


Hvordan vi byggede et værktøj, der opdager styrken ved islamofobisk hadefuld tale på Twitter

Find, og måling af islamofobi hadefulde ytringer på sociale medier. Kredit:John Gomez/Shutterstock
I et skelsættende træk, en gruppe parlamentsmedlemmer offentliggjorde for nylig en arbejdsdefinition af udtrykket islamofobi. De definerede det som "forankret i racisme", og som "en form for racisme, der retter sig mod udtryk for muslimisme eller opfattet muslimitet".
I vores seneste arbejdspapir, vi ønskede bedre at forstå forekomsten og sværhedsgraden af sådanne islamofobiske hadytringer på sociale medier. Sådan tale skader målrettede ofre, skaber en følelse af frygt blandt muslimske samfund, og er i strid med grundlæggende principper for retfærdighed. Men vi stod over for en central udfordring:selvom det var ekstremt skadeligt, Islamofobisk hadtale er faktisk ret sjælden.
Milliarder af indlæg sendes hver dag på sociale medier, og kun et meget lille antal af dem indeholder enhver form for had. Så vi gik i gang med at oprette et klassificeringsværktøj ved hjælp af machine learning, der automatisk registrerer, om tweets indeholder islamofobi eller ej.
Opdagelse af islamofobisk hadtale
Der er gjort enorme fremskridt med at bruge maskinlæring til at klassificere mere generel hadetale robust, i omfang og rettidigt. I særdeleshed, der er gjort store fremskridt med at kategorisere indhold baseret på, om det er hadefuldt eller ej.
Men islamofobisk hadtale er meget mere nuanceret og kompleks end dette. Det kører spektret fra verbalt angreb, misbruge og fornærme muslimer til at ignorere dem; fra at fremhæve, hvordan de opfattes som "forskellige" til at antyde, at de ikke er legitime medlemmer af samfundet; fra aggression til afskedigelse. Vi ville tage denne nuance i betragtning med vores værktøj, så vi kunne kategorisere, om indholdet er islamofobt eller ej, og om islamofobien er stærk eller svag.
Vi definerede islamofobisk hadefuld tale som "ethvert indhold, der produceres eller deles og udtrykker vilkårlig negativitet over for islam eller muslimer". Dette adskiller sig fra, men er godt i overensstemmelse med parlamentsmedlemmers arbejdsdefinition af islamofobi, skitseret ovenfor. Under vores definitioner, stærk islamofobi inkluderer udsagn som "alle muslimer er barbarer", mens svag islamofobi omfatter mere subtile udtryk, såsom "muslimer spiser sådan mærkelig mad".
At kunne skelne mellem svag og stærk islamofobi vil ikke kun hjælpe os med bedre at opdage og fjerne had, men også for at forstå dynamikken i islamofobi, undersøge radikaliseringsprocesser, hvor en person gradvist bliver mere islamofobisk, og yde bedre støtte til ofre.
Kredit:Vidgen og Yasseri
Indstilling af parametrene
Værktøjet, vi skabte, kaldes en supervised machine learning classifier. Det første trin i oprettelsen af et er at oprette et trænings- eller testdatasæt - sådan lærer værktøjet at tildele tweets til hver af klasserne:svag islamofobi, stærk islamofobi og ingen islamofobi. Oprettelse af dette datasæt er en vanskelig og tidskrævende proces, da hver tweet skal mærkes manuelt, så maskinen har et fundament at lære af. Et yderligere problem er, at detektering af hadytringer i sagens natur er subjektivt. Hvad jeg anser for stærkt islamofobisk, du tror måske er svag, og omvendt.
Vi gjorde to ting for at afbøde dette. Først, vi brugte meget tid på at lave retningslinjer for mærkning af tweets. Sekund, vi havde tre eksperter til at mærke hver tweet, og brugte statistiske tests til at kontrollere, hvor meget de var enige. Vi startede med 4, 000 tweets, udtaget fra et datasæt på 140 mio. tweets, som vi indsamlede fra marts 2016 til august 2018. De fleste af de 4, 000 tweets udtrykte ikke nogen islamofobi, så vi fjernede mange af dem for at oprette et afbalanceret datasæt, bestående af 410 stærke, 484 svage, og 447 ingen (i alt 1, 341 tweets).
Det andet trin var at bygge og indstille klassifikatoren ved hjælp af tekniske funktioner og vælge en algoritme. Funktioner er, hvad klassifikatoren bruger til faktisk at tildele hver tweet til den rigtige klasse. Vores hovedtræk var en ordindlejringsmodel, en dyb læringsmodel, der repræsenterer individuelle ord som en vektor af tal, der kan derefter bruges til at studere ordlighed og ordbrug. Vi identificerede også nogle andre funktioner fra tweets, såsom den grammatiske enhed, følelser og antallet af omtaler af moskeer.
Når vi havde bygget vores klassifikator, det sidste trin var at evaluere det, hvilket vi gjorde ved at anvende det på et nyt datasæt af helt usete tweets. Vi valgte 100 tweets tildelt hver af de tre klasser, altså 300 i alt, og fik vores tre ekspertkodere til at mærke dem igen. Dette lader os evaluere klassifikatorens ydeevne, sammenligne de etiketter, der er tildelt af vores klassifikator, med de faktiske etiketter.
Klassificeringens største begrænsning var, at den kæmpede for at identificere svage islamofobiske tweets, da disse ofte overlappede med både stærke og ingen islamofobiske tweets. Det sagt, samlet set, dens præstation var stærk. Nøjagtighed (antallet af korrekt identificerede tweets) var 77% og præcisionen var 78%. På grund af vores strenge design- og testproces, vi kan stole på, at klassifikatoren sandsynligvis vil fungere på samme måde, når den bruges i stor skala "i naturen" på usete Twitter -data.
Brug af vores klassifikator
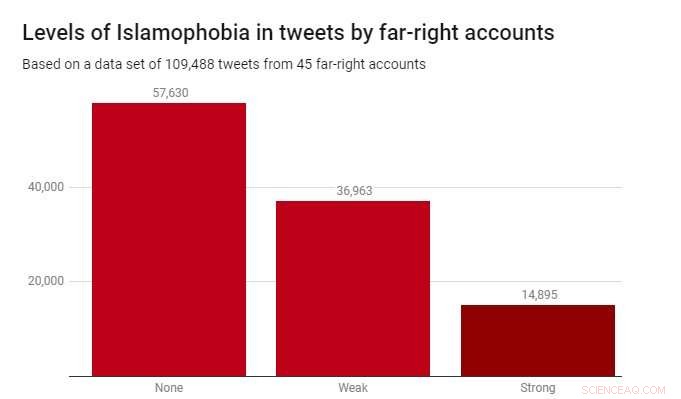
Vi anvendte klassifikatoren til et datasæt på 109, 488 tweets produceret af 45 højreekstreme konti i løbet af 2017. Disse blev identificeret af velgørende organisationen Hope Not Hate i deres 2015 og 2017 State of Hate-rapporter. Grafen herunder viser resultaterne.
Mens de fleste af tweets - 52,6% - ikke var islamofobe, svag islamofobi var betydeligt mere udbredt (33,8%) end stærk islamofobi (13,6%). Dette tyder på, at det meste af islamofobi i disse højreekstreme konti er subtil og indirekte, frem for aggressiv eller åbenlys.
At opdage islamofobisk hadtale er en reel og presserende udfordring for regeringer, teknologivirksomheder og akademikere. Desværre, dette er et problem, der ikke vil forsvinde - og der er ingen enkle løsninger. Men hvis vi er seriøse med at fjerne hadfuld tale og ekstremisme fra onlinelokaler, og gøre sociale medieplatforme sikre for alle, der bruger dem, så skal vi starte med de relevante værktøjer. Vores arbejde viser, at det er fuldt ud muligt at lave disse værktøjer-for ikke kun automatisk at opdage hadeligt indhold, men også at gøre det på en nuanceret og finkornet måde.
Denne artikel er genudgivet fra The Conversation under en Creative Commons -licens. Læs den originale artikel. 
 Varme artikler
Varme artikler
-
 Japans Hitachi fryser britisk atomprojektHitachi havde planlagt at bygge et nyt anlæg ved siden af det nedlagte Wylfa Nuclear Power Station (billedet) Hitachi sagde torsdag, at det ville fastfryse byggeriet af sit stoppede atomkraftvær
Japans Hitachi fryser britisk atomprojektHitachi havde planlagt at bygge et nyt anlæg ved siden af det nedlagte Wylfa Nuclear Power Station (billedet) Hitachi sagde torsdag, at det ville fastfryse byggeriet af sit stoppede atomkraftvær -
 Ford skal skære 7, 000 job, 10% af de globale funktionærerFord annoncerede planer om at 7, 000 job globalt, omkring 10 procent af sin arbejdsstyrke Ford planlægger at skære 7, 000 job, eller 10 procent af dens globale lønnede arbejdsstyrke, som en del af
Ford skal skære 7, 000 job, 10% af de globale funktionærerFord annoncerede planer om at 7, 000 job globalt, omkring 10 procent af sin arbejdsstyrke Ford planlægger at skære 7, 000 job, eller 10 procent af dens globale lønnede arbejdsstyrke, som en del af -
 Hvordan ingeniører retter det skæve tårn i PisaStadig smukt skrå Det er stadig ved at rette sig, sagde ingeniør Roberto Cela, stirrer på det skæve tårn i Pisa, der skinner i efterårssolen i det nordlige Italien. Og der skal gå mange år, før d
Hvordan ingeniører retter det skæve tårn i PisaStadig smukt skrå Det er stadig ved at rette sig, sagde ingeniør Roberto Cela, stirrer på det skæve tårn i Pisa, der skinner i efterårssolen i det nordlige Italien. Og der skal gå mange år, før d -
 Huawei, spærret i USA, tilbyder app -stimuleringer i EuropaDen kinesiske telegigant Huawei er i en charmeoffensiv ved den største europæiske teknologisamling, webmødet i Portugal Sortlistet i USA, Den kinesiske telekoncern Huawei er i en charmeoffensiv ve
Huawei, spærret i USA, tilbyder app -stimuleringer i EuropaDen kinesiske telegigant Huawei er i en charmeoffensiv ved den største europæiske teknologisamling, webmødet i Portugal Sortlistet i USA, Den kinesiske telekoncern Huawei er i en charmeoffensiv ve
- Astrophysicists 2004-teori bekræftede:Hvorfor Solens sammensætning varierer
- Forbedring af jordens sundhed starter med landmand-forskersamarbejde
- En ny guide til opdagelsesrejsende af den submikroskopiske verden inde i os
- Forskere har fundet ud af, hvorfor fotoner fra andre galakser ikke når Jorden
- Styrofoam Genbrug Fakta
- Cementfri flyveaskebinder gør beton grøn