


Destillerede 3-D (D3D) netværk til videohandlingsgenkendelse
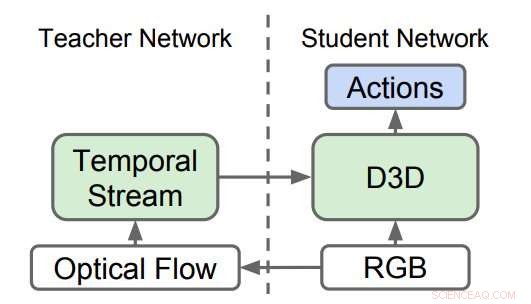
Destillerede 3D-netværk (D3D). Forskerne trænede en 3D CNN til at genkende handlinger fra RGB-video, mens de destillerede viden fra et netværk, der genkender handlinger fra optiske flowsekvenser. Under slutning, kun D3D bruges. Kredit:Stroud et al.
Et team af forskere hos Google, University of Michigan og Princeton University har for nylig udviklet en ny metode til videohandlingsgenkendelse. Videohandlingsgenkendelse indebærer identifikation af bestemte handlinger, der udføres i videooptagelser, såsom at åbne en dør, at lukke en dør, etc.
Forskere har i årevis forsøgt at lære computere at genkende menneskelige og ikke-menneskelige handlinger på video. De fleste state-of-the-art værktøjer til videohandlingsgenkendelse anvender et ensemble af to neurale netværk:den rumlige strøm og den tidsmæssige strøm.
I disse tilgange, det ene neurale netværk er trænet til at genkende handlinger i en strøm af regulære billeder baseret på udseende (dvs. den 'rumlige strøm'), og det andet netværk er trænet til at genkende handlinger i en strøm af bevægelsesdata (dvs. den 'tidslige strøm'). Resultaterne opnået af disse to netværk kombineres derefter for at opnå videohandlingsgenkendelse.
Selvom empiriske resultater opnået ved hjælp af 'to-strøm' tilgange er gode, disse metoder er afhængige af to forskellige netværk, frem for en enkelt. Formålet med undersøgelsen udført af forskerne hos Google, University of Michigan og Princeton skulle undersøge måder at forbedre dette på, for at erstatte de to strømme af de fleste eksisterende tilgange med et enkelt netværk, der lærer direkte af dataene.
I de fleste nyere undersøgelser, både rumlige og tidsmæssige strømme består af 3-D konvolutionelle neurale netværk (CNN'er), som anvender spatiotemporale filtre på videoklippet, før man forsøger at klassificere. Teoretisk set, disse anvendte tidsmæssige filtre skulle tillade den rumlige strøm at lære bevægelsesrepræsentationer, derfor burde den tidsmæssige strøm være unødvendig.
I praksis, imidlertid, ydeevnen af værktøjer til videohandlingsgenkendelse forbedres, når en helt separat tidsmæssig strøm er inkluderet. Dette tyder på, at den rumlige strøm alene ikke er i stand til at detektere nogle af de signaler, der fanges af den tidsmæssige strøm.
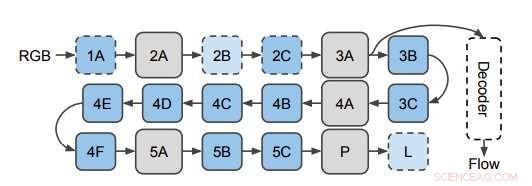
Netværket bruges til at forudsige optisk strøm fra 3D CNN -funktioner. Forskerne anvender dekoderen på skjulte lag i 3D CNN (afbildet her på lag 3A). Dette diagram viser strukturen af I3D/S3D-G, hvor blå felter repræsenterer konvolution (stiplede linjer) eller startblokke (heltrukne linjer), og grå kasser repræsenterer puljeblokke. Lagnavne er de samme som dem, der blev brugt i Inception. Kredit:Stroud et al.
For at undersøge denne observation nærmere, forskerne undersøgte, om den rumlige strøm af 3D-CNN'er til genkendelse af videohandlinger faktisk mangler bevægelsesrepræsentationer. Efterfølgende de viste, at disse bevægelsesrepræsentationer kan forbedres ved hjælp af destillation, en teknik til at komprimere viden i et ensemble til en enkelt model.
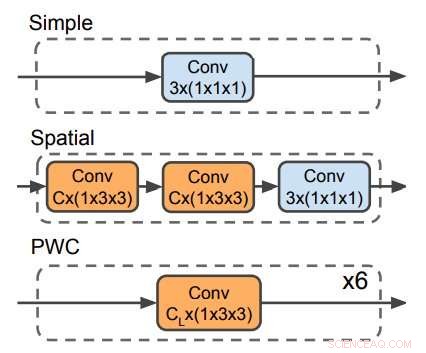
Tre dekodere bruges til at forudsige optisk flow. PWC-dekoderen ligner det optiske flow-forudsigelsesnetværk fra PWC-net. Ingen dekoder gør brug af tidsfiltre. Kredit:Stroud et al.
Forskerne uddannede et 'lærer' -netværk til at genkende handlinger givet bevægelsesinputet. Derefter, de uddannede et andet 'student' -netværk, som kun tilføres strømmen af almindelige billeder, med et dobbelt mål:klare opgaven med handlingsgenkendelse og efterligne output fra lærernetværket. I det væsentlige, studenternetværket lærer at genkende ud fra både udseende og bevægelse, bedre end læreren og såvel som de større og mere besværlige tostrømsmodeller.
For nylig, en række undersøgelser testede også en alternativ tilgang til videohandlingsgenkendelse, hvilket indebærer træning af et enkelt netværk med to forskellige mål:at præstere godt i handlingsgenkendelsesopgaven og direkte forudsige de lave bevægelsessignaler (dvs. optisk flow) i videoen. Forskerne fandt ud af, at deres destillationsmetode overgik denne tilgang. Dette tyder på, at det er mindre vigtigt for et netværk effektivt at genkende det optiske flow på lavt niveau i en video, end det er at gengive den viden på højt niveau, som lærernetværket har lært om at genkende handlinger fra bevægelse.
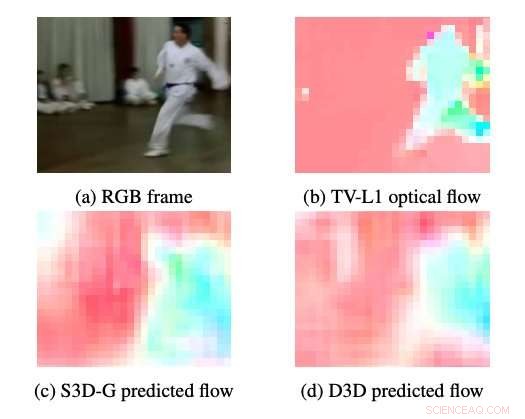
Eksempler på optisk flow produceret af S3DG og D3D (uden finjustering) ved hjælp af PWC-dekoderen påført på lag 3A. Farven og mætningen af hver pixel svarer til vinklen og størrelsen af bevægelsen, henholdsvis. TV-L1 optisk flow vises ved 28 × 28px, dekoderens outputopløsning. Kredit:Stroud et al.
Forskerne beviste, at det er muligt at træne et enkeltstrøms neuralt netværk, der yder lige så godt som to-strøms tilgange. Deres fund tyder på, at udførelsen af de nuværende state-of-the-art metoder til genkendelse af videohandlinger kan opnås ved hjælp af ca. 1/3 beregning. Dette ville gøre det nemmere at køre disse modeller på computer-begrænsede enheder, såsom smartphones, og i større skalaer (f.eks. for at identificere handlinger, såsom 'slam dunks', i YouTube -videoer).
Samlet set, denne nylige undersøgelse fremhæver nogle af manglerne ved eksisterende metoder til videohandlingsgenkendelse, foreslår en ny tilgang, der involverer uddannelse af en lærer og et elevnetværk. Fremtidig forskning, imidlertid, kunne forsøge at opnå state-of-the-art præstationer uden behov for et lærernetværk, ved at føre træningsdataene direkte til elevnetværket.
© 2019 Science X Network
Sidste artikelAt bryde barrierer inden for solenergi
Næste artikelFord vil nedlægge arbejdspladser i europæisk fornyelse
 Varme artikler
Varme artikler
-
 Uber genoptager tests af autonome køretøjer i PittsburghI denne 15. marts, 2017, fil foto, et skilt markerer et afhentningssted for Ubers bilservice i LaGuardia Lufthavn i New York. Uber vil genoptage testning af autonome køretøjer i et område nær Downtown
Uber genoptager tests af autonome køretøjer i PittsburghI denne 15. marts, 2017, fil foto, et skilt markerer et afhentningssted for Ubers bilservice i LaGuardia Lufthavn i New York. Uber vil genoptage testning af autonome køretøjer i et område nær Downtown -
 Facebook lancerer revision af data lækket til Trump-konsulentFacebook er i gang med en retsmedicinsk analyse af lækagen, der gjorde det muligt for et politisk analysefirma på linje med Donald Trump at få adgang til data om 50 millioner brugere Facebook medd
Facebook lancerer revision af data lækket til Trump-konsulentFacebook er i gang med en retsmedicinsk analyse af lækagen, der gjorde det muligt for et politisk analysefirma på linje med Donald Trump at få adgang til data om 50 millioner brugere Facebook medd -
 Nyt system genvinder ferskvand fra kraftværkerPå taget af det centrale forsyningsværks bygning, står foran et af køletårnene, er (venstre mod højre):Seth Kinderman, Central forsyningsværks ingeniørchef; Kripa Varanasi, lektor i maskinteknik; nyli
Nyt system genvinder ferskvand fra kraftværkerPå taget af det centrale forsyningsværks bygning, står foran et af køletårnene, er (venstre mod højre):Seth Kinderman, Central forsyningsværks ingeniørchef; Kripa Varanasi, lektor i maskinteknik; nyli -
 EU-kommissæren sætter spørgsmålstegn ved lovligheden af nye Ryanair-vilkårEuropas forbrugerkommissær har opfordret til en nærmere undersøgelse af lavprisflyselskabet Ryanair Forbrugerembedsmænd bør undersøge lavprisflyselskabet Ryanairs nye vilkår og betingelser, da eth
EU-kommissæren sætter spørgsmålstegn ved lovligheden af nye Ryanair-vilkårEuropas forbrugerkommissær har opfordret til en nærmere undersøgelse af lavprisflyselskabet Ryanair Forbrugerembedsmænd bør undersøge lavprisflyselskabet Ryanairs nye vilkår og betingelser, da eth
- Sikker fremtid for jernbanetransport af farlige materialer under udvikling
- Videnskabsprojekt: Effekten af masse på afstanden en boldrejse
- Nye påvisninger af gravitationsbølger bringer tallet til 11 - indtil videre
- Kom indenfor, vandet er superionisk
- Observation af topologiske magnon-isolatortilstande i et superledende kredsløb
- Forskere sætter ny bar for vandspaltning, CO2-opdelingsteknikker