


Afklaring af, hvordan kunstige intelligenssystemer træffer valg
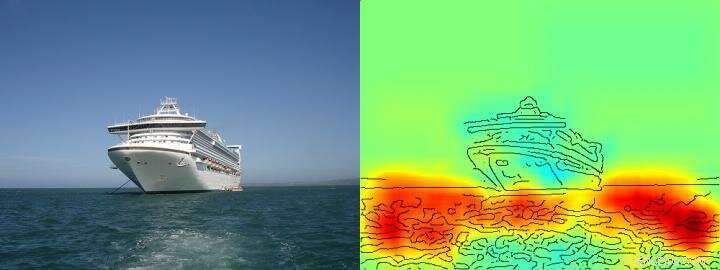
Varmekortet viser ganske tydeligt, at algoritmen træffer sin skib/ikke skib-beslutning på baggrund af pixels, der repræsenterer vand og ikke på baggrund af pixels, der repræsenterer skibet. Kredit: Naturkommunikation , CC BY licens
Kunstig intelligens (AI) og maskinlæringsarkitekturer såsom deep learning er blevet en integreret del af vores daglige liv – de muliggør digitale taleassistenter eller oversættelsestjenester, forbedre medicinsk diagnostik og er en uundværlig del af fremtidige teknologier såsom autonom kørsel. Baseret på en stadigt stigende mængde data og kraftfulde nye computerarkitekturer, læringsalgoritmer nærmer sig tilsyneladende menneskelige evner, nogle gange endda overgå dem. Indtil nu, imidlertid, det er ofte ukendt for brugerne, hvordan AI-systemer præcis når frem til deres konklusioner. Derfor, det kan ofte forblive uklart, om AI's beslutningsadfærd er virkelig intelligent, eller om procedurerne bare er gennemsnitligt vellykkede.
Forskere fra TU Berlin, Fraunhofer Heinrich Hertz Institute HHI og Singapore University of Technology and Design (SUTD) har tacklet dette spørgsmål og har givet et indblik i det forskelligartede "intelligens" spektrum, der observeres i nuværende AI-systemer, specifikt at analysere disse AI-systemer med en ny teknologi, der tillader automatiseret analyse og kvantificering.
Den vigtigste forudsætning for denne nye teknologi er en metode udviklet tidligere af TU Berlin og Fraunhofer HHI, den såkaldte Layer-wise Relevance Propagation (LRP) algoritme, der gør det muligt at visualisere efter hvilke inputvariable AI-systemer træffer deres beslutninger. Udvidelse af LRP, den nye spektralrelevansanalyse (SpRAy) kan identificere og kvantificere et bredt spektrum af indlært beslutningsadfærd. På denne måde er det nu blevet muligt at opdage uønsket beslutningstagning selv i meget store datasæt.
Denne såkaldte 'forklarlige AI' har været et af de vigtigste skridt hen imod en praktisk anvendelse af AI, ifølge Dr. Klaus-Robert Müller, professor i maskinlæring ved TU Berlin. "Specielt i medicinsk diagnose eller i sikkerhedskritiske systemer, ingen AI-systemer, der anvender skæve eller endda snydende problemløsningsstrategier, bør bruges."
Ved at bruge deres nyudviklede algoritmer, forskere er endelig i stand til at afprøve ethvert eksisterende AI-system og også udlede kvantitativ information om dem:et helt spektrum, der starter fra naiv problemløsningsadfærd, til snydestrategier op til yderst omfattende "intelligente" strategiske løsninger observeres.
Dr. Wojciech Samek, gruppeleder hos Fraunhofer HHI sagde:"Vi var meget overraskede over den brede vifte af indlærte problemløsningsstrategier. Selv moderne AI-systemer har ikke altid fundet en løsning, der virker meningsfuld fra et menneskeligt perspektiv, men brugte nogle gange såkaldte Clever Hans Strategies."
Klog Hans var en hest, der angiveligt kunne tælle og blev betragtet som en videnskabelig sensation i løbet af 1900-tallet. Som det senere blev opdaget, Hans mestrede ikke matematik, men i omkring 90 procent af tilfældene, han var i stand til at udlede det rigtige svar ud fra spørgers reaktion.
Holdet omkring Klaus-Robert Müller og Wojciech Samek opdagede også lignende "Clever Hans"-strategier i forskellige AI-systemer. For eksempel, et AI-system, der vandt adskillige internationale billedklassifikationskonkurrencer for nogle år siden, fulgte en strategi, der kan betragtes som naiv fra et menneskes synspunkt. Det klassificerede billeder hovedsageligt på baggrund af kontekst. Billeder blev tildelt kategorien "skib", når der var meget vand på billedet. Andre billeder blev klassificeret som "tog", hvis der var skinner til stede. Endnu andre billeder blev tildelt den korrekte kategori af deres copyright-vandmærke. Den egentlige opgave, nemlig at opdage begreberne skibe eller tog, blev derfor ikke løst af dette AI-system - selv om det faktisk klassificerede størstedelen af billederne korrekt.
Forskerne var også i stand til at finde disse typer af defekte problemløsningsstrategier i nogle af de avancerede AI-algoritmer, de såkaldte dybe neurale netværk - algoritmer, der var blevet anset for at være immune over for sådanne bortfald. Disse netværk baserede deres klassificeringsbeslutninger til dels på artefakter, der blev skabt under forberedelsen af billederne og har intet at gøre med det faktiske billedindhold.
"Sådanne AI-systemer er ikke nyttige i praksis. Deres brug i medicinsk diagnostik eller i sikkerhedskritiske områder ville endda medføre enorme farer, " sagde Klaus-Robert Müller. "Det er ret tænkeligt, at omkring halvdelen af de AI-systemer, der i øjeblikket er i brug, implicit eller eksplicit er afhængige af sådanne Clever Hans-strategier. Det er tid til systematisk at tjekke det, så sikre AI-systemer kan udvikles."
Med deres nye teknologi, forskerne identificerede også AI-systemer, der uventet har lært "smarte" strategier. Eksempler inkluderer systemer, der har lært at spille Atari-spillene Breakout og Pinball. "Her, AI'en forstod klart konceptet med spillet, og fundet en intelligent måde at samle en masse point på på en målrettet og lavrisiko måde. Systemet griber nogle gange endda ind på måder, som en rigtig spiller ikke ville, " sagde Wojciech Samek.
"Ud over at forstå AI-strategier, vores arbejde etablerer anvendeligheden af forklarlig AI til iterativt datasætdesign, nemlig at fjerne artefakter i et datasæt, som ville få en AI til at lære fejlbehæftede strategier, samt hjælpe med at beslutte, hvilke umærkede eksempler der skal annoteres og tilføjes, så fejl i et AI-system kan reduceres, " sagde SUTD adjunkt Alexander Binder.
"Vores automatiserede teknologi er open source og tilgængelig for alle videnskabsmænd. Vi ser vores arbejde som et vigtigt første skridt i at gøre AI-systemer mere robuste, forklarlig og sikker i fremtiden, og flere skal følge. Dette er en væsentlig forudsætning for generel brug af kunstig intelligens, " sagde Klaus-Robert Müller.
Sidste artikelStrømforsyningsenheder - med en bordlampe?
Næste artikelKina overhaler USA inden for kunstig intelligens:forskere
 Varme artikler
Varme artikler
-
 USA er fortsat engageret i den private sektor-ledede 5G trådløs:KudlowEn top amerikansk embedsmand dæmpede spekulationerne om, at Washington ville forsøge at nationalisere 5G trådløse systemer i USA, siger, at det privat ledede system fungerer godt En toprådgiver fo
USA er fortsat engageret i den private sektor-ledede 5G trådløs:KudlowEn top amerikansk embedsmand dæmpede spekulationerne om, at Washington ville forsøge at nationalisere 5G trådløse systemer i USA, siger, at det privat ledede system fungerer godt En toprådgiver fo -
 General Electric topper overskudsestimaterne, ringer 737 MAX ny risikoAktien i General Electric steg, efter at selskabet rapporterede bedre end ventet kvartalsoverskud General Electric rapporterede bedre end ventet kvartalsoverskud tirsdag, løftede håb om sin vendin
General Electric topper overskudsestimaterne, ringer 737 MAX ny risikoAktien i General Electric steg, efter at selskabet rapporterede bedre end ventet kvartalsoverskud General Electric rapporterede bedre end ventet kvartalsoverskud tirsdag, løftede håb om sin vendin -
 Højfrekvente transistorer opnår rekordeffektivitet ved 100 voltEn 100 V galliumnitrid effekttransistor med en udgangseffekt på 600 W ved en frekvens på 1,0 GHz. Kredit:Fraunhofer IAF Forskere ved Fraunhofer Institute for Applied Solid State Physics IAF har ha
Højfrekvente transistorer opnår rekordeffektivitet ved 100 voltEn 100 V galliumnitrid effekttransistor med en udgangseffekt på 600 W ved en frekvens på 1,0 GHz. Kredit:Fraunhofer IAF Forskere ved Fraunhofer Institute for Applied Solid State Physics IAF har ha -
 En globaliseret soldrevet fremtid er økonomisk urealistiskKredit:Valentin Valkov/Shutterstock.com I løbet af de sidste to århundreder, millioner af dedikerede mennesker – revolutionære, aktivister, politikere, og teoretikere – har ikke været i stand til
En globaliseret soldrevet fremtid er økonomisk urealistiskKredit:Valentin Valkov/Shutterstock.com I løbet af de sidste to århundreder, millioner af dedikerede mennesker – revolutionære, aktivister, politikere, og teoretikere – har ikke været i stand til
- Apple i forhandlinger om at købe Intel smartphone chip -enhed:rapport
- Billovgivningen i Japan har forbedret luftkvaliteten
- Længerevarende duft er kun en shampoo væk, takket være peptider
- Kepler har lært os, at klippeplaneter er almindelige
- Fordele og ulemper ved serie og parallelle kredsløb
- Kan vi oprette en rigtig Jurassic Park?