


Maskinlæring leder efter nyttige data i amerikanske tordenvejrsrapporter

Et tordenvejrs hyldesky nærmer sig Iowa State campus. Kredit:Bill Gallus
Bill Gallus har været kendt for at jagte en sommerstorm eller to. Men han behøvede ikke at gå efter denne.
Den 17. juli 2019, et tordenvejr nærmede sig Iowa State University campus. Gallus, professor i geologiske og atmosfæriske videnskaber, gik op på taget over sit kontor i Agronomibygningen. Og han glemte ikke et kamera.
Et af hans billeder viser en hyldesky, der markerer kanten af kraftige tordenvejr. Skyens distinkte linje deler billedet i halve, lav, skarp og imponerende, ingen fluffiness her. Den normalt travle Osborn Drive uden for hans kontor er for det meste tom - nogle få mennesker på gaden er vendt mod nord-nordvest, ser på stormen.
"Glattheden og den lave højde af en hyldesky gør det til et imponerende syn at observere, " skrev Gallus i en beskrivelse af billedet. "Det dannes, når den hurtigt bevægende kolde luft i et tordenvejr spreder sig, løfter den varme fugtige luft hurtigt over den."
Vi har alle set snesevis af tordenvejr. Og National Weather Service fører pligtopfyldende registreringer af hver enkelt og klassificerer deres styrke i sin Storm Reports-database. For at et tordenvejr skal markeres "alvorligt, " for eksempel, det skal producere en tornado, hagl større end 1 tomme i diameter eller vind større end 88 mph.
Men de fleste tordenvejr buldrer ikke over blæseinstrumenter. Så meteorologer har lavet vindestimater baseret på stormskader såsom træer ned, tage blæst væk eller skure skubbet omkuld. Og det meste af tiden, da den slags vindskader blev rapporteret, tordenvejr blev simpelthen klassificeret som alvorlige, uden reelle mål, der understøtter betegnelsen.
Det er et problem for forskere som Gallus, der har brug for gode data for at hjælpe dem med at udvikle bedre måder at forudsige alvorlige, lokale tordenvejr.
Et stort dataproblem
Da Gallus hørte campuskolleger fra Iowa State's Teoretical and Applied Data Science-forskningsgruppe tale om maskinlæring, han troede, at teknologiens dataanalysefunktioner kunne hjælpe ham med at studere og analysere Storm Reports-databasen. Måske kunne computerne finde relationer eller sammenhænge i rapporterne, der kunne føre til nye prognoseværktøjer?
Godt, ikke så hurtigt, sagde forskere ved National Oceanic and Atmospheric Administration (NOAA).
Den eksisterende database for alvorlige tordenvejr, der vedligeholdes af National Centres for Environmental Information, ville ikke være til megen nytte for Gallus eller andre forskere, der leder efter vinddata. Vindrapporterne var upålidelige. Rapporterne skulle ryddes op, før de kunne bruges til svære vindundersøgelser.
Så det er, hvad Gallus og et hold af Iowa State-dataforskere vil gøre. Støttet af en treårig, $650, 000 NOAA tilskud, de vil bruge computere og maskinlæringsværktøjer til at gennemsøge rapporterne og identificere sandsynligheden for, at hver enkelt faktisk beskriver et tordenvejr med hård vind.
Det er ikke en lille opgave - Gallus sagde, at forskerne vil starte med 12 års rapporter om alvorlige tordenvejr. Det er omkring 180, 000 af dem.
"Og 90 procent af de 180, 000 rapporter indeholder vindestimater, " sagde Gallus. "De er ikke baseret på vejrstationsdata. De fleste af dem siger træer eller lemmer ned - nogen ringede ind og sagde:"Mit træ blæste ned."
At sortere gennem disse rapporter rejser alle mulige udfordringer for dataforskere, sagde Eric Weber, en projektsamarbejdspartner og Iowa State professor i matematik.
Først, han sagde, at rapporterne er fulde af data indsamlet af mennesker, ikke med præcise og sofistikerede instrumenter. Rapporterne indeholder også naturlige, hverdagssprog. Der er idiomer, vendinger af sætninger og endda slåfejl, der skal analyseres af maskinlæringssoftwaren.
Og for det andet, tordenvejr er meget komplekse. Der er mange variabler - temperaturen af stigende luft, kondensation, Regn, lyn og mere - der skal indsamles, kvantificeret og analyseret for at forstå stormene.
Weber - der beskriver maskinlæring som et kunstigt neuralt netværk, der "skaber forbindelser baseret på den information, den har tilgængelig" - sagde, at computersoftwaren kan håndtere enorme mængder stormdata, der ville overvælde hold af mennesker.
Maskinlæringssoftware gør det også på en meget ikke-menneskelig måde.
"Når vi ser på data, forsøger vi at forstå dataene som mennesker, " sagde Weber. "Vi bringer vores opfattelser og fordomme. En af hovedårsagerne til, at maskinlæring bruges så succesfuldt nu, er, at den ikke bringer forudfattede meninger til analysen af dataene.
"Den kan finde potentielle forhold, som mennesker ikke kan på grund af deres forforståelser."
Mod bedre prognoser
Mens computerne gør fremskridt med stormrapporterne, Gallus sagde, at han vil give opdateringer og demonstrationer ved NOAAs årlige, ugers testbed i farligt vejr i Norman, Oklahoma. Testbedene er i maj tornadosæsonen og er en mulighed for forskere og prognosefolk til at bruge de nyeste forudsigelsesideer, værktøjer og teknologier.
Gallus håber at vise fremskridtene i tordenvejr-vindundersøgelsen. Han vil indsamle feedback og forslag. Og alt, hvad der i sidste ende kunne føre til et nyt prognoseværktøj, der forudsiger sandsynligheden for, at et tordenvejr vil producere kraftige vinde.
"Det vigtigste behov for NOAA lige nu er at rydde op i databasen for bedre forskning, " sagde Gallus. "Men vi har indset, at hvis dette projekt går godt sammen med maskinlæring, vi kunne se, hvordan det kunne fungere som et forudsigelsesværktøj."
 Varme artikler
Varme artikler
-
 Etiopiske 737-piloter fulgte Boeings retningslinjer før styrtet:WSJBoeings 737 MAX-fly blev sat på jorden på verdensplan efter to dødbringende styrt på mindre end fem måneder Piloterne på Ethiopian Airlines Boeing 737 MAX-fly, der styrtede ned i sidste måned, tog
Etiopiske 737-piloter fulgte Boeings retningslinjer før styrtet:WSJBoeings 737 MAX-fly blev sat på jorden på verdensplan efter to dødbringende styrt på mindre end fem måneder Piloterne på Ethiopian Airlines Boeing 737 MAX-fly, der styrtede ned i sidste måned, tog -
 Facebook idømt en bøde i Sydkorea for at begrænse brugeradgangEt nyt kunstig intelligens-værktøj, der er skabt til at hjælpe med at identificere visse former for stofmisbrug baseret på en hjemløs ungdoms Facebook-opslag, kunne give hjemløse krisecentre vital inf
Facebook idømt en bøde i Sydkorea for at begrænse brugeradgangEt nyt kunstig intelligens-værktøj, der er skabt til at hjælpe med at identificere visse former for stofmisbrug baseret på en hjemløs ungdoms Facebook-opslag, kunne give hjemløse krisecentre vital inf -
 Franske hoteller protesterer mod den uhyrlige Airbnb-Olympiske aftaleIOC-præsident Thomas Bach (L) annoncerede aftalen på en pressekonference i London med Airbnbs medstifter Joe Gebbia tirsdag Franske hotelejere angreb Airbnb onsdag på grund af deres nye partnerska
Franske hoteller protesterer mod den uhyrlige Airbnb-Olympiske aftaleIOC-præsident Thomas Bach (L) annoncerede aftalen på en pressekonference i London med Airbnbs medstifter Joe Gebbia tirsdag Franske hotelejere angreb Airbnb onsdag på grund af deres nye partnerska -
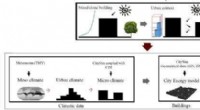 Design af byens energisystemer baseret på byklimaetKredit:Ecole Polytechnique Federale de Lausanne Efterhånden som byerne vokser i et stadigt hurtigere tempo, bekymringer om stigende global opvarmning og fossile brændstoffer bliver stadig mere kna
Design af byens energisystemer baseret på byklimaetKredit:Ecole Polytechnique Federale de Lausanne Efterhånden som byerne vokser i et stadigt hurtigere tempo, bekymringer om stigende global opvarmning og fossile brændstoffer bliver stadig mere kna
- Indonesien vælger Borneo-øen til ny hovedstad
- Forskere tester Rhode Islands vandsystemer for kemikalier kendt som PFAS'er
- Sådan beregnes radioaktivitet
- Hvordan klimaforandringer påvirkede forhistoriske menneskers fodermønstre i Indonesien
- Sådan bestemmes astrologisk den bedste dag til at tage en prøve
- Team udvikler den mest følsomme skala nogensinde