


Hvordan kunstig intelligens kan forklare sine beslutninger
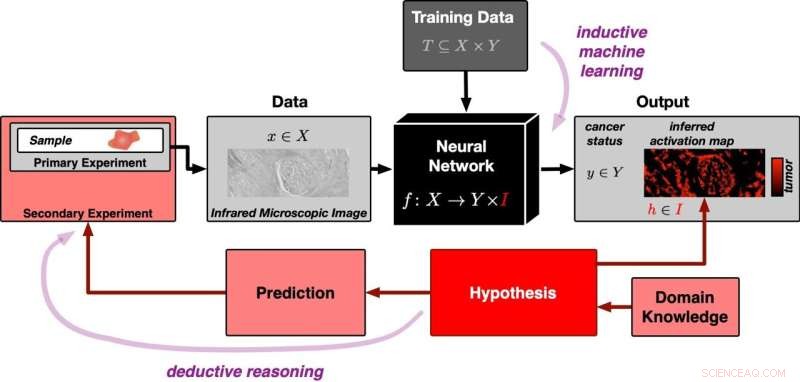
Et neuralt netværk trænes i første omgang med mange datasæt for at kunne skelne tumorholdige fra tumorfrie vævsbilleder (input fra toppen i diagrammet). Det præsenteres derefter med et nyt vævsbillede fra et eksperiment (input fra venstre). Via induktiv ræsonnement genererer det neurale netværk klassifikationen "tumor-indeholdende" eller "tumor-fri" for det respektive billede. Samtidig skaber den et aktiveringskort over vævsbilledet. Aktiveringskortet er opstået fra den induktive læringsproces og er i starten ikke relateret til virkeligheden. Korrelationen etableres af den falsificerbare hypotese, at områder med høj aktivering svarer nøjagtigt til tumorregionerne i prøven. Denne hypotese kan testes med yderligere eksperimenter. Det betyder, at tilgangen følger deduktiv logik. Kredit:PRODI
Kunstig intelligens (AI) kan trænes til at genkende, om et vævsbillede indeholder en tumor. Men præcis, hvordan den træffer sin beslutning, har indtil nu været et mysterium. Et hold fra Research Center for Protein Diagnostics (PRODI) ved Ruhr-Universität Bochum er ved at udvikle en ny tilgang, der vil gøre en AI's beslutning gennemsigtig og dermed troværdig. Forskerne ledet af professor Axel Mosig beskriver tilgangen i tidsskriftet Medical Image Analysis .
Til undersøgelsen samarbejdede bioinformatikforsker Axel Mosig med professor Andrea Tannapfel, leder af Institut for Patologi, onkolog professor Anke Reinacher-Schick fra Ruhr-Universität St. Josef Hospital og biofysiker og PRODI-grundlægger professor Klaus Gerwert. Gruppen udviklede et neuralt netværk, det vil sige en AI, der kan klassificere, om en vævsprøve indeholder tumor eller ej. Til dette formål fodrede de AI med et stort antal mikroskopiske vævsbilleder, hvoraf nogle indeholdt tumorer, mens andre var tumorfrie.
"Neurale netværk er oprindeligt en sort boks:det er uklart, hvilke identificerende funktioner et netværk lærer fra træningsdataene," forklarer Axel Mosig. I modsætning til menneskelige eksperter mangler de evnen til at forklare deres beslutninger. "Men især til medicinske anvendelser er det vigtigt, at AI er i stand til at forklare og dermed troværdig," tilføjer bioinformatikforsker David Schuhmacher, som samarbejdede om undersøgelsen.
AI er baseret på falsificerbare hypoteser
Bochum-teamets forklarlige AI er derfor baseret på den eneste slags meningsfulde udsagn, som videnskaben kender:på falsificerbare hypoteser. Hvis en hypotese er falsk, skal denne kendsgerning kunne påvises gennem et eksperiment. Kunstig intelligens følger normalt princippet om induktiv ræsonnement:ved hjælp af konkrete observationer, dvs. træningsdataene, skaber AI en generel model, på grundlag af hvilken den evaluerer alle yderligere observationer.
Det underliggende problem var blevet beskrevet af filosoffen David Hume for 250 år siden og kan let illustreres:Uanset hvor mange hvide svaner vi observerer, kunne vi aldrig ud fra disse data konkludere, at alle svaner er hvide, og at der overhovedet ikke eksisterer sorte svaner. Videnskaben gør derfor brug af såkaldt deduktiv logik. I denne tilgang er en generel hypotese udgangspunktet. For eksempel forfalskes hypotesen om, at alle svaner er hvide, når en sort svane opdages.
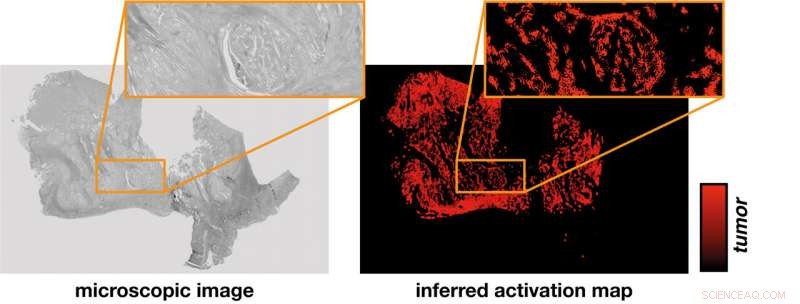
Det neurale netværk udleder et aktiveringskort (til højre) fra det mikroskopiske billede af en vævsprøve (til venstre). En hypotese etablerer sammenhængen mellem intensiteten af aktivering, der blev bestemt udelukkende ved beregning og identifikation af tumorregioner, der kan verificeres i eksperimenter. Kredit:PRODI
Aktiveringskort viser, hvor tumoren er opdaget
"Ved første øjekast virker induktiv AI og den deduktive videnskabelige metode næsten uforenelige," siger Stephanie Schörner, en fysiker, der ligeledes har bidraget til undersøgelsen. Men forskerne fandt en måde. Deres nye neurale netværk giver ikke kun en klassificering af, om en vævsprøve indeholder en tumor eller er tumorfri, det genererer også et aktiveringskort over det mikroskopiske vævsbillede.
Aktiveringskortet er baseret på en falsificerbar hypotese, nemlig at aktiveringen afledt af det neurale netværk svarer nøjagtigt til tumorregionerne i prøven. Stedspecifikke molekylære metoder kan bruges til at teste denne hypotese.
"Takket være de tværfaglige strukturer hos PRODI har vi de bedste forudsætninger for at inkorporere den hypotesebaserede tilgang i udviklingen af pålidelig biomarkør AI i fremtiden, for eksempel for at kunne skelne mellem visse terapirelevante tumorsubtyper," slutter Axel Mosig. + Udforsk yderligere
Kunstig intelligens klassificerer kolorektal cancer ved hjælp af infrarød billeddannelse
 Varme artikler
Varme artikler
-
 Dyserig brandmand er en robot, ligner en drageJapans ingeniører og teknologer arbejder fortsat på at løse problemer med at håndtere forskellige typer katastrofer - jordskælv, tsunamier, enhver uforudset katastrofe, der forårsager ekstrem skade på
Dyserig brandmand er en robot, ligner en drageJapans ingeniører og teknologer arbejder fortsat på at løse problemer med at håndtere forskellige typer katastrofer - jordskælv, tsunamier, enhver uforudset katastrofe, der forårsager ekstrem skade på -
 Canada, Apples udvikling af kulfri aluminiumssmeltningsteknologi tilbageAluminium bruges i alt fra biler og fly, sodavandsdåser, folie og vinduesrammer, såvel som i Apple-smartphones, tablets og computere Canada og Quebec -provinsen, samt teknologigiganten Apple, anno
Canada, Apples udvikling af kulfri aluminiumssmeltningsteknologi tilbageAluminium bruges i alt fra biler og fly, sodavandsdåser, folie og vinduesrammer, såvel som i Apple-smartphones, tablets og computere Canada og Quebec -provinsen, samt teknologigiganten Apple, anno -
 Fransk forbrugergruppe indleder gruppesøgsmål mod GoogleGoogle er blevet ramt af en række juridiske slag i Frankrig En fransk forbrugerrettighedsgruppe sagde onsdag, at den har indledt et gruppesøgsmål mod den amerikanske teknologigigant Google for ove
Fransk forbrugergruppe indleder gruppesøgsmål mod GoogleGoogle er blevet ramt af en række juridiske slag i Frankrig En fransk forbrugerrettighedsgruppe sagde onsdag, at den har indledt et gruppesøgsmål mod den amerikanske teknologigigant Google for ove -
 Mangel på polering, mangler indhold mar AT&Ts nye ledningskutter-tjenesteKredit:CC0 Public Domain Du havde allerede brug for et scorekort for at fortælle alle spillerne i denne indviklede streaming, snoreskærende æra. Mandagens landsdækkende lancering af AT&T TV indvar
Mangel på polering, mangler indhold mar AT&Ts nye ledningskutter-tjenesteKredit:CC0 Public Domain Du havde allerede brug for et scorekort for at fortælle alle spillerne i denne indviklede streaming, snoreskærende æra. Mandagens landsdækkende lancering af AT&T TV indvar
- Find sandheden på sociale medier
- Opfanger optisk lys med fri plads til højhastigheds-Wi-Fi
- Rekordskærende hedebølger forårsaget af opvarmningshastighed:undersøgelse
- Sådan får du gennemsnittet af decimaler
- Forskere udvikler en ny måde at designe elektronik på
- NASA-NOAA-satellitbilleder om natten hjælper med at bekræfte, at Elida nu er post-tropisk