


En evaluering af afvejningerne mellem nøjagtighed og effektivitet af neurale sprogmodeller
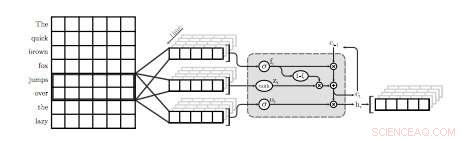
En illustration af det første QRNN-lag til sprogmodellering. I denne visualisering, et QRNN-lag med en vinduesstørrelse på to konvolver og puljer ved hjælp af indlejringer fra input. Bemærk fraværet af tilbagevendende vægte. Kredit:Tang &Lin.
Et team af forskere ved University of Waterloo i Canada har for nylig udført en undersøgelse, der udforsker nøjagtighed-effektivitet afvejninger af neurale sprogmodeller (NLM'er), der specifikt anvendes på mobile enheder. I deres papir, som blev forudgivet på arXiv, forskerne foreslog også en simpel teknik til at genvinde en vis forvirring, et mål for en sprogmodels ydeevne, bruger en ubetydelig mængde hukommelse.
NLM'er er sprogmodeller baseret på neurale netværk, hvorigennem algoritmer kan lære den typiske fordeling af ordsekvenser og lave forudsigelser om det næste ord i en sætning. Disse modeller har en række nyttige anvendelser, for eksempel, muliggør smartere softwaretastaturer til mobiltelefoner eller andre enheder.
"Neurale sprogmodeller (NLM'er) eksisterer i et afvejningsrum for nøjagtighed og effektivitet, hvor bedre forvirring typisk kommer på bekostning af større beregningskompleksitet, " skrev forskerne i deres papir. "I en softwaretastaturapplikation på mobile enheder, dette udmønter sig i højere strømforbrug og kortere batterilevetid."
Når det anvendes på softwaretastaturer, NLM'er kan føre til mere nøjagtig forudsigelse af næste ord, giver brugerne mulighed for at indtaste det næste ord i en given sætning med et enkelt tryk. To eksisterende applikationer, der bruger neurale netværk til at levere denne funktion, er SwiftKey1 og Swype2. Imidlertid, disse applikationer kræver ofte meget strøm for at fungere, hurtigt aflade batterierne på mobile enheder.
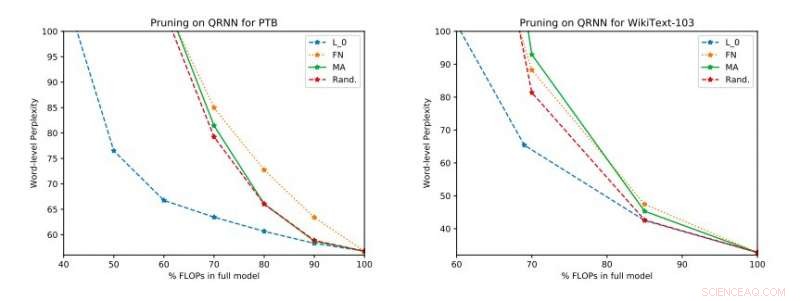
Fuldstændige eksperimentelle resultater på Penn Treebank og WikiText-103. Vi illustrerer forvirring-effektivitets-afvejningen på testsættet, der blev opnået før anvendelse af enkeltrangsopdateringen. Kredit:Tang &Lin.
"Baseret på standardmålinger som forvirring, neurale teknikker repræsenterer et fremskridt inden for den nyeste sprogmodellering, " forklarede forskerne i deres papir. "Bedre modeller, imidlertid, komme til en pris i beregningsmæssig kompleksitet, hvilket betyder højere strømforbrug. I forbindelse med mobile enheder, energieffektivitet er, selvfølgelig, et vigtigt optimeringsmål."
Ifølge forskerne, NLM'er er hidtil primært blevet evalueret i forbindelse med billedgenkendelse og søgeordspotting, mens deres afvejning mellem nøjagtighed og effektivitet i applikationer til naturlig sprogbehandling (NLP) endnu ikke er blevet grundigt undersøgt. Deres undersøgelse fokuserer på dette uudforskede forskningsområde, udfører en evaluering af NLM'er og deres afvejninger mellem nøjagtighed og effektivitet på en Raspberry Pi.
"Vores empiriske evalueringer overvejer både forvirring og energiforbrug på en Raspberry Pi, hvor vi demonstrerer, hvilke metoder der giver det bedste driftspunkt for forvirring-strømforbrug, " sagde forskerne. "På et operationspunkt, en af teknikkerne er i stand til at give energibesparelser på 40 procent i forhold til de avancerede [metoder] med kun en relativ stigning på 17 procent i forvirring."
I deres undersøgelse, forskerne evaluerede også en række inferens-tidsbeskæringsteknikker på kvasi-tilbagevendende neurale netværk (QRNN'er). Udvidelse af anvendeligheden af eksisterende beskæringsmetoder i træningstid til QRNN'er under kørsel, de opnåede adskillige driftspunkter inden for afvejningsområdet for nøjagtighed og effektivitet. For at forbedre ydeevnen ved at bruge en lille mængde hukommelse, de foreslog træning og lagring af single-rank vægtopdateringer på ønskede operationspunkter.
© 2018 Tech Xplore
 Varme artikler
Varme artikler
-
 Algoritmer har allerede overtaget menneskelig beslutningstagningKredit:Robsonphoto/Shutterstock Jeg kan stadig huske min overraskelse, da en bog af evolutionsbiolog Peter Lawrence hed Fremstilling af en flue kom til at blive prissat på Amazon til $23, 698, 6
Algoritmer har allerede overtaget menneskelig beslutningstagningKredit:Robsonphoto/Shutterstock Jeg kan stadig huske min overraskelse, da en bog af evolutionsbiolog Peter Lawrence hed Fremstilling af en flue kom til at blive prissat på Amazon til $23, 698, 6 -
 Den schweiziske regering tilbyder belønning for at hacke sit elektroniske stemmesystemDe schweiziske myndigheder håber, at øvelsen fuldt ud vil teste sikkerheden af den nye generation af elektroniske afstemningssystem Den schweiziske regering har udstedt en 150, 000 schweizerfran
Den schweiziske regering tilbyder belønning for at hacke sit elektroniske stemmesystemDe schweiziske myndigheder håber, at øvelsen fuldt ud vil teste sikkerheden af den nye generation af elektroniske afstemningssystem Den schweiziske regering har udstedt en 150, 000 schweizerfran -
 Hotelværelsespriser:Menneskearbejde eller algoritmisk legetøj?Kredit:CC0 Public Domain Du vil gerne booke et hotelværelse og surfe på internettet, for hvilke værelser og priser er et tilbud. Priserne afhænger af den forventede efterspørgsel og opstår ved bru
Hotelværelsespriser:Menneskearbejde eller algoritmisk legetøj?Kredit:CC0 Public Domain Du vil gerne booke et hotelværelse og surfe på internettet, for hvilke værelser og priser er et tilbud. Priserne afhænger af den forventede efterspørgsel og opstår ved bru -
 Ghosn modtog 8 millioner euro i uretmæssige betalinger:NissanGhosn er anklaget for flere tilfælde af økonomisk uredelighed Tidligere Nissan-chef Carlos Ghosn modtog næsten otte millioner euro i upassende betalinger fra et hollandsk-baseret joint venture, de
Ghosn modtog 8 millioner euro i uretmæssige betalinger:NissanGhosn er anklaget for flere tilfælde af økonomisk uredelighed Tidligere Nissan-chef Carlos Ghosn modtog næsten otte millioner euro i upassende betalinger fra et hollandsk-baseret joint venture, de
- Næste amerikanske astronaut på russisk raket selvsikker efter uheld
- Forskere etablerer grundlaget for udvikling af hvirveldyrs lemmermuskler hos bruskfisk
- Afkodning af digitalt ejerskab:Hvorfor din e-bog måske ikke føles som din
- Hvad forårsager lyden af en dryppende hane - og hvordan stopper du den?
- Ethiopian Airlines crash:Hvad er MCAS -systemet på Boeing 737 Max 8?
- Astronomer afslører indsigt i naturen af en fjern ultraviolet-lys stjerne