


Hvorfor sprogteknologi ikke kan håndtere Game of Thrones (endnu)

Winterfell. Kredit:mauRÍCIO santos (Unsplash, offentligt domæne)
Forskere fra Vrije Universiteit Amsterdam og Dutch Royal Academy's Humanities Cluster evaluerede fire avancerede værktøjer til at genkende navne i tekst, at vurdere og forbedre deres præstationer på populær fiktion. De finder løsninger til at øge værktøjernes evne til at genkende navne i én roman fra en nøjagtighed på 7 % til 90 %.
Natural Language Processing (NLP) værktøjer er almindeligt anvendt i mange daglige applikationer såsom Siri og Google, men effektiviteten af disse teknologier er ikke helt forstået. Forskere fra Vrije Universiteit Amsterdam og Dutch Royal Academy's Humanities Cluster har udført en grundig evaluering af fire forskellige navnegenkendelsesværktøjer på populære 40 romaner, inklusive A Game of Thrones. Deres analyser, udgivet i PeerJ Datalogi , fremhæve typer af navne og tekster, som er særligt udfordrende for disse værktøjer at identificere, samt løsninger til at afbøde dette. Ud over, de udtog sociale netværk fra romanerne for at udforske forskelle i historiestruktur. Disse indsigter kan hjælpe med at gøre sådanne teknologier mere robuste over for genreforskelle, og kan for eksempel hjælpe med at gøre denne teknologi mere nyttig for journalister, der ønsker at analysere store datasæt såsom Panama Papers.
Mange NLP-værktøjer er baseret på maskinlæring; det er, et computerprogram er trænet til at identificere mønstre i tekst baseret på tidligere indførte eksempler. For at genkende navne i tekst, den er f.eks. fodret med mange avisartikler, hvor mennesker omhyggeligt har markeret navnene. Programmet får derefter til opgave at 'lære', hvordan et navn ser ud baseret på kontekst (såsom, det bliver indledt af Mr) eller ordets form (såsom at navne generelt starter med et stort bogstav på engelsk). Nu, problemet, når man anvender et sådant system trænet på aviser til romaner, er, at forfattere til romaner har meget mere frihed i deres fortælling end journalister, der skal holde sig til fakta. Skønlitterære forfattere kan finde på deres egne navne, såsom Tywin eller R'hllor, eller brug beskrivende karakternavne direkte fra ordbogen, såsom Grey Worm. Disse navne opfører sig ikke som 'normale' navne, NLP -systemer har derfor svært ved at genkende dem i en tekst.
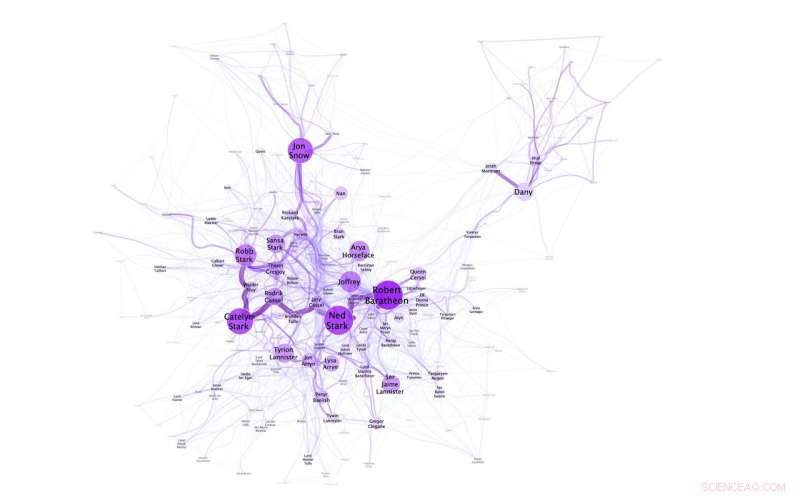
Netværksvisualisering, der viser, at Dany/Daenerys ikke er tæt på andre hovedpersoner i 'A Game of Thrones'. Kredit:N. M. Dekker, CC BY-SA 4.0
Forsøgene udført af Niels Dekker (Trifork B.V.), Tobias Kuhn (Vrije Universiteit Amsterdam) og Marieke van Erp (KNAW Humanities Cluster) fremhæver også sprogets fleksibilitet, og hvordan navne kontekstualiseres i historier. Det er for eksempel muligt at omtale Daenerys Targaryen som Daenerys og hun, men hun er også kendt som Dany, Daenerys Stormborn, dragernes mor, Khaleesi, de Ubrændte og Mhysa. Det sociale netværk skabt til A Game of Thrones, illustrerer for eksempel, at Dany bliver brugt af sine venner, og hendes fulde navn Daenerys kun af hendes fjender (i hendes fravær).
Forskningen beskrevet i denne publikation viser, at der bør lægges mere vægt på ydeevnen af NLP-værktøjer, og at der stadig er arbejde at gøre, før "tekst" kan forstås fuldt ud af computere.
 Varme artikler
Varme artikler
-
 Undersøgelse viser, at ansigtsgenkendelseseksperter klarer sig bedre med kunstig intelligens som pa…Viser disse to ansigter den samme person? Uddannede specialister kaldet retsmedicinske ansigtsgranskere vidner om sådanne spørgsmål i retten. En NIST-undersøgelse, der måler deres nøjagtighed, afsløre
Undersøgelse viser, at ansigtsgenkendelseseksperter klarer sig bedre med kunstig intelligens som pa…Viser disse to ansigter den samme person? Uddannede specialister kaldet retsmedicinske ansigtsgranskere vidner om sådanne spørgsmål i retten. En NIST-undersøgelse, der måler deres nøjagtighed, afsløre -
 Chinas Tencent:Teknologiverden skal tackle bekymringer om privatlivets fredSeng Yee Lau, senior vicepræsident i Tencent, Kinas største teknologiske virksomhed, svarer Associated Press, i Royal Monceau Hotel, i Paris, Torsdag, 24. maj kl. 2018. Seng Yee Lau fortalte Associate
Chinas Tencent:Teknologiverden skal tackle bekymringer om privatlivets fredSeng Yee Lau, senior vicepræsident i Tencent, Kinas største teknologiske virksomhed, svarer Associated Press, i Royal Monceau Hotel, i Paris, Torsdag, 24. maj kl. 2018. Seng Yee Lau fortalte Associate -
 Hvad er nyt for Amazons Prime Day? Tilbud hos Whole FoodsI denne 8. feb. 2018, fil foto, Amazon Prime Now-poser fyldt med dagligvarer bliver læsset til levering af en deltidsmedarbejder uden for en Whole Foods-butik i Cincinnati. Amazons Prime Day-tilbud ko
Hvad er nyt for Amazons Prime Day? Tilbud hos Whole FoodsI denne 8. feb. 2018, fil foto, Amazon Prime Now-poser fyldt med dagligvarer bliver læsset til levering af en deltidsmedarbejder uden for en Whole Foods-butik i Cincinnati. Amazons Prime Day-tilbud ko -
 Udvikler til at åbne hub til vækst i amerikansk havvindindustriKredit:CC0 Public Domain En offshore vindudvikler åbner et knudepunkt i Providence, som dets ledere håber vil hjælpe med at accelerere industriens start i USA. Ørsted U.S. Offshore Wind, en afdel
Udvikler til at åbne hub til vækst i amerikansk havvindindustriKredit:CC0 Public Domain En offshore vindudvikler åbner et knudepunkt i Providence, som dets ledere håber vil hjælpe med at accelerere industriens start i USA. Ørsted U.S. Offshore Wind, en afdel
- Hvordan er bartræer & bregner forskellige?
- Dybhavstransportbåndsstrøm skaber tsunamirisiko for Falklandsøerne
- Hvordan digital humaniora kan hjælpe i en pandemi
- Forskelle mellem en Boa, Python & Anaconda
- Boeing opgraderer software på kriseramte 737 MAX efter dødbringende styrt
- Styring af stivheden af et materiale på nanoskala