


Teknologi til fremstilling af selvkørende biler, robotteknologi, og andre applikationer forstår 3D-verdenen
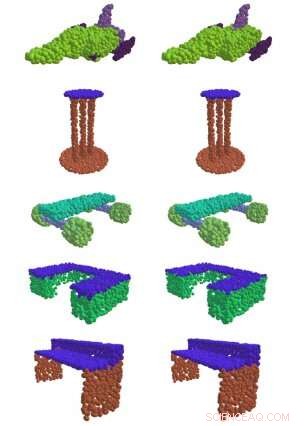
Til venstre, EdgeConv, en metode udviklet på MIT, med succes at finde meningsfulde dele af 3D-former, som overfladen af et bord, et flys vinger, og hjul på et skateboard. Til højre er sammenligningen mellem sandheden og jorden. Kredit:Massachusetts Institute of Technology
Hvis du nogensinde har set en selvkørende bil i naturen, du undrer dig måske over den roterende cylinder oven på den.
Det er en "lidar sensor, "og det er det, der gør det muligt for bilen at navigere rundt i verden. Ved at sende pulser af infrarødt lys og måle den tid, det tager for dem at hoppe af objekter, sensoren skaber en "point cloud", der bygger et 3-D øjebliksbillede af bilens omgivelser.
Det er svært at forstå rå point-cloud-data, og før maskinlæringens tidsalder krævede det traditionelt højtuddannede ingeniører, der kedeligt specificerede, hvilke kvaliteter de ønskede at fange i hånden. Men i en ny serie papirer fra MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL), forskere viser, at de kan bruge deep learning til automatisk at behandle punktskyer til en lang række 3-D-billeddannelsesapplikationer.
"I edb -vision og maskinlæring i dag, 90 procent af forskuddene vedrører kun todimensionale billeder, "siger MIT -professor Justin Solomon, som var seniorforfatter til den nye serie af artikler med ph.d. studerende Yue Wang. "Vores arbejde har til formål at imødekomme et grundlæggende behov for bedre at repræsentere 3D-verden, med anvendelse ikke kun i autonom kørsel, men ethvert felt, der kræver forståelse af 3D-former."
De fleste tidligere tilgange har ikke været særlig vellykkede med at fange mønstrene fra data, der er nødvendige for at få meningsfuld information ud af en flok 3D-punkter i rummet. Men i en af holdets papirer, de viste, at deres "EdgeConv" -metode til at analysere punktskyer ved hjælp af en type neuralt netværk kaldet et dynamisk grafkonvolutionsnervalt netværk gav dem mulighed for at klassificere og segmentere individuelle objekter.
"Ved at bygge 'grafer' over nabopunkter, Algoritmen kan fange hierarkiske mønstre og derfor udlede flere typer generisk information, der kan bruges af et utal af downstream-opgaver, "siger Wadim Kehl, en maskinlæringsforsker ved Toyota Research Institute, som ikke var involveret i arbejdet.
Udover at udvikle EdgeConv, holdet udforskede også andre specifikke aspekter af point-cloud-behandling. For eksempel, en udfordring er, at de fleste sensorer ændrer perspektiver, når de bevæger sig rundt i 3D-verdenen; hver gang vi tager en ny scanning af det samme objekt, dens position kan være anderledes end sidste gang vi så den. At flette flere punktskyer sammen til en enkelt detaljeret visning af verden, du skal justere flere 3D-punkter i en proces kaldet "registrering".
Registrering er afgørende for mange former for billeddannelse, fra satellitdata til medicinske procedurer. For eksempel, når en læge skal tage flere magnetiske resonansscanninger af en patient over tid, registrering er det, der gør det muligt at justere scanninger for at se, hvad der er ændret.
"Registrering er det, der giver os mulighed for at integrere 3D-data fra forskellige kilder i et fælles koordinatsystem, "siger Wang." Uden det, vi ville faktisk ikke være i stand til at få så meningsfuld information fra alle disse metoder, der er blevet udviklet."
Solomon og Wangs andet papir demonstrerer en ny registreringsalgoritme kaldet "Deep Closest Point" (DCP), der blev vist for bedre at finde en punktskols kendetegnende mønstre, point, og kanter (kendt som "lokale funktioner") for at tilpasse den til andre punktskyer. Dette er især vigtigt for sådanne opgaver som at gøre det muligt for selvkørende biler at placere sig selv i en scene ("lokalisering"), såvel som for robothænder til at lokalisere og gribe individuelle objekter.
En begrænsning af DCP er, at det antager, at vi kan se en hel form i stedet for kun den ene side. Det betyder, at den ikke kan klare den vanskeligere opgave med at tilpasse delvise visninger af former (kendt som "delvis-til-delvis registrering"). Som resultat, i et tredje papir præsenterede forskerne en forbedret algoritme til denne opgave, som de kalder Partial Registration Network (PRNet).
Solomon siger, at eksisterende 3D-data har en tendens til at være "ret rodede og ustrukturerede i forhold til 2-D-billeder og fotografier." Hans team søgte at finde ud af, hvordan man får meningsfuld information ud af al den uorganiserede 3D-data uden det kontrollerede miljø, som mange maskinlæringsteknologier nu kræver.
En vigtig observation bag succesen med DCP og PRNet er tanken om, at et kritisk aspekt af point-cloud-behandling er kontekst. De geometriske funktioner på punktsky A, der foreslår de bedste måder at justere den til punktsky B, kan være forskellige fra de funktioner, der er nødvendige for at justere den til punktsky C. F.eks. ved delvis registrering, en interessant del af en form i den ene punktsky er muligvis ikke synlig i den anden - hvilket gør den ubrugelig til registrering.
Wang siger, at teamets værktøjer allerede er blevet implementeret af mange forskere i computervisionssamfundet og videre. Selv fysikere bruger dem til en applikation, CSAIL -teamet aldrig havde overvejet:partikelfysik.
Bevæger sig fremad, forskerne håber at bruge algoritmerne på data fra den virkelige verden, herunder data indsamlet fra selvkørende biler. Wang siger, at de også planlægger at udforske potentialet ved at træne deres systemer ved hjælp af selvovervåget læring, for at minimere den nødvendige mængde menneskelige annoteringer.
Denne historie er genudgivet med tilladelse fra MIT News (web.mit.edu/newsoffice/), et populært websted, der dækker nyheder om MIT-forskning, innovation og undervisning.
 Varme artikler
Varme artikler
-
 Facebooks realitetstjek sender aktieafviklingFacebooks administrerende direktør Mark Zuckerberg sagde, at investeringer i sikkerhed og sikkerhed vil skade kortsigtet profit Det er blevet til et brutalt reality-tjek for Facebook. Den sociale
Facebooks realitetstjek sender aktieafviklingFacebooks administrerende direktør Mark Zuckerberg sagde, at investeringer i sikkerhed og sikkerhed vil skade kortsigtet profit Det er blevet til et brutalt reality-tjek for Facebook. Den sociale -
 86 procent af internetbrugerne indrømmer, at de er blevet narret af falske nyheder:undersøgelseRespondenter på en global undersøgelse af internetbrugere siger, at de ønsker, at både regeringer og sociale medievirksomheder slår ned på falske nyheder online 86 procent af internetbrugerne er b
86 procent af internetbrugerne indrømmer, at de er blevet narret af falske nyheder:undersøgelseRespondenter på en global undersøgelse af internetbrugere siger, at de ønsker, at både regeringer og sociale medievirksomheder slår ned på falske nyheder online 86 procent af internetbrugerne er b -
 Britisk politi bruger ansigtsgenkendelse til at teste offentlighedens toleranceI dette filfoto dateret søndag den 12. januar, 2020, fodboldfans myldrer uden for Cardiff City fodboldstadion forud for det engelske mesterskabskamp mod Swansea City, i Cardiff, Wales, da politiet i S
Britisk politi bruger ansigtsgenkendelse til at teste offentlighedens toleranceI dette filfoto dateret søndag den 12. januar, 2020, fodboldfans myldrer uden for Cardiff City fodboldstadion forud for det engelske mesterskabskamp mod Swansea City, i Cardiff, Wales, da politiet i S -
 Computerforskere bruger kunstig intelligens til at booste en jordskælvsfysiksimulatorForskellige lag af jorden plus bygninger oven på og inden i dem opfører sig forskelligt under et jordskælv. Interaktioner mellem disse lag forklarer kompleksiteten af jordskælvsmodeller. Kredit:2018
Computerforskere bruger kunstig intelligens til at booste en jordskælvsfysiksimulatorForskellige lag af jorden plus bygninger oven på og inden i dem opfører sig forskelligt under et jordskælv. Interaktioner mellem disse lag forklarer kompleksiteten af jordskælvsmodeller. Kredit:2018
- COVID-19-pandemien har været en perfekt storm for familievold
- Automatisering af kollisionsundgåelse
- Team identificerer skjulte spor til gamle superkontinenter, bekræfter Pannotia
- Fysikere foreslår reversibel justering af nanopartiklers emissionsfarve
- Hvor mange amerikanere tror på klimaændringer? Sandsynligvis mere end du tror, forskning i Indiana…
- Elon Musk laver en uhyggelig joke ved Jeff Bezos nye Blue Moon-lander