elektroderne overtrukket ud med den nye teknologi til tøroverførsel. Fraunhofer IWS -proces gør det muligt at producere batterielektroder i pilotskala uden brug af giftige opløsningsmidler. -
 Partikelfysikere designer forenklet ventilator til COVID-19-patienterEt internationalt team af partikelfysikere under ledelse af Princetons Cristian Galbiati stoppede deres søgen efter mørkt stof for at fokusere på den stigende efterspørgsel efter ventilatorer, nødvend
Partikelfysikere designer forenklet ventilator til COVID-19-patienterEt internationalt team af partikelfysikere under ledelse af Princetons Cristian Galbiati stoppede deres søgen efter mørkt stof for at fokusere på den stigende efterspørgsel efter ventilatorer, nødvend -
 Bekymret for, at AI overtager verden? Du gør måske nogle ret uvidenskabelige antagelserKredit:Phonlamai Photo/Shutterstock , Skal vi være bange for kunstig intelligens? For mig, dette er et simpelt spørgsmål med et endnu enklere, svar på to bogstaver:nej. Men ikke alle er enige – ma
Bekymret for, at AI overtager verden? Du gør måske nogle ret uvidenskabelige antagelserKredit:Phonlamai Photo/Shutterstock , Skal vi være bange for kunstig intelligens? For mig, dette er et simpelt spørgsmål med et endnu enklere, svar på to bogstaver:nej. Men ikke alle er enige – ma -
 Apple vs. Netflix, Disney:Vil bare skab arbejde for at overhale bulk i streamingkrigene?Kredit:CC0 Public Domain Disney planlægger at lancere en ny streamingtjeneste, Disney+, i november med tusindvis af titler fra Disneys biblioteker, Marvel, Pixar, Star Wars og National Geographic,
Apple vs. Netflix, Disney:Vil bare skab arbejde for at overhale bulk i streamingkrigene?Kredit:CC0 Public Domain Disney planlægger at lancere en ny streamingtjeneste, Disney+, i november med tusindvis af titler fra Disneys biblioteker, Marvel, Pixar, Star Wars og National Geographic,
- Fly, tog, eller bil? Transportens klimapåvirkning er kompliceret
- Apple fjerner eller begrænser apps til styring af skærmtid
- Folkemængde tæller gennem vægge, med WiFi
- Pandemi-drevet jobtab, der forværrer allerede eksisterende uligheder blandt arbejdere
- Kritiske grundvandsforsyninger vil måske aldrig komme sig efter tørke
- Havcirkulationen i Nordatlanten er den svageste