


Mod sprogslutning i medicin

Forespørgsel vist til klinikere for kommentarer. Kredit:IBM
Den seneste tid har været vidne til betydelige fremskridt inden for naturlig sprogforståelse af AI, såsom maskinoversættelse og besvarelse af spørgsmål. En afgørende årsag bag denne udvikling er oprettelsen af datasæt, som bruger maskinlæringsmodeller til at lære og udføre en specifik opgave. Konstruktion af sådanne datasæt i det åbne domæne består ofte af tekst, der stammer fra nyhedsartikler. Dette efterfølges typisk af indsamling af menneskelige annoteringer fra crowd-sourcing platforme såsom Crowdflower, eller Amazon Mechanical Turk.
Imidlertid, sprog, der bruges i specialiserede domæner såsom medicin, er helt anderledes. Ordforrådet, som en læge bruger, mens han skriver en klinisk note, er helt ulig ordene i en nyhedsartikel. Dermed, sprogopgaver i disse videnintensive domæner kan ikke crowd-sources, da sådanne annoteringer kræver domæneekspertise. Imidlertid, Det er også meget dyrt at indsamle annotationer fra domæneeksperter. I øvrigt, kliniske data er privatlivsfølsomme og kan derfor ikke nemt deles. Disse forhindringer har hæmmet bidraget fra sprogdatasæt i det medicinske domæne. På grund af disse udfordringer, validering af højtydende algoritmer fra det åbne domæne på kliniske data forbliver uundersøgt.
For at afhjælpe disse huller, vi arbejdede med Massachusetts Institute of Technology for at bygge MedNLI, et datasæt kommenteret af læger, udfører en naturlig sproginferens (NLI) opgave og er baseret på patienters sygehistorie. Mest vigtigt, vi gør det offentligt tilgængeligt for forskere at fremme naturlig sprogbehandling i medicin.
Vi arbejdede sammen med MIT Critical Data-forskningslaboratorier for at konstruere et datasæt til naturlig sproginferens i medicin. Vi brugte kliniske noter fra deres "Medical Information Mart for Intensive Care" (MIMIC) database, som uden tvivl er den største offentligt tilgængelige database med patientjournaler. Klinikerne i vores team foreslog, at en patients tidligere sygehistorie indeholder vital information, hvorfra der kan drages nyttige slutninger. Derfor, vi udtog den tidligere sygehistorie fra kliniske noter i MIMIC og præsenterede en sætning fra denne historie som en præmis for en kliniker. De blev derefter bedt om at bruge deres medicinske ekspertise og generere tre sætninger:en sætning, der bestemt var sand om patienten, givet præmissen; en sætning, der bestemt var falsk, og til sidst en sætning, der muligvis kunne være sand.
Over et par måneder, vi udtog tilfældigt 4, 683 sådanne lokaler og arbejdede sammen med fire klinikere for at konstruere MedNLI, et datasæt på 14, 049 præmis-hypotese-par. I det åbne domæne, andre eksempler på lignende opbyggede datasæt inkluderer Stanford Natural Language Inference-datasættet, som blev kurateret ved hjælp af 2, 500 arbejdere på Amazon Mechanical Turk og består af 0,5 millioner præmis-hypotese-par, hvor præmisssætninger blev tegnet fra billedtekster af Flickr-billeder. MultiNLI er en anden og består af præmistekst fra specifikke genrer såsom fiktion, blogs, telefonsamtaler, etc.
Dr. Leo Anthony Celi (Principal Scientist for MIMIC) og Dr. Alistair Johnson (Research Scientist) fra MIT Critical Data arbejdede sammen med os for at gøre MedNLI offentligt tilgængeligt. De skabte MIMIC-afledte datalageret, hvortil MedNLI fungerede som det første bidrag til datasæt til behandling af naturligt sprog. Enhver forsker med adgang til MIMIC kan også downloade MedNLI fra dette lager.
Selvom det er af en beskeden størrelse sammenlignet med de åbne domænedatasæt, MedNLI er stor nok til at informere forskere, når de udvikler nye maskinlæringsmodeller til sprogslutning i medicin. Mest vigtigt, det giver interessante udfordringer, der kræver innovative ideer. Overvej et par eksempler fra MedNLI:
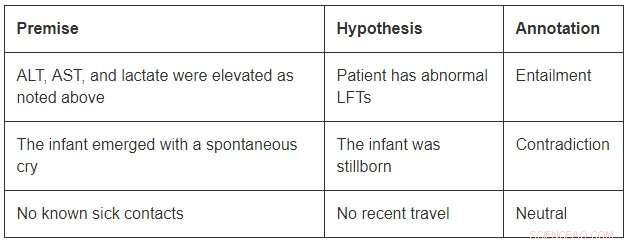
For at konkludere medførslen i det første eksempel, man skal kunne udvide forkortelserne ALT, AST, og LFT'er; forstå, at de er beslægtede; og konkluderer endvidere, at en forhøjet måling er unormal. Det andet eksempel skildrer en subtil slutning om at konkludere, at fremkomsten af et spædbarn er en beskrivelse af dets fødsel. Endelig, det sidste eksempel viser, hvordan almindelig verdensviden bruges til at udlede slutninger.
State-of-the-art dyb læringsalgoritmer kan præstere meget på sprogopgaver, fordi de har potentialet til at blive meget gode til at lære en nøjagtig kortlægning fra input til output. Dermed, træning på et stort datasæt kommenteret ved hjælp af crowd-sourcede annoteringer er ofte en opskrift på succes. Imidlertid, de mangler stadig generaliseringsevner under forhold, der adskiller sig fra dem, man støder på under træning. Dette er endnu mere udfordrende inden for specialiserede og videntunge områder som medicin, hvor træningsdata er begrænset, og sproget er meget mere nuanceret.
Endelig, selvom der er gjort store fremskridt med at lære en sprogopgave ende-til-ende, der er stadig behov for yderligere teknikker, der kan inkorporere ekspertudvalgte videnbaser i disse modeller. For eksempel, SNOMED-CT er en ekspertudvalgt medicinsk terminologi med 300K+ koncepter og relationer mellem termerne i sit datasæt. Inden for MedNLI, vi lavede enkle ændringer af eksisterende dybe neurale netværksarkitekturer for at tilføre viden fra vidensbaser såsom SNOMED-CT. Imidlertid, en stor mængde viden er stadig uudnyttet.
Vi håber, at MedNLI åbner op for nye forskningsretninger i det naturlige sprogbehandlingssamfund.
Denne historie er genudgivet med tilladelse fra IBM Research. Læs den originale historie her.
 Varme artikler
Varme artikler
-
 Hvordan Samsung Galaxy S9 stabler op til iPhone X, 8, PixelNæste uge, iPhone X har en ny konkurrent. Den 16. marts, Samsung lancerer Galaxy S9 og S9+, det nye flagskib Android -håndsæt fra den sydkoreanske elektronikgigant. Smartphones fås hos alle fire st
Hvordan Samsung Galaxy S9 stabler op til iPhone X, 8, PixelNæste uge, iPhone X har en ny konkurrent. Den 16. marts, Samsung lancerer Galaxy S9 og S9+, det nye flagskib Android -håndsæt fra den sydkoreanske elektronikgigant. Smartphones fås hos alle fire st -
 Uber trækker sig tilbage på værdiansættelsen med børsnoteringspriserRide-hilling-giganten Uber kan være omkring 83 milliarder dollar værd efter sit aktieudbud - en stor værdiansættelse, men under nogle tidligere mål Uber trak sig tilbage på sit ambitiøse værdiansæ
Uber trækker sig tilbage på værdiansættelsen med børsnoteringspriserRide-hilling-giganten Uber kan være omkring 83 milliarder dollar værd efter sit aktieudbud - en stor værdiansættelse, men under nogle tidligere mål Uber trak sig tilbage på sit ambitiøse værdiansæ -
 Storbritannien venter på USA før Huawei 5G-beslutningenStorbritannien har sagt, at det endnu ikke er i en position til at beslutte, hvilken involvering Kinas Huawei skal have i Storbritanniens 5G næste generations telenetværk Storbritannien sagde mand
Storbritannien venter på USA før Huawei 5G-beslutningenStorbritannien har sagt, at det endnu ikke er i en position til at beslutte, hvilken involvering Kinas Huawei skal have i Storbritanniens 5G næste generations telenetværk Storbritannien sagde mand -
 Fair trade:Din sjæl for data?Kredit:CC0 Public Domain I en stadig mere datadrevet verden, er vi bare gående datakilder til gavn for gigantiske multinationale selskaber? Hvert minut, der er 3,8 millioner søgeforespørgsler på
Fair trade:Din sjæl for data?Kredit:CC0 Public Domain I en stadig mere datadrevet verden, er vi bare gående datakilder til gavn for gigantiske multinationale selskaber? Hvert minut, der er 3,8 millioner søgeforespørgsler på
- Et andet syn på årsagerne til ulighed
- Konstruktion af praktiske kvantecomputere radikalt forenklet
- NASAs Europa Clipper bygger hardware, bevæger sig mod samling
- Billede:Røntgenkilder i XMM-Newtons andet katalog
- Mindst 13% af spildevandet, der behandles af septiske systemer i det sydlige Ontario, ender i vandlø…
- Grundlæggende opdagelse kan føre til bedre hukommelseschips