


SPFCNN-Miner:En ny klassificering til at tackle klasseubalancerede data
Rutediagrammet hvis MLF. Kredit:Zhao et al.
Forskere ved Chongqing Universitet i Kina har for nylig udviklet en omkostningsfølsom meta-læringsklassificering, som kan bruges, når de tilgængelige træningsdata er højdimensionelle eller begrænsede. Deres klassificering, kaldet SPFCNN-minearbejder, blev præsenteret i et papir offentliggjort i Elsevier's Fremtidens generation af computersystemer .
Selvom maskinlæringsklassifikatorer har vist sig at være effektive til en række forskellige opgaver, for at opnå optimale resultater, de kræver ofte en stor mængde træningsdata. Når data er højdimensionelle, begrænset eller ubalanceret, de fleste klassifikationsmetoder er ikke i stand til at opnå en tilfredsstillende præstation. I deres undersøgelse, teamet af forskere ved Chongqing University satte sig for bedre at forstå disse data-relaterede udfordringer og udvikle en klassificering, der kan overvinde dem.
"Vi brugte siamesiske netværk, der er velegnede til få-skuds læring, hvor lidt data er tilgængeligt for at lære højdimensionelle og begrænsede data, og anvende ideen om at kombinere 'overflade' og 'dybe' tilgange til at designe parallelle siamesiske netværk, der bedre kan udtrække simple eller komplekse funktioner fra en række datasæt, "Linchang Zhao, en af de forskere, der har udført undersøgelsen, fortalte TechXplore. "Hovedformålene med vores undersøgelse var at løse det dataklasseubalancerede problem og få de bedst mulige klassificeringsresultater på sådanne datasæt."
Zhao og hans kolleger udviklede et siamesisk parallelt fuldt tilsluttet neuralt netværk (SPFCNN) og anvendte det på problemer med klasseubalancerede datadistributioner. For at omdanne deres omkostningsufølsomme SPFCNN til en omkostningsfølsom tilgang, de brugte en teknik kaldet 'omkostningsfølsom læring'.
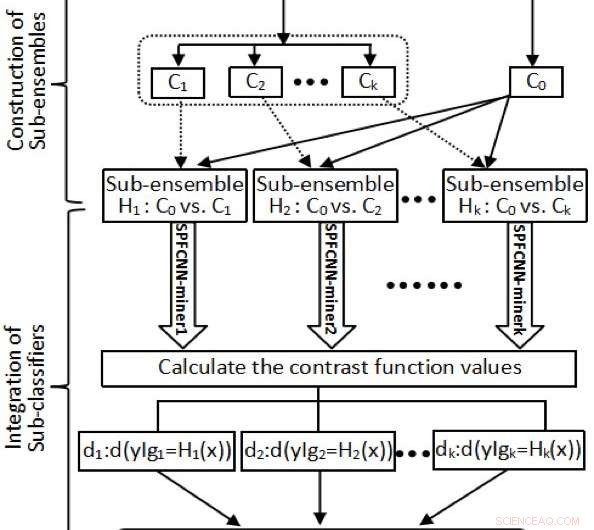
Først, forskerne delte majoritetsgruppen i et datasæt baseret på indre-produkt transformerede funktioner. Dette sikrede, at størrelsen af hver undergruppe i en majoritetsgruppe var tæt på minoritetsgruppens. Ud over, de strukturerede nogle underensembler ved at bruge minoritetsgruppen vs. hver opnået partition.
"Næste, vi ansøgte n SPFCNN-minearbejdere til alle underensembler, hvert prøvepunkt x j kan udtrykkes ved dets tilsvarende mål (d j1 , …, d jn ), hver underklassifikator kan omdannes til et mål for kontrastiv tabsfunktion ved at tilpasse SPFCNN, " forklarede Zhao. "Endelig, n SPFCNN-minearbejdere blev integreret som en endelig klassifikator i henhold til værdierne for kontrastiv funktion."
Den tilgang, der er udtænkt af Zhao og hans kolleger, har adskillige fordele, der adskiller den fra andre klassifikatorer. Først, deres Meta-Learner Function (MLF) kan bruges til at opdele majoritetsgruppen i et datasæt baseret på de indre-produkt transformerede funktioner, hvilket resulterer i, at de transformerede data indeholder information relateret til afstande og vinkler mellem emner i minoritets- og majoritetsgruppen.
"Vinklerne mellem majoritetsgruppen og minoritetsgruppen kan ses som udtryk for relaterede lokaliteter og repræsenterer så den relaterede retning af majoritetsgruppen til minoritetsgruppen, " forklarede Zhao.
En yderligere fordel ved den nye SPFCNN-Miner klassificering er, at ligesom andre siamesiske netværk, det kan effektivt udtrække funktioner på højeste niveau fra en lille mængde prøver til få-skuds læring. I øvrigt, parallelle siamesiske netværk er designet til adaptivt at lære simple eller komplekse funktioner fra forskellige dimensioner af dataattributter.
Zhao og hans kolleger evaluerede deres tilgang i en række beregningsmæssige tests, ved at bruge både omkostningsufølsomme og omkostningsfølsomme versioner af SPFCNN-klassifikatoren. De fandt ud af, at den omkostningsfølsomme tilgang klarede sig bedre end alle de klassifikatorer, de sammenlignede den med.
"De eksperimentelle resultater viser, at vores SPFCNN er en konkurrencedygtig tilgang og er i stand til at forbedre klassificeringsydelsen mere signifikant sammenlignet med de benchmarkede tilgange, " sagde Zhao. "Vi fandt ud af, at vores models ydeevne ikke blev forbedret, da stikprøvestørrelsen steg, men var stærkt påvirket af ubalanceraten. Præstationen opnået ved at inkorporere den omkostningsfølsomme læring i vores model er mere stabil."
Undersøgelsen udført af Zhao og hans kolleger introducerer en ny metode, der kunne bruges af forskere til at forbedre klassifikatorernes ydeevne, når data er begrænset eller ubalanceret. Ud over, deres resultater tyder på, at afbalancering af antallet af positive og negative prøver kan være mere effektivt end at generere et større antal kunstige prøver. For eksempel, deres tilgang kan integrere forskellige fejlklassificeringsomkostninger, når den fuldfører en klassificeringsopgave, hvilket gør det mere robust end andre teknikker, der bruges til at løse ubalancerede datarelaterede problemer.
"I fremtiden, vi planlægger at bruge teknikker som tilfældige gangmatricer, cirkulerende vægtdeling og Huffman-kodning for at komprimere vores model, og den løst forbundne teknologi eller parallel beskæring-kvantiseringsmetode vil blive brugt til at lette den foreslåede SPFCNN-model, " sagde Zhao.
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Tesla-aktien falder efter overraskende CFO-eksitAktierne i Tesla faldt efter den overraskende udskiftning af finansdirektøren. Aktier i elbilproducenten Tesla Motors var torsdag under pres efter den overraskende udskiftning af selskabets finans
Tesla-aktien falder efter overraskende CFO-eksitAktierne i Tesla faldt efter den overraskende udskiftning af finansdirektøren. Aktier i elbilproducenten Tesla Motors var torsdag under pres efter den overraskende udskiftning af selskabets finans -
 Regeringen hævder, at AT&T-Time Warner-aftalen ville skade forbrugerne (opdatering)I denne 22. marts, 2018, fil foto, AT&T CEO Randall Stephenson forlader det føderale retshus, i Washington. Den amerikanske regering påberåbte sig sin sag mandag, 30. april, for at blokere AT&T i at a
Regeringen hævder, at AT&T-Time Warner-aftalen ville skade forbrugerne (opdatering)I denne 22. marts, 2018, fil foto, AT&T CEO Randall Stephenson forlader det føderale retshus, i Washington. Den amerikanske regering påberåbte sig sin sag mandag, 30. april, for at blokere AT&T i at a -
 Ruslands verdensførste flydende atomanlæg ankommer i havnAkademik Lomonosov, verdens første flydende atomkraftværk, har afsluttet sin odyssé fra den arktiske havn Murmansk til landets fjerne østen - men miljøforkæmpere frygter for konsekvenserne Rusland
Ruslands verdensførste flydende atomanlæg ankommer i havnAkademik Lomonosov, verdens første flydende atomkraftværk, har afsluttet sin odyssé fra den arktiske havn Murmansk til landets fjerne østen - men miljøforkæmpere frygter for konsekvenserne Rusland -
 World Mobile Congress aflyst på grund af frygt for coronavirusMobilmessen er en af de største begivenheder i verden, der hidtil er blevet aflyst på grund af virussen Arrangørerne af World Mobile Congress sagde onsdag, at de har aflyst verdens førende mobil
World Mobile Congress aflyst på grund af frygt for coronavirusMobilmessen er en af de største begivenheder i verden, der hidtil er blevet aflyst på grund af virussen Arrangørerne af World Mobile Congress sagde onsdag, at de har aflyst verdens førende mobil
- Sådan laver du kontinuerlige ruller med grafen
- Ny strategi forbedrer stabiliteten af platingruppemetalkatalysatorer
- Watchdog sagsøger FBI for ansigtsgenkendelseshemmelighed
- Bekræftelse af simulerede beregninger med eksperimentresultater
- Hvordan fremtidige kvantecomputere vil true nutidens krypterede data
- 3-D-printede batterier klarer presset