


Skalerbare prognoser for IoT i skyen
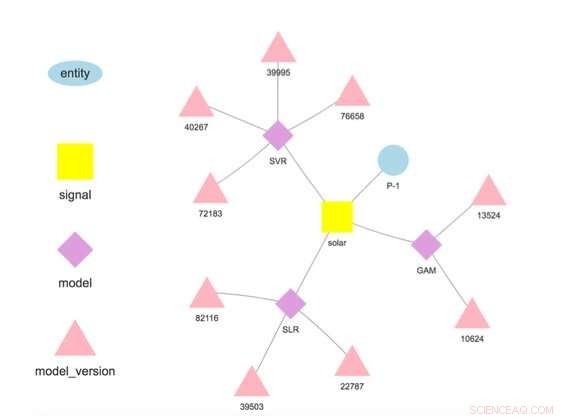
Figur 1. Modelhierarki for en valgt enhed og signal. Kredit:IBM
Denne uge på den internationale konference om datamining, IBM Research-Ireland videnskabsmand Francesco Fusco demonstrerede IBM Research Castor, et system til styring af tidsseriedata og modeller i skala og i skyen. Virksomheder i dag kører på prognoser. Uanset om en anelse om, hvad vi tror vil ske, eller et produkt af omhyggeligt finpudset analyse, vi har et billede af, hvad der kommer til at ske, og vi handler derefter. IBM Research Castor er til IoT-drevne virksomheder, der har brug for hundredvis eller tusindvis af forskellige prognoser for tidsserier. Selvom modellen for en individuel prognose kan være lille, Det kan være en udfordring at holde trit med oprindelsen og ydeevnen af dette antal modeller. I modsætning til AI-drevne cases, der bruger et lille antal store modeller til billedbehandling eller naturligt sprog, dette arbejde sigter mod IoT-applikationer, der har brug for et stort antal mindre modeller.
Vores system giver et rigt, men selektivt sæt af muligheder for tidsseriedata og -modeller. Den indtager data fra IoT-enheder eller andre kilder. Det giver adgang til data ved hjælp af semantik, giver brugerne mulighed for at hente data som dette:getTimeseries( myServer, "Store1234", "timeomsætning").
Den gemmer modeller skrevet i R eller Python til træning og scoring. Hver model er forbundet med en enhed, der beskriver, hvor dataene stammer fra, ligesom "Store1234" ovenfor, og et signal, der beskriver, hvad der måles, som "timeomsætning". Modeller trænes og bedømmes ved brugerdefinerede frekvenser, og i modsætning til mange andre tilbud, prognoserne gemmes automatisk.
Dataforskere implementerer modeller ved at implementere en fire-trins arbejdsgang:
- Indlæs data til træning eller scoring fra relevante datakilder;
- Transformér disse data til en dataramme til modeltræning eller scoring;
- Træn modellen for at få en version, der er egnet til at lave prognoser; og
- Score modellen for at forudsige mængder af interesse.
Når modellen er implementeret, systemet udfører træning og scoring, automatisk lagring af den trænede model og prognoseresultater. Data brugt til træning og scoring behøver ikke at stamme fra platformen, giver modeller mulighed for at bruge data fra flere kilder. Faktisk, dette er en nøglemotivation for vores arbejde – at lave værdiskabende prognoser baseret på flere datakilder. For eksempel, en virksomhed kan kombinere nogle af sine egne data med data købt fra en tredjepart, såsom vejrudsigter, at forudsige en mængde af interesse.
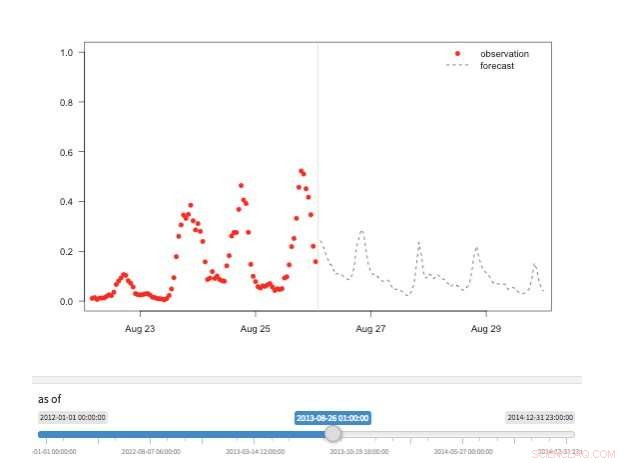
Figur 2. "Tidsmaskine"-visning, der viser tilgængelige observationer og prognoser for forskellige punkter i historien. Kredit:IBM
Vores system gemmer modeller adskilt fra konfigurations- og runtime-parametre. Denne adskillelse gør det muligt at ændre nogle detaljer i en model, såsom API-nøglen til at få adgang til tredjepartsdata eller scoringsfrekvensen, uden omplacering. Flere modeller for den samme målvariabel understøttes og opmuntres til at muliggøre sammenligninger af prognoser fra forskellige algoritmer. Modeller kan kædes sammen, så output fra én model danner input til en anden som i et ensemble. En model trænet på et specifikt datasæt repræsenterer en modelversion, som også spores. Det er således muligt at fastslå herkomsten af modeller og prognoser (figur 1).
Flere visninger er tilgængelige for at udforske prognoseværdier. Selve værdierne kan naturligvis genfindes og visualiseres. Vi understøtter også en "tidsmaskine"-visning, der viser de seneste prognoser og seneste observationer (figur 2). I denne interaktive visning, brugeren kan vælge forskellige punkter i historien og se, hvilke oplysninger der var tilgængelige på det tidspunkt. Vi støtter også et syn på prognoseudvikling, der viser successive prognoser for det samme tidspunkt (figur 3). På denne måde kan brugerne se, hvordan prognoserne ændrede sig, efterhånden som måltidspunktet kom tættere på.
Under kølerhjelmen, IBM Research Castor gør stor brug af serverløs computing for at give ressourceelasticitet og omkostningskontrol. Typiske implementeringer ser modeller trænet hver uge eller hver måned og scoret hver time. Ved træning eller scoringstid, der oprettes en serverløs funktion for hver model, giver hundredvis af modeller mulighed for at træne eller score parallelt på det ønskede tidspunkt. Efter dette arbejde er slut, computerressourcen forsvinder, indtil den er nødvendig igen. I en mere konventionel arbejdsgang, virtuelle maskiner eller cloud-containere er inaktive, når de ikke er i brug, men stadig tiltrækker omkostninger.
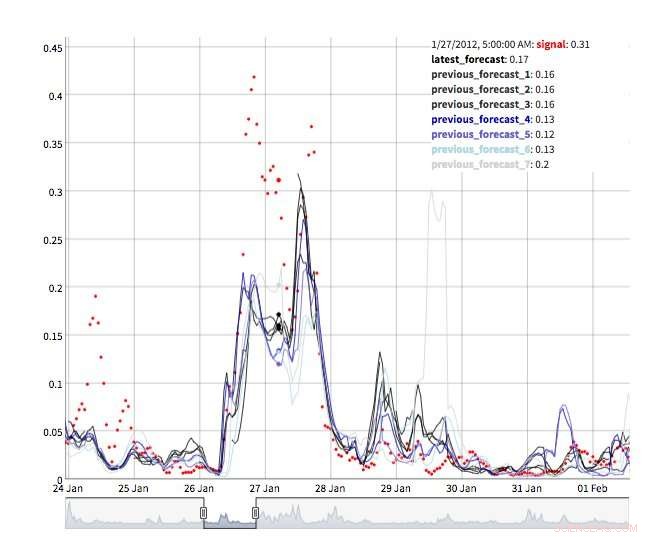
Figur 3. Forecast evolution. Kredit:IBM
IBM Research Castor implementerer indbygget på IBM Cloud ved hjælp af de nyeste tjenester såsom IBM's DashDB, Skriv, Cloud funktioner, og Kubernetes for at levere et robust og pålideligt system. Med en berettiget konto på IBM Cloud, IBM Research Castor implementerer i løbet af få minutter, hvilket gør den ideel til proof-of-concept såvel som længerevarende projekter. Klientpakker/SDK'er til Python og R leveres, så dataforskere kan komme hurtigt i gang i et velkendt miljø, og visualiseringsteams kan udnytte velkendte rammer såsom Django og Shiny. Hvis disse ikke passer til din ansøgning, den JSON-baserede messaging API er også tilgængelig.
Denne historie er genudgivet med tilladelse fra IBM Research. Læs den originale historie her.
 Varme artikler
Varme artikler
-
 Bilsalget i Storbritannien er steget efter årelange fald:industriTo britiske byggede biler, en Bentley Flying Spur og en Range Rover, afbilledet i London i 2015 Storbritanniens salg af nye biler steg en smule i april, industridata viste fredag, et år tidligere
Bilsalget i Storbritannien er steget efter årelange fald:industriTo britiske byggede biler, en Bentley Flying Spur og en Range Rover, afbilledet i London i 2015 Storbritanniens salg af nye biler steg en smule i april, industridata viste fredag, et år tidligere -
 Brug af maskinlæring til at rekonstruere forringede Van Gogh-tegningerKredit:Zeng, van der Lubbe &Loog. Forskere ved TU Delft i Holland har for nylig udviklet en konvolutionelt neuralt netværk (CNN)-baseret model til at rekonstruere tegninger, der er blevet forringe
Brug af maskinlæring til at rekonstruere forringede Van Gogh-tegningerKredit:Zeng, van der Lubbe &Loog. Forskere ved TU Delft i Holland har for nylig udviklet en konvolutionelt neuralt netværk (CNN)-baseret model til at rekonstruere tegninger, der er blevet forringe -
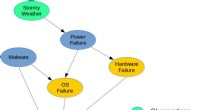 En ny løser til omtrentlig marginal kortslutningFigur 1. Et simpelt Bayesiansk netværk til en systemdiagnoseopgave. Kredit:IBM Der er en dyb forbindelse mellem planlægning og slutning, og i løbet af det sidste årti, flere forskere har introduce
En ny løser til omtrentlig marginal kortslutningFigur 1. Et simpelt Bayesiansk netværk til en systemdiagnoseopgave. Kredit:IBM Der er en dyb forbindelse mellem planlægning og slutning, og i løbet af det sidste årti, flere forskere har introduce -
 Sådan navigerer du i tilbudet om afvikling af Equifax -databrudCaliforniens statsadvokat Xavier Becerra diskuterer det forlig, der blev indgået med Equifax i forbindelse med et databrud i 2017, under et pressemøde i Sacramento, Californien, Mandag, 22. juli kl. 2
Sådan navigerer du i tilbudet om afvikling af Equifax -databrudCaliforniens statsadvokat Xavier Becerra diskuterer det forlig, der blev indgået med Equifax i forbindelse med et databrud i 2017, under et pressemøde i Sacramento, Californien, Mandag, 22. juli kl. 2
- Colorados berømte asper forventes at falde på grund af klimaændringer
- Kan sandpapir tænde en tændstik?
- Nanopartikler som en mulig løsning på antibiotikaresistens
- Gulds vaklende kerne:Hvad den kortlivede Au187-isotop lærer os om grundlæggende videnskabelig fors…
- Amazon laver sjov ved fejl, siger teknologiske gadgets populære
- Supercomputere hjælper med nye simuleringer af forskning i gammastrålegenerering