


Brug af efterlignings- og forstærkningslæring til at tackle robotopgaver med lang horisont

Kredit:Gupta et al.
Reinforcement learning (RL) er en meget brugt maskinlæringsteknik, der indebærer træning af AI-agenter eller robotter ved hjælp af et system med belønning og straf. Indtil nu, forskere inden for robotteknologi har primært anvendt RL-teknikker i opgaver, der udføres over relativt korte perioder, såsom at bevæge sig fremad eller tage fat i genstande.
Et team af forskere hos Google og Berkeley AI Research har for nylig udviklet en ny tilgang, der kombinerer RL med læring ved imitation, en proces kaldet relay policy learning. Denne tilgang, introduceret i et papir, der er forudgivet på arXiv og præsenteret på Conference on Robot Learning (CoRL) 2019 i Osaka, kan bruges til at træne kunstige midler til at tackle flertrins- og langhorisontopgaver, såsom objektmanipulationsopgaver, der strækker sig over længere tidsperioder.
"Vores forskning stammer fra mange, for det meste mislykket, eksperimenter med meget lange opgaver ved hjælp af forstærkningslæring (RL), "Abhishek Gupta, en af de forskere, der har udført undersøgelsen, fortalte TechXplore. "I dag, RL i robotteknologi anvendes for det meste i opgaver, der kan udføres på kort tid, såsom at gribe, skubbe genstande, går frem, osv. Selvom disse applikationer har stor værdi, vores mål var at anvende forstærkende læring til opgaver, der kræver flere delmål og opererer på meget længere tidsskalaer, såsom at dække et bord eller gøre rent i et køkken."
Før de begyndte at udvikle deres tilgang, Gupta og hans kolleger gennemgik tidligere litteratur for at prøve at afgøre, hvorfor længere opgaver er særligt svære at tackle ved hjælp af nuværende RL-teknikker. I deres papir, de antyder, at der generelt er to hovedårsager til dette.
Først, det er svært for en robot at identificere optimale løsninger til at løse lange og komplekse opgaver på egen hånd. Sekund, det er svært for agenten med succes at tackle en lang opgave, hvortil der først gives feedback i slutningen af en lang sekvens. Relæ politisk læring, den nye tilgang til læring, som de præsenterede, er designet til at løse begge disse udfordringer direkte.
Kredit:Gupta et al.
"For at løse udfordringen med at få robotter til at løse langsigtede opgaver på egen hånd, vi besluttede at forenkle problemet og bruge menneskeskabte demonstrationer, " sagde Gupta. "Det er svært at løse lange opgaver, fordi det er ekstremt svært at få en robot til at opdage en interessant adfærd på egen hånd - demonstrationer leveret af mennesker kan bruges som en rettesnor for interessante ting at gøre i et miljø."
Den tilgang til robotlæring foreslået af Gupta og hans kolleger har to adskilte stadier, den ene, hvor en agent lærer ved at efterligne mennesker, og den anden baseret på RL. I efterligningsindlæringsstadiet, en robot fodres med menneskelige demonstrationer af, hvordan man udfører en opgave og producerer målbetingede hierarkiske politikker.
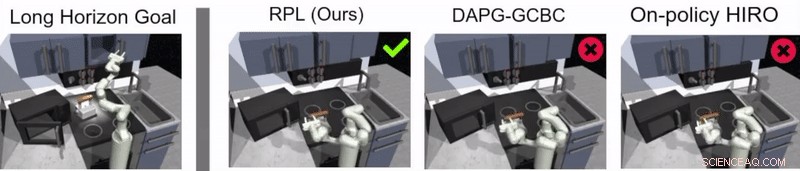
I deres undersøgelse, forskerne brugte deres tilgang til at træne et kunstigt middel kaldet Franka i flertrins- og langhorisontmanipulationsopgaver i et simuleret køkkenmiljø, som blev modelleret ved hjælp af fysiksimulatorplatformen MuJoCo. Dette miljø bestod af et køkken med en oplukkelig mikroovn, fire ovnbrændere, en ovnlyskontakt, en kedel, to hængslede skabe og en skydeskabsdør.

Kredit:Gupta et al.
"Vigtigt, at lære fra demonstrationer alene er ikke nok til at løse de udfordrende opgaver i vores simulerede køkkenmiljø, "Karol Hausman, en anden forsker involveret i undersøgelsen, fortalte TechXplore. "For at forbedre denne indledende løsning, vi tillader robotterne at øve opgaverne på egen hånd for at forfine deres adfærd yderligere."
I det væsentlige, ved at bruge den relæpolitiske læringsmetode foreslået af forskerne, en agent lærer først ved at behandle menneskelige demonstrationer af, hvordan man udfører en given opgave og fortsætter derefter med at lære på egen hånd via RL. For at gøre processen med at lære langsigtede politikker lettere, holdet brugte en ny data-ommærkningsalgoritme, der gør det muligt for en agent at lære målbetingede hierarkiske politikker.
"For at tackle udfordringen med sparsom feedback, vi bruger en hierarkisk struktur til vores kontrolpolitikker:Højniveaupolitikken foreslår mål, som lavniveaupolitikken forsøger at opnå – f.eks. lukke et skab, slukke for brænderen, etc., Hausman forklarede. "På denne måde, opgaven kan let dekomponeres til mindre delproblemer, der kan løses med forstærkningslæring, der er spændt fra menneskeskabte demonstrationer."

Kredit:Gupta et al.
Guppta, Hausman og deres kolleger evaluerede effektiviteten af relæpolitiklæring til træning af robotter i langsigtede opgaver inden for det simulerede køkkenmiljø, de skabte, opnår meget lovende resultater. De fandt ud af, at med den rigtige politikstruktur og demonstrationsdata, deres tilgang tillod robotter at tackle meget længere horisontopgaver, end de oprindeligt troede var muligt.
"Vi håber, at vores resultater kan åbne op for nye muligheder for at kombinere forskning i efterligning og forstærkende læring og giver os en potentiel retning, der kan tillade robotter at udføre lang tid, komplekse opgaver, " sagde Hausman.
I fremtiden, den relæpolitiske læringstilgang introduceret af Gupta, Hausman og deres kolleger kunne bruges til at træne robotter til en bredere række af opgaver med lang horisont. Forskerne har indtil videre kun testet deres teknik i et simuleret miljø; dermed, det ville være interessant at evaluere det i virkelige omgivelser og se, om det opnår lige så lovende resultater.
"Som et næste skridt, vi vil gerne se nærmere på problemet med generalisering ud over demonstrationsdataene, " sagde Hausman. "Til sidst, vi vil også gerne forbedre dataeffektiviteten af vores metode yderligere, gå til pixelobservationer og muliggør læring i den virkelige verden på en fysisk robot."
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Demokraterne ønsker, at feds skal målrette den sorte kasse med AI -biasI denne 9. februar, 2019, fil foto, Senator Cory Booker, D-N.J., ses på en mobiltelefon, mens han taler under et møde og hilse med lokale beboere i Marshalltown, Iowa. Kongressen begynder at vise inte
Demokraterne ønsker, at feds skal målrette den sorte kasse med AI -biasI denne 9. februar, 2019, fil foto, Senator Cory Booker, D-N.J., ses på en mobiltelefon, mens han taler under et møde og hilse med lokale beboere i Marshalltown, Iowa. Kongressen begynder at vise inte -
 Google sigter AI mod hvaler, ord og velværeGoogle sagde, at det udviklede måder at bruge kunstig til at spore hvaler som led i bestræbelserne på at beskytte truede arter Google gav tirsdag et kig på indsatsen for at bruge kunstig intellige
Google sigter AI mod hvaler, ord og velværeGoogle sagde, at det udviklede måder at bruge kunstig til at spore hvaler som led i bestræbelserne på at beskytte truede arter Google gav tirsdag et kig på indsatsen for at bruge kunstig intellige -
 Er offentlige indsigelser mod vindmølleparker overdrevne?Vindmøller er ved at blive lige så amerikanske som høballer. Kredit:MattJP, CC BY-SA Mens de fleste undersøgelser tyder på, at offentligheden generelt støtter vind- og solenergi, modstand fra loka
Er offentlige indsigelser mod vindmølleparker overdrevne?Vindmøller er ved at blive lige så amerikanske som høballer. Kredit:MattJP, CC BY-SA Mens de fleste undersøgelser tyder på, at offentligheden generelt støtter vind- og solenergi, modstand fra loka -
 Kropsstøtteanordning hjælper folk med at lære at gå igen efter et slagtilfælde, traumaPurdue Universitys Xiumin Diao førte et team til at skabe et vægtstøttesystem til at hjælpe mennesker, der lider af gangbesvær efter et slagtilfælde. Kredit:Purdue University En forsker fra Purdue
Kropsstøtteanordning hjælper folk med at lære at gå igen efter et slagtilfælde, traumaPurdue Universitys Xiumin Diao førte et team til at skabe et vægtstøttesystem til at hjælpe mennesker, der lider af gangbesvær efter et slagtilfælde. Kredit:Purdue University En forsker fra Purdue
- Sådan føjes et helt nummer til en brøk
- Enheden kunne høre sygdom gennem strukturer, der huser celler
- Brown Snakes of Georgia
- Nanofluidisk multi-værktøj adskiller og størrelser nanopartikler
- Forskere opdager tredobbelt forkant af solkoronale masseudstødninger
- Neutroner undersøger iltgenererende enzym for en grønnere tilgang til rent vand