


Hader du spoilere? Dette AI-værktøj finder dem for dig

Kredit:CC0 Public Domain
Forkælede sociale medier Avengers' Endgame-filmen for dig? Eller måske en af Game of Thrones-bøgerne? Et team af forskere fra University of California San Diego arbejder på at sikre, at det ikke sker igen. De har udviklet et AI-baseret system, der kan markere spoilere i online anmeldelser af bøger og tv-shows.
"Spoilere er overalt på internettet, og er meget almindelige på sociale medier. Som internetbrugere, vi forstår smerten ved spoilere, og hvordan de kan ødelægge ens oplevelse, " sagde Ndapa Nakashole, en professor i datalogi ved UC San Diego og en af avisens seniorforfattere.
Nogle websteder giver folk mulighed for manuelt at markere deres indlæg med tags, der fungerer som advarselsskilte for 'spoiler ahead'. Men dette sker ikke altid. Så forskere ønskede at udvikle et kunstig intelligensværktøj drevet af neurale netværk til automatisk at opdage spoilere. De kaldte værktøjet SpoilerNet.
På et teoretisk plan, forskere ønsker bedre at forstå, hvordan folk skriver spoilere, og hvilken slags sproglige mønstre og almen viden, der markerer en sætning som en spoiler.
Forskere vil præsentere deres resultater på det årlige møde i 2019 i Association for Computational Linguistics i Firenze, Italien, 28. juli til 2. august. Værktøjet, som forskerne udviklede, kunne bruges til at bygge en browserudvidelse til at beskytte folk mod spoilere.
For at træne og teste SpoilerNet, UC San Diego-teamet ledte efter store datasæt af sætninger, der indeholdt spoilere. Spoiler alarm! De fandt ingen. Så de skabte deres eget ved at indsamle mere end 1,3 millioner boganmeldelser, kommenteret med spoiler-tags af boganmeldere. Mærkerne omfatter sætninger, der indeholder spoilere og skjuler dem bag et "se spoiler"-link i teksten. Anmeldelserne er indsamlet fra Goodreads, et socialt netværkssted, der giver folk mulighed for at spore, hvad de læser, og del tanker og anmeldelser med andre læsere.
"Så vidt vi ved, dette er det første datasæt med spoiler-annotationer i denne skala og med en så finkornet granularitet, " sagde Mengting Wan, en ph.d. studerende i datalogi ved UC San Diego og avisens første forfatter.
Forskere fandt ud af, at spoiler-sætninger har en tendens til at klumpe sig sammen i den sidste del af anmeldelser. Men de fandt også ud af, at forskellige brugere havde forskellige standarder for at mærke spoilere, og neurale netværk skulle omhyggeligt kalibreres for at tage højde for dette.
Ud over, det samme ord kan have forskellige semantiske betydninger i forskellige sammenhænge. For eksempel, 'grøn' er bare en farve i én boganmeldelse, men det kan være navnet på en vigtig karakter og et signal om spoilere i en anden bog. At identificere og forstå disse forskelle er udfordrende, sagde Wan.
Forskere trænede SpoilerNet i 80 procent af anmeldelserne på Goodreads, at køre teksten gennem flere lag af neurale netværk. Systemet kunne registrere spoilere med 89 til 92 procents nøjagtighed.
De kørte også SpoilerNet på et datasæt på mere end 16, 000 enkeltsætningsanmeldelser af omkring 880 tv-serier. Nøjagtigheden af værktøjet til at opdage spoilere var 74 til 80 procent.
De fleste af fejlene kom fra, at systemet blev distraheret af ord, der normalt er indlæste og afslørende - for eksempel mord eller dræbt.
Ser frem til, Goodreads-datasættet kan bruges som et kraftfuldt værktøj til at træne algoritmer til at opdage spoilere i forskellige typer indhold – f.eks. tweets, der indeholder spoilere.
 Varme artikler
Varme artikler
-
 Hummingbird-robot bruger AI til snart at gå, hvor droner ikke kanForskere ved Purdue University bygger robotkolibrier, der lærer af computersimuleringer, hvordan man flyver som en rigtig kolibri gør. Robotten er indkapslet i en dekorativ skal. Kredit:Purdue Univers
Hummingbird-robot bruger AI til snart at gå, hvor droner ikke kanForskere ved Purdue University bygger robotkolibrier, der lærer af computersimuleringer, hvordan man flyver som en rigtig kolibri gør. Robotten er indkapslet i en dekorativ skal. Kredit:Purdue Univers -
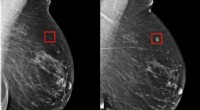 Brug AI til at forudsige brystkræft og personlig plejeTeamets model viste sig at være i stand til at identificere en kvinde med høj risiko for brystkræft fire år (til venstre), før den udviklede sig (til højre). Kredit:Massachusetts Institute of Technolo
Brug AI til at forudsige brystkræft og personlig plejeTeamets model viste sig at være i stand til at identificere en kvinde med høj risiko for brystkræft fire år (til venstre), før den udviklede sig (til højre). Kredit:Massachusetts Institute of Technolo -
 Brug af Google Street View til at estimere rejsemønstre i byerKredit:CC0 Public Domain En undersøgelse offentliggjort i dag i PLOS ET indikerer, at Google Street View har potentialet til at vurdere, hvor almindeligt cykling er i byer, og potentielt også an
Brug af Google Street View til at estimere rejsemønstre i byerKredit:CC0 Public Domain En undersøgelse offentliggjort i dag i PLOS ET indikerer, at Google Street View har potentialet til at vurdere, hvor almindeligt cykling er i byer, og potentielt også an -
 Samsung Electronics fordobler den nuværende smartphone-lagringshastighedKredit:Samsung Samsung Electronics annoncerede i dag, at de er begyndt at masseproducere branchens første 512-gigabyte (GB) indlejrede Universal Flash Storage (eUFS) 3.0 til næste generations mobi
Samsung Electronics fordobler den nuværende smartphone-lagringshastighedKredit:Samsung Samsung Electronics annoncerede i dag, at de er begyndt at masseproducere branchens første 512-gigabyte (GB) indlejrede Universal Flash Storage (eUFS) 3.0 til næste generations mobi
- Evaluering af kulturel værdi af landskaber ved hjælp af geotaggede fotos
- Hvilken del af nefronen er ansvarlig for reabsorptionen af vand?
- EasyJet flyver ind i greenwashing-rækken over løfte uden kulstof
- Planter og dyr Unikt til Atchafalaya-flodbassinet
- NASA-satellitbilleder viser vindforskydning, der påvirker den tropiske storm Jerry
- Hjælper EU byer og regioner med at reducere CO2 -udledningen