


Google Duo-lydboost lader dig ikke hænge i telefonen
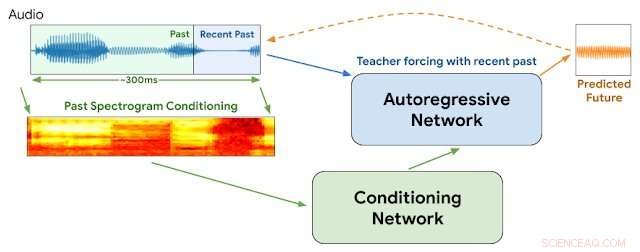
WaveNetEQ arkitektur. Under inferens, vi "varmer op" det autoregressive netværk ved at underviser forcere med den seneste lyd. Bagefter, modellen leveres med eget output som input til næste trin. Et MEL-spektrogram fra en længere lyddel bruges som input til konditioneringsnetværket. Kredit:Google
"Det er godt at høre din stemme, du ved det er så længe siden
Hvis jeg ikke får dine opkald, så går alt galt...
Din stemme på tværs af linjen giver mig en mærkelig fornemmelse"
- Blondie, "Lægger i telefonen"
I 1978, Debbie Harry drev sit new wave-band Blondie til toppen af hitlisterne med en klagende fortælling om at længes efter at høre sin kærestes stemme på afstand og insistere på, at han ikke lader hende "hænge i telefonen."
Men spørgsmålene opstår:Hvad hvis det var 2020, og hun talte over VOIP med periodiske pakketab, lyd jitter, netværksforsinkelser og pakketransmissioner uden for rækkefølge?
Det får vi aldrig at vide.
Men Google annoncerede i denne uge detaljer om en ny teknologi til sin populære Duo stemme- og videoapp, der vil hjælpe med at sikre jævnere stemmetransmissioner og reducere øjeblikkelige huller, der nogle gange ødelægger internetbaserede forbindelser. Vi vil gerne tro, at Debbie ville godkende det.
Vi har alle oplevet internetlydjitter. Det opstår, når en eller flere pakker med instruktioner, der omfatter en strøm af lydinstruktioner, forsinkes eller blandes ude af funktion mellem den, der ringer og lytter. Metoder, der anvender stemmepakkebuffere og kunstig intelligens, kan generelt udjævne jitter på 20 millisekunder eller mindre. Men afbrydelserne bliver mere mærkbare, når de manglende pakker tæller op til 60 millisekunder og mere.
Google siger, at stort set alle opkald oplever noget datapakketab:en femtedel af alle opkald mister 3 procent af deres lyd, og en tiendedel mister 8 procent.
Denne uge, Google-forskere ved DeepMind-afdelingen rapporterede, at de er begyndt at bruge et program kaldet WaveNetEQ til at løse disse problemer. Algoritmen udmærker sig ved at udfylde øjeblikkelige lydhuller med syntetiserede, men naturligt klingende taleelementer. At stole på et omfangsrigt bibliotek af taledata, WaveNetEQ udfylder lydhuller på op til 120 millisekunder. Sådanne lydbitswaps kaldes packet loss concealments (PLC).
"WaveNetEQ er en generativ model baseret på DeepMinds WaveRNN-teknologi, " Googles AI-blog rapporterede den 1. april, "der er trænet ved at bruge et stort korpus af taledata til realistisk at fortsætte korte talesegmenter, hvilket gør det muligt fuldt ud at syntetisere den rå bølgeform af manglende tale."
Programmet analyserede lyde fra 100 højttalere på 48 sprog, fokusere på "egenskaberne ved menneskelig tale generelt, i stedet for egenskaberne ved et bestemt sprog, " forklarede rapporten.
Ud over, lydanalyse blev testet i miljøer, der tilbyder en bred vifte af baggrundsstøj for at sikre nøjagtig genkendelse af højttalere på travle byfortove, togstationer eller cafeterier.
Al WaveNetEQ-behandling skal køre på modtagerens telefon, så krypteringstjenesterne ikke kompromitteres. Men det ekstra krav til behandlingshastighed er minimal, slår Google fast. WaveNetEQ er "hurtig nok til at køre på en telefon, samtidig med at den leverer avanceret lydkvalitet og mere naturligt lydende PLC end andre systemer, der er i brug i øjeblikket."
Lydeksempler, der illustrerer lydjitter og forbedringer med WabeNetEQ, er offentliggjort i Google Blog-rapporten.
© 2020 Science X Network
 Varme artikler
Varme artikler
-
 Byernes fremtid - muligheder, udfordringer og vejen fremEn ny rapport fra FFC identificerer tendenser, rejser spørgsmål og fremkalder diskussioner om, hvad byernes fremtid kan, og burde være. Kredit:EU, 2019 - grafisk uddybning fra olly AdobeStock, 2019
Byernes fremtid - muligheder, udfordringer og vejen fremEn ny rapport fra FFC identificerer tendenser, rejser spørgsmål og fremkalder diskussioner om, hvad byernes fremtid kan, og burde være. Kredit:EU, 2019 - grafisk uddybning fra olly AdobeStock, 2019 -
 Ingeniøren opfinder enestående surfrover-maskineDr. William Dally, en professor i civilingeniør ved University of North Florida, sammen med nogle af hans elever, betjene den komplette Surf Rover-model skaleret til en fjerdedel af den faktiske størr
Ingeniøren opfinder enestående surfrover-maskineDr. William Dally, en professor i civilingeniør ved University of North Florida, sammen med nogle af hans elever, betjene den komplette Surf Rover-model skaleret til en fjerdedel af den faktiske størr -
 Tesla omorganiserer for at fremskynde produktionenTesla-chef Elon Musk sagde, at en omorganisering af virksomheden sigter mod at fremskynde produktionen af Model 3, en nøgle til ekspansion af elbilproducenten Tesla-chef Elon Musk fortalte ansat
Tesla omorganiserer for at fremskynde produktionenTesla-chef Elon Musk sagde, at en omorganisering af virksomheden sigter mod at fremskynde produktionen af Model 3, en nøgle til ekspansion af elbilproducenten Tesla-chef Elon Musk fortalte ansat -
 Kina vil se førerløse biler om 3-5 år:Baiduførerløse biler, som denne Apollo, kunne ses på Kinas veje inden for tre til fem år Selvkørende biler kommer på vejene i Kina inden for tre til fem år, grundlæggeren af den kinesiske internetgig
Kina vil se førerløse biler om 3-5 år:Baiduførerløse biler, som denne Apollo, kunne ses på Kinas veje inden for tre til fem år Selvkørende biler kommer på vejene i Kina inden for tre til fem år, grundlæggeren af den kinesiske internetgig
- Varmere vintre forhindrer nogle søer i at fryse
- Hvad driver de enorme opblomstringer af brun tang, der hober sig op på Floridas og de caribiske st…
- Bøger beskriver, hvad der skal til for at sætte astronauter i rummet
- Forskere skaber en endelig metode til at opdage skovbrandsfarvede vindruer
- Insektantibiotikum giver en ny måde at fjerne bakterier på
- Lyst til at tilmelde dig rumturisme? Her er 6 ting at overveje (udover prisskiltet)