


Forskere miner cache af Intel-processorer for at fremskynde datapakkebehandling
Kredit:KTH Det Kongelige Tekniske Institut
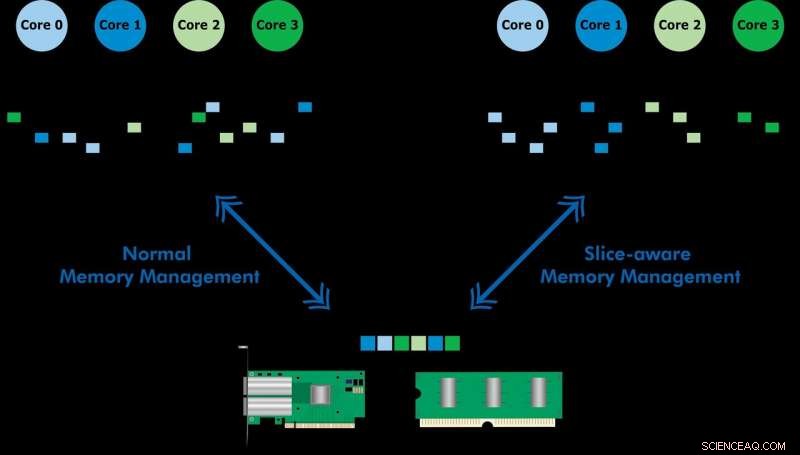
Udviklet med Ericsson Research, det skivebevidste hukommelsesstyringssystem gør det muligt at få adgang til hyppigt brugte data hurtigere via sidste niveaus cache af hukommelse (LLC) på en Intel Xeon CPU. Ved at etablere et nøgleværdilager og allokere hukommelse på en måde, så det er knyttet til det mest passende LLC-udsnit, de demonstrerede både højhastigheds pakkebehandling og forbedret ydeevne af en nøgleværdi butik. Holdet brugte den foreslåede ordning til at implementere et værktøj kaldet CacheDirector, hvilket gør Data Direct I/O (DDIO) opmærksom på skiver og udgav et konferenceoplæg, Få mest ud af sidste cache i Intel -processorer, som blev præsenteret på EuroSys 2019 i foråret.
"I øjeblikket, en server, der modtager 64-byte pakker ved 100Gbps, har kun 5,12 nanosekunder til at behandle hver pakke, inden den næste ankommer, " siger medforfatter Alireza Farshin, en ph.d.-studerende ved KTHs Netværkssystemlaboratorium. Men hvis data dirigeres til det rigtige cache-udsnit i CPU'en, det kan tilgås hurtigere – hvilket muliggør hurtigere behandling af flere pakker, på under 5 nanosekunder.
Data Direct I/O (DDIO) sender pakker til tilfældige skiver, hvilket er langt fra effektivt. Givet nutidens ikke-ensartede cache-arkitektur (NUCA), cache-styringsløsningen er uvurderlig, siger KTH-professor Dejan Kostic, der ledede forskningen.
"Når det kombineres med introduktionen af dynamisk headroom i Data Plane Development Kit (DPDK), pakkens header kan placeres i den del af LLC, der er tættest på den relevante behandlingskerne. Som resultat, kernen kan få hurtigere adgang til pakker og samtidig reducere køtid, " han siger.
"Vores arbejde viser, at udnyttelse af nanosekunders forbedringer i latens kan have en stor indflydelse på ydeevnen af applikationer, der kører på allerede stærkt optimerede computersystemer, "Siger Farshin. Teamet fandt ud af, at for en CPU, der kører på 3,2 GHz, CacheDirector kan gemme op til omkring 20 cyklusser pr. adgang til LLC, hvilket svarer til 6,25 nanosekunder. Dette accelererer pakkebehandlingen og reducerer ventetiden for optimerede Network Function Virtualization (NFV) servicekæder, der kører ved 100 Gbps, med op til 21,5 procent.
 Varme artikler
Varme artikler
-
 14-årige FaceTime-fejlopdagelse kan rasle AppleGrant Thompson og hans mor, Michele, se på en iPhone i familiens køkken i Tucson, Ariz., på torsdag, 31. januar, 2019. Den 14-årige faldt over en fejl i iPhones FaceTime-gruppechat-funktion den 19. ja
14-årige FaceTime-fejlopdagelse kan rasle AppleGrant Thompson og hans mor, Michele, se på en iPhone i familiens køkken i Tucson, Ariz., på torsdag, 31. januar, 2019. Den 14-årige faldt over en fejl i iPhones FaceTime-gruppechat-funktion den 19. ja -
 Nye detailværktøjer har til formål at løse e-handels profitdilemmaKonkurrence fra online juggernaut Amazon tvinger traditionelle detailhandlere til at tilpasse nye teknologier til at konkurrere Konventionel visdom i Amazonas æra hævder, at den laveste pris vinde
Nye detailværktøjer har til formål at løse e-handels profitdilemmaKonkurrence fra online juggernaut Amazon tvinger traditionelle detailhandlere til at tilpasse nye teknologier til at konkurrere Konventionel visdom i Amazonas æra hævder, at den laveste pris vinde -
 Warszawa-taxaer går langsomt imod anti-UberTraditionelle taxachauffører siger, at Uber -appen og andre som den repræsenterer uretfærdig konkurrence Hundredvis af taxaer kørte torsdag i sneglefart over den polske hovedstad Warszawa i protes
Warszawa-taxaer går langsomt imod anti-UberTraditionelle taxachauffører siger, at Uber -appen og andre som den repræsenterer uretfærdig konkurrence Hundredvis af taxaer kørte torsdag i sneglefart over den polske hovedstad Warszawa i protes -
 Netflix skånede, da Academy holder Oscars -reglen uændretKampagnere, herunder Steven Spielberg, har foreslået, at de film, der produceres og udgives af streamingfirmaer, ikke bør være berettigede til Oscars Academy of Motion Picture Arts and Sciences i
Netflix skånede, da Academy holder Oscars -reglen uændretKampagnere, herunder Steven Spielberg, har foreslået, at de film, der produceres og udgives af streamingfirmaer, ikke bør være berettigede til Oscars Academy of Motion Picture Arts and Sciences i
- Sådan beregnes induceret armaturspænding
- Undersøgelse undersøger arven fra regnskovsafbrænding i British Columbia
- Forskning afslører, hvordan celler genopbygges efter mitose
- Tropisk cyklon Irving ser langstrakt ud i NASA -billeder
- Twitter-brugere spreder strategier til forebyggelse af seksuel vold
- Hvordan Latitude & Altitude Affect Temperature