


Facebook-forskere bygger et datasæt til at træne personlige dialogagenter
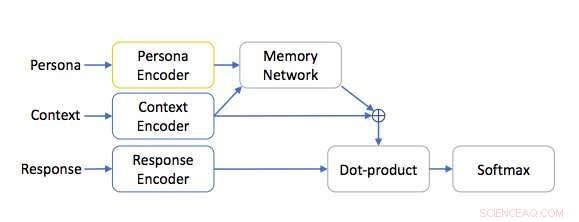
Persona-baseret netværksarkitektur. Kredit:Mazaré et al.
Forskere på Facebook har for nylig udarbejdet et datasæt med 5 millioner personas og 700 millioner persona-baserede dialoger. Denne database kan bruges til at træne ende-til-ende dialogsystemer, resulterer i mere engagerende og rige dialoger mellem computeragenter og mennesker.
Dialogsystemer, eller samtaleagenter (CA), er computersystemer designet til at kommunikere med mennesker via tekst, tale, grafik, eller andre metoder, på en sammenhængende måde. Indtil nu, dialogsystemer baseret på neurale arkitekturer, såsom LSTM'er eller hukommelsesnetværk, har vist sig at være særligt lovende med hensyn til at opnå flydende kommunikation, især når de trænes direkte på dialog logs.
"En af deres vigtigste fordele er, at de kan stole på store datakilder fra eksisterende dialoger for at lære at dække forskellige domæner uden at kræve ekspertviden, " skrev forskerne i deres papir, som blev forudgivet på arXiv. "Imidlertid, bagsiden er, at de også udviser begrænset engagement, især i chit-chat-indstillinger:De mangler konsistens og udnytter ikke proaktive engagementsstrategier, som (selv delvist) scriptede chatbots gør."
I en nylig undersøgelse, et andet team af forskere ved Montreal Institute for Learning Algorithms (MILA) og Facebook AI skabte et datasæt kaldet PERSONA-CHAT, som omfatter dialoger mellem agenter med tekstprofiler, eller personas, knyttet til dem. De fandt ud af, at træning af et dialogsystem om en bestemt persona forbedrede deres engagement i interaktioner.
"Imidlertid, PERSONA-CHAT-datasættet blev oprettet ved hjælp af en kunstig dataindsamlingsmekanisme baseret på Mechanical Turk, " forklarede forskerne i deres papir. "Som et resultat, hverken dialogbokse eller personaer kan være fuldt repræsentative for ægte bruger-bot-interaktioner, og datasættets dækning forbliver begrænset, indeholdende lidt mere end 1k forskellige personas."
For at løse begrænsningerne ved det tidligere kompilerede datasæt, Facebook-forskerne skabte en ny, storstilet personbaseret dialogdatasæt, sammensat af samtaler hentet fra online platform Reddit. Deres undersøgelse tager deres forgængeres arbejde et skridt videre, ved at bruge mere repræsentative interaktioner.
"I denne avis, vi bygger et meget storstilet personbaseret dialogdatasæt ved hjælp af samtaler, der tidligere er udtrukket fra Reddit, " skrev forskerne. "Med simpel heuristik, vi skaber et korpus på over 5 millioner personas, der spænder over mere end 700 millioner samtaler."
For at evaluere dets effektivitet, forskerne trænede personbaserede end-to-end dialogsystemer på deres nyudviklede datasæt. Systemer trænet på deres datasæt var i stand til at føre mere engagerende samtaler, udkonkurrerede andre samtaleagenter, der ikke havde adgang til personas under deres uddannelse.
Interessant nok, deres datasæt førte til avancerede resultater, selv når dialogsystemer blot var fortrænede på det. I fremtiden, disse resultater kan føre til udviklingen af mere engagerende chatbots, som også kan personaliseres og trænes til at tilegne sig en bestemt persona.
"Vi viser, at træning af modeller til at tilpasse svar både med deres forfatters persona og konteksten forbedrer forudsigelsespræstationen, " skrev forskerne. "Da forudgående træning fører til betydelig forbedring af ydeevnen, fremtidigt arbejde kunne finjustere denne model til forskellige dialogsystemer."
© 2018 Tech Xplore
Sidste artikelEn ny tilgang til at forbedre batteriets ydeevne
Næste artikelSmart grids:Forbedrer modstandskraften
 Varme artikler
Varme artikler
-
 Vindtunneltests kan hjælpe drager med at blive en ren energi højflyverKredit:CC0 Public Domain Brugen af drager til at fange vindenergi og omdanne den til omkostningseffektiv grøn elektricitet kan være inden for rækkevidde, med EPSRC-finansieret forskning ved Impe
Vindtunneltests kan hjælpe drager med at blive en ren energi højflyverKredit:CC0 Public Domain Brugen af drager til at fange vindenergi og omdanne den til omkostningseffektiv grøn elektricitet kan være inden for rækkevidde, med EPSRC-finansieret forskning ved Impe -
 For at stoppe falske nyheder, forskere opfordrer internetplatforme til at vælge kvalitet frem for k…Kredit:Northeastern University Falske nyheder har skabt overskrifter og domineret snak på sociale medier siden præsidentvalget i 2016. Det ser ud til at være overalt, og forskere er stadig ved at
For at stoppe falske nyheder, forskere opfordrer internetplatforme til at vælge kvalitet frem for k…Kredit:Northeastern University Falske nyheder har skabt overskrifter og domineret snak på sociale medier siden præsidentvalget i 2016. Det ser ud til at være overalt, og forskere er stadig ved at -
 Sådan lærer en computer at drible:Øv, øve sig, øve sigForskere ved Carnegie Mellon University og DeepMotion Inc., et californisk firma, der udvikler smarte avatarer, har for første gang udviklet en fysik-baseret, realtidsmetode til at styre animerede kar
Sådan lærer en computer at drible:Øv, øve sig, øve sigForskere ved Carnegie Mellon University og DeepMotion Inc., et californisk firma, der udvikler smarte avatarer, har for første gang udviklet en fysik-baseret, realtidsmetode til at styre animerede kar -
 Nye modeller mærker menneskelig tillid til smarte maskinerHvordan skal intelligente maskiner designes, så de tjener menneskers tillid? Nye modeller informerer disse designs. Kredit:Purdue University foto/Marshall Farthing Nye klassifikationsmodeller forn
Nye modeller mærker menneskelig tillid til smarte maskinerHvordan skal intelligente maskiner designes, så de tjener menneskers tillid? Nye modeller informerer disse designs. Kredit:Purdue University foto/Marshall Farthing Nye klassifikationsmodeller forn
- AI-teknologi forbedrer kritisk revnedetektion i atomreaktorer, broer, bygninger
- Elcykler nynner snart langs nationalparkens stier
- Udvikleren stopper planer efter sandsynlige borgerkrigsgrave fundet
- En ny, databaseret tjekliste for at øge kvinder i videnskabelig ledelse
- Oversvømmelser og tårer i Bangladesh en uge efter cyklonen
- Magt til folket:Hvordan hverdagslige trodshandlinger kan forme og ændre markeder