


Kun få hundrede træningseksempler bringer menneskelignende tale i Microsoft TTS feat
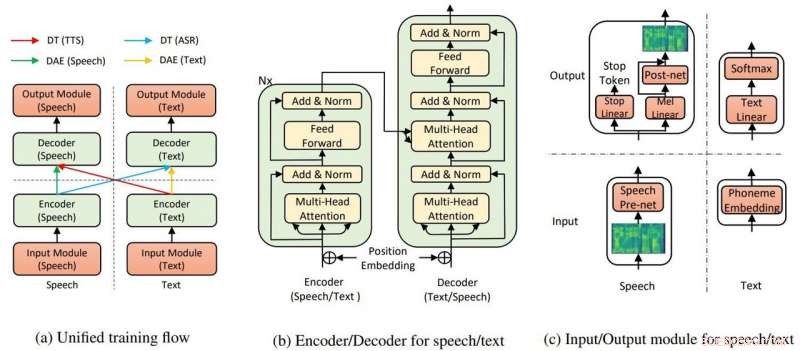
Den overordnede modelstruktur for TTS og ASR. Kredit:Yi Ren, Xu Tan et al.
Microsoft Research Asia har høstet klapsalver for at trække tekst til tale, der kræver lidt træning - og viser "utroligt" realistiske resultater.
Kyle Wiggers ind VentureBeat sagde tekst-til-tale-algoritmer ikke var nye og andre ganske dygtige, men stadig, teamindsatsen hos Microsoft har stadig en fordel.
Abdullah Matloob ind Digital informationsverden :"Tekst-til-tale konvertering bliver smart med tiden, men ulempen er, at det stadig vil tage en overdreven mængde træningstid og ressourcer at bygge et naturligt klingende produkt."
Leder efter en måde at trække på byrder af træningstid og ressourcer for at skabe output, der var naturligt klingende, Microsoft Research og kinesiske forskere opdagede en anden måde at konvertere tekst-til-tale på.
Fabienne Lang i Interessant teknik :Deres svar viser sig at være en AI-tekst-til-tale, der bruger 200 stemmeprøver (kun 200) til at skabe realistisk klingende tale, der matcher transskriptioner. Lang sagde, "Det betyder cirka 20 minutter værd."
At kravet kun var 200 lydklip og tilsvarende transskriptioner imponerede Wiggers i VentureBeat . Han bemærkede også, at forskerne udtænkte et AI-system "der udnytter uovervåget læring - en gren af maskinlæring, der henter viden fra umærkede, uklassificeret, og ukategoriserede testdata."
Deres papir er oppe på arXiv. "Næsten uovervåget tekst til tale og automatisk talegenkendelse" er af Yi Ren, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, Tie-Yan Liu. Forfattertilknytninger er Zhejiang University, Microsoft Research og Microsoft Search Technology Center (STC) Asien.
I deres papir, holdet sagde, at TTS AI bruger to nøglekomponenter, en transformator og denoising auto-encoder, at få det hele til at fungere.
"Gennem transformatorerne, Microsofts tekst-til-tale AI var i stand til at genkende tale eller tekst som enten input eller output, " sagde en artikel i Kantet af Rechelle Fuertes.
Tyler Lee ind Ubergizmo gav en definition af transformer:"Transformere...er dybe neurale netværk designet til at efterligne neuronerne i vores hjerne.."
MathWorks havde en definition for autoencoder. "En autoencoder er en type kunstigt neuralt netværk, der bruges til at lære effektive data (kodninger) på en uovervåget måde. Formålet med en autoencoder er at lære en repræsentation (encoding) for et sæt data, denoising autoencodere er typisk en type autoencodere trænet til at ignorere 'støj' i korrupte input samples."
Viser resultaterne af deres eksperiment, at deres idé er værd at jagte? "Vores metode opnår 99,84% i form af ordniveau forståelig rate og 2,68 MOS for TTS, og 11,7 % PER for ASR [automatisk talegenkendelse] på LJSpeech-datasæt, ved kun at udnytte 200 parrede tale- og tekstdata (ca. 20 minutters lyd), sammen med ekstra uparrede tale- og tekstdata."
Hvorfor dette betyder noget:Denne tilgang kan gøre tekst til tale mere tilgængelig, sagde rapporter.
"Forskere arbejder konstant på at forbedre systemet, og håber på, at i fremtiden, det vil kræve endnu mindre arbejde at skabe livagtig diskurs, " sagde Lang.
Papiret vil blive præsenteret på den internationale konference om maskinlæring, i Long Beach Californien senere på året, og holdet planlægger at frigive koden i de kommende uger, sagde Wiggers.
I mellemtiden forskerne er endnu ikke på vej væk fra deres arbejde med at præsentere transformationer med få parrede data.
"I dette arbejde, vi har foreslået den næsten uovervågede metode til tekst til tale og automatisk talegenkendelse, som kun udnytter få parrede tale- og tekstdata og ekstra uparrede data... Til fremtidigt arbejde, vi vil skubbe mod grænsen for uovervåget læring ved udelukkende at udnytte uparrede tale- og tekstdata, ved hjælp af andre fortræningsmetoder."
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Hardware-software co-design tilgang kunne gøre neurale netværk mindre strømkrævendeEt team ledet af UC San Diego har udviklet hardware og algoritmer, der kan reducere energiforbrug og tid, når man træner et neuralt netværk. Kredit:David Baillot/UC San Diego Jacobs School of Engineer
Hardware-software co-design tilgang kunne gøre neurale netværk mindre strømkrævendeEt team ledet af UC San Diego har udviklet hardware og algoritmer, der kan reducere energiforbrug og tid, når man træner et neuralt netværk. Kredit:David Baillot/UC San Diego Jacobs School of Engineer -
 Smil:Nogle passagerfly har kameraer på ryglænsskærmeI denne 16. juni, 2018, fil foto, American Airlines fly er set i OHare International Airport i Chicago. Nyere sæderygunderholdningssystemer på nogle fly, der drives af American Airlines og Singapore A
Smil:Nogle passagerfly har kameraer på ryglænsskærmeI denne 16. juni, 2018, fil foto, American Airlines fly er set i OHare International Airport i Chicago. Nyere sæderygunderholdningssystemer på nogle fly, der drives af American Airlines og Singapore A -
 Apple afslører plan for $1 mia. campus i Texas, amerikansk ekspansionApple vil bruge 1 milliard dollars på sit nye campus i Texas Apple afslørede torsdag planer for et campus på 1 milliard dollar i Texas, der vil skabe arbejdspladser til teknologigiganten uden for
Apple afslører plan for $1 mia. campus i Texas, amerikansk ekspansionApple vil bruge 1 milliard dollars på sit nye campus i Texas Apple afslørede torsdag planer for et campus på 1 milliard dollar i Texas, der vil skabe arbejdspladser til teknologigiganten uden for -
 Team udvikler en detektor, der stopper laterale phishing-angrebKredit:CC0 Public Domain Laterale phishing-angreb – svindel rettet mod brugere fra kompromitterede e-mail-konti i en organisation – bliver en stigende bekymring i USA. Mens angribere tidligere vi
Team udvikler en detektor, der stopper laterale phishing-angrebKredit:CC0 Public Domain Laterale phishing-angreb – svindel rettet mod brugere fra kompromitterede e-mail-konti i en organisation – bliver en stigende bekymring i USA. Mens angribere tidligere vi
- Halvdelen af Washingtons kirsebærblomstrer døde efter kold snap
- Stacking 2-D materialer giver overraskende resultater
- Styrtflod, advarsel om stormflod, da Isaias tønder op ad den amerikanske østkyst
- En ny symmetri-brudt forældretilstand opdaget i snoet to-lags grafen
- Undersøgelse afslører udfordringer ved at politimæssigt besidde cannabis
- Cassinis leder efter byggestenene i livet på Titan