


Dataloger designer et værktøj til at identificere kilden til fejl forårsaget af softwareopdateringer
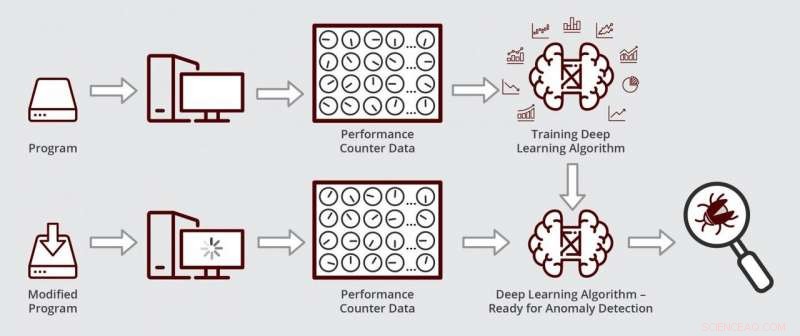
Skematisk illustration af, hvordan Muzahids dybe læringsalgoritme fungerer. Algoritmen er klar til afsløring af uregelmæssigheder, efter at den først er blevet trænet i ydelsestællerdata fra en fejlfri version af et program. Kredit:Texas A&M Engineering
Vi har alle delt frustrationen – softwareopdateringer, der har til formål at få vores applikationer til at køre hurtigere, ender uforvarende med at gøre det modsatte. Disse fejl, kaldet inden for datalogi som præstationsregression, er tidskrævende at rette, da lokalisering af softwarefejl normalt kræver betydelig menneskelig indgriben.
For at overvinde denne forhindring, forskere ved Texas A&M University, i samarbejde med dataloger ved Intel Labs, har nu udviklet en komplet automatiseret måde at identificere kilden til fejl forårsaget af softwareopdateringer. Deres algoritme, baseret på en specialiseret form for maskinlæring kaldet deep learning, er ikke kun nøglefærdig, men også hurtig, at finde ydeevnefejl i løbet af få timer i stedet for dage.
"Opdatering af software kan nogle gange tænde dig, når fejl sniger sig ind og forårsage opbremsninger. Dette problem er endnu mere overdrevet for virksomheder, der bruger store softwaresystemer, der konstant udvikler sig, " sagde Dr. Abdullah Muzahid, adjunkt ved Institut for Datalogi og Teknik. "Vi har designet et praktisk værktøj til diagnosticering af ydeevneregression, som er kompatibelt med en lang række software- og programmeringssprog, udvider dets anvendelighed enormt."
Forskerne beskrev deres resultater i den 32. udgave af Advances in Neural Information Processing Systems fra konferencen om Neural Information Processing Systems i december.
For at lokalisere kilden til fejl i software, debuggere kontrollerer ofte status for ydeevnetællere i centralenheden. Disse tællere er kodelinjer, der overvåger, hvordan programmet udføres på computerens hardware i hukommelsen, for eksempel. Så, når softwaren kører, tællere holder styr på antallet af gange, den får adgang til bestemte hukommelsesplaceringer, den tid, den bliver der, og hvornår den forlader, blandt andet. Derfor, når softwarens adfærd går skævt, tællere bruges igen til diagnostik.
"Performancetællere giver en idé om programmets eksekveringstilstand, " sagde Muzahid. "Så, hvis et eller andet program ikke kører, som det skal, disse tællere vil normalt have et afslørende tegn på unormal adfærd."
Imidlertid, nyere desktops og servere har hundredvis af ydeevnetællere, hvilket gør det praktisk talt umuligt at holde styr på alle deres status manuelt og derefter lede efter afvigende mønstre, der indikerer en ydeevnefejl. Det er her, Muzahids maskinlæring kommer ind.
Ved at bruge deep learning, forskerne var i stand til at overvåge data fra et stort antal tællere samtidigt ved at reducere størrelsen af dataene, hvilket svarer til at komprimere et billede i høj opløsning til en brøkdel af dets oprindelige størrelse ved at ændre dets format. I de lavere dimensionelle data, deres algoritme kunne så lede efter mønstre, der afviger fra det normale.
Da deres algoritme var klar, forskerne testede, om den kunne finde og diagnosticere en præstationsfejl i en kommercielt tilgængelig datastyringssoftware, der blev brugt af virksomheder til at holde styr på deres tal og tal. Først, de trænede deres algoritme til at genkende normale tællerdata ved at køre en ældre, fejlfri version af datastyringssoftwaren. Næste, de kørte deres algoritme på en opdateret version af softwaren med præstationsregression. De fandt ud af, at deres algoritme lokaliserede og diagnosticerede fejlen inden for et par timer. Muzahid sagde, at denne type analyse kunne tage en betydelig mængde tid, hvis den udføres manuelt.
Ud over at diagnosticere ydeevneregressioner i software, Muzahid bemærkede, at deres deep learning-algoritme også har potentielle anvendelser inden for andre forskningsområder, såsom at udvikle den teknologi, der er nødvendig for autonom kørsel.
"Grundtanken er igen den samme, at være i stand til at opdage et unormalt mønster, " sagde Muzahid. "Selvkørende biler skal være i stand til at opdage, om en bil eller et menneske er foran den og derefter handle derefter. Så, det er igen en form for anomalidetektion, og den gode nyhed er, at det er, hvad vores algoritme allerede er designet til at gøre."
Andre bidragydere til forskningen omfatter Dr. Mejbah Alam, Dr. Justin Gottschlich, Dr. Nesime Tatbul, Dr. Javier Turek og Dr. Timothy Mattson fra Intel Labs.
 Varme artikler
Varme artikler
-
 Forskning udforsker de etiske implikationer af at skabe sansende og selvbevidste sexbotsKredit:Media Drum, brugt af Express online på:express.co.uk/pictures/pics/8667/Sex-love-dolls-realistic-pictures Indtil nu, robotter er primært blevet udviklet til at opfylde utilitaristiske formå
Forskning udforsker de etiske implikationer af at skabe sansende og selvbevidste sexbotsKredit:Media Drum, brugt af Express online på:express.co.uk/pictures/pics/8667/Sex-love-dolls-realistic-pictures Indtil nu, robotter er primært blevet udviklet til at opfylde utilitaristiske formå -
 Åh de GAN'er:Scanner-fingerteknik kan resultere i falske fingeraftrykLatent Variable Evolution med et trænet netværk. Til venstre er en oversigt over CMA-ES på højt niveau, og boksen til højre viser, hvordan de latente variable evalueres. Kredit:arXiv:1705.07386 [cs.CV
Åh de GAN'er:Scanner-fingerteknik kan resultere i falske fingeraftrykLatent Variable Evolution med et trænet netværk. Til venstre er en oversigt over CMA-ES på højt niveau, og boksen til højre viser, hvordan de latente variable evalueres. Kredit:arXiv:1705.07386 [cs.CV -
 Sprint, T-Mobile-fusion får første grønt lysT-Mobile og Sprint er henholdsvis de tredje- og fjerdestørste trådløse udbydere i USA Den foreslåede fusion på 26 milliarder dollar mellem trådløse operatører T-Mobile og Sprint i USA vandt mandag
Sprint, T-Mobile-fusion får første grønt lysT-Mobile og Sprint er henholdsvis de tredje- og fjerdestørste trådløse udbydere i USA Den foreslåede fusion på 26 milliarder dollar mellem trådløse operatører T-Mobile og Sprint i USA vandt mandag -
 Lab bygger autopilotsoftware, der tillader UAV'er at svæve på termikNaval Research Laboratory bygger sol-svævende droner, der høster energi fra solen og termikken for at holde sig i luften i længere perioder. Kredit:Naval Research Laboratory En videnskabsmand fra
Lab bygger autopilotsoftware, der tillader UAV'er at svæve på termikNaval Research Laboratory bygger sol-svævende droner, der høster energi fra solen og termikken for at holde sig i luften i længere perioder. Kredit:Naval Research Laboratory En videnskabsmand fra
- Hvad er det grå goo mareridt?
- Hvordan man laver et æg Drop Box
- Dannelse af kunstig peptidbinding giver spor til skabelse af liv på Jorden
- En ende-til-ende generel ramme for automatisk diagnose af produktionssystemer
- Nanopartikler præsenterer naturligt venstre- og højrehåndede versioner
- Sådan konverteres Lumens til Candlepower