


Brug af en GAN-arkitektur til at gendanne stærkt komprimerede musikfiler
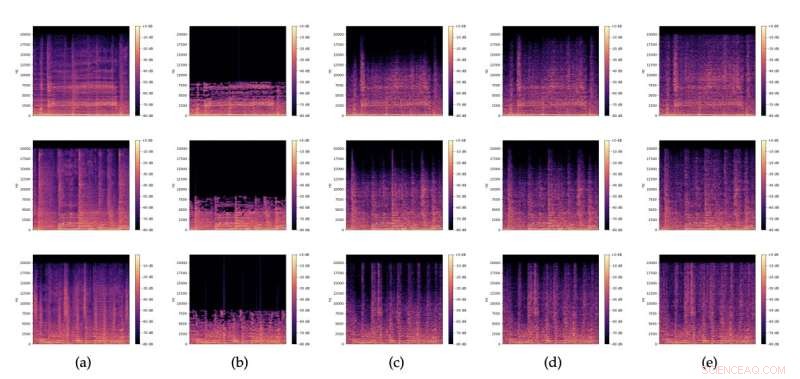
Spektrogrammer af (a) originale lyduddrag, (b) tilsvarende 32kbit/s MP3-versioner og (c), (d), (e) restaureringer med forskellig støj z tilfældigt samplet fra N (0,I). Kredit:Lattner &Nistal.
I løbet af de sidste par årtier har dataloger udviklet mere og mere avancerede teknologier og værktøjer til at gemme store mængder musik og lydfiler i elektroniske enheder. En særlig milepæl for musiklagring var udviklingen af MP3 (dvs. MPEG-1 lag 3) teknologi, en teknik til at komprimere lydsekvenser eller sange til meget små filer, der nemt kan gemmes og overføres mellem enheder.
Kodning, redigering og komprimering af mediefiler, herunder PKZIP, JPEG, GIF, PNG, MP3, AAC, Cinepak og MPEG-2 filer, opnås ved hjælp af et sæt teknologier kendt som codecs. Codecs er komprimeringsteknologier med to nøglekomponenter:en koder, der komprimerer filer, og en dekoder, der dekomprimerer dem.
Der er to typer codecs, de såkaldte lossless og lossy codecs. Under dekomprimering gengiver tabsfri codecs, såsom PKZIP- og PNG-codecs, nøjagtig samme fil som originalfiler. Tabskomprimeringsmetoder producerer på den anden side en faksimile af den originale fil, der lyder (eller ligner) originalen, men som optager mindre lagerplads i elektroniske enheder.
Lossy audio codecs fungerer i det væsentlige ved at komprimere digitale lydstreams, fjerne nogle data og derefter dekomprimere dem. Generelt er forskellen mellem den originale og dekomprimerede fil svær eller umulig for mennesker at opfatte.
Når tabsgivende codecs bruger høje komprimeringsrater, kan de imidlertid indføre forringelser og mærkbart ændre lydsignaler. For nylig har dataloger forsøgt at overvinde denne begrænsning af tabsgivende codecs og forbedre kvaliteten af komprimerede filer ved hjælp af deep learning-teknikker.
Forskere ved Sony Computer Science Laboratories (CSL) har for nylig udviklet en ny deep learning-metode til at forbedre og genoprette kvaliteten af stærkt komprimerede sange og lydoptagelser (dvs. lydfiler, der blev komprimeret af codecs med tab med høje komprimeringsrater). Denne metode, der er introduceret i et papir, der er forududgivet på arXiv, er baseret på generative adversarial networks (GAN'er), maskinlæringsmodeller, hvor to neurale netværk "konkurrerer" om at lave mere og mere præcise eller pålidelige forudsigelser.
"Mange værker har løst problemet med lydforbedring og fjernelse af kompressionsartefakter ved hjælp af dybe læringsteknikker," skrev Stefan Lattner og Javier Nistal i deres papir. "Men kun få værker tackler restaureringen af stærkt komprimerede lydsignaler i det musikalske domæne. I denne undersøgelse tester vi en stokastisk generator til en generativ adversarial network-arkitektur (GAN) til denne opgave."
Som andre GAN'er består modellen skabt af Lattner og Nistal af to separate modeller, kendt som "generatoren (G)" og "kritikeren (D)". Generatoren modtager et uddrag af et MP3-komprimeret musikalsk lydsignal, repræsenteret gennem et spektrogram (dvs. en visuel repræsentation af et lydsignals spektrumfrekvenser).
Generatoren lærer løbende at producere en gendannet version af dette originale signal, som er mindre i størrelse. I mellemtiden lærer GAN-arkitekturens kritikerkomponent at skelne mellem de originale filer af høj kvalitet og gendannede versioner, og opdager dermed forskelle mellem dem. I sidste ende bruges informationen indsamlet af kritikeren til at forbedre kvaliteten af de gendannede filer, hvilket sikrer, at musik- eller lyddataene i de gendannede filer er så trofaste som muligt i forhold til originalen.
Lattner og Nistal evaluerede deres GAN-baserede arkitektur i en række tests, som havde til formål at afgøre, om deres model kunne forbedre kvaliteten af MP3-input og generere komprimerede samples, der er af højere kvalitet og tættere på en original fil end dem, der er oprettet af andre basismodeller til lydkomprimering. Deres resultater var meget lovende, da de fandt ud af, at modellens gendannelser af stærkt komprimerede MP3-filer (16 kbit/s og 32 kbit/s) typisk var bedre end de originale komprimerede filer, da de lød bedre for erfarne menneskelige lyttere. Ved brug af svagere kompressionshastigheder (64 kbit/s mono) fandt teamet på den anden side ud af, at deres model opnåede lidt dårligere resultater end de grundlæggende MP3-komprimeringsværktøjer.
"Vi udfører en omfattende evaluering af de forskellige eksperimenter ved at bruge objektive målinger og lyttetest," sagde Lattner og Nistal. "Vi finder ud af, at modellerne kan forbedre kvaliteten af lydsignaler i forhold til MP3-versionerne for 16 og 32 kbit/s, og at de stokastiske generatorer er i stand til at generere output, der er tættere på de originale signaler end de deterministiske generatorers."
Som en del af deres undersøgelse viste forskerne også, at deres arkitektur med succes kunne generere og tilføje realistisk højfrekvent indhold, der forbedrede lydkvaliteten af komprimerede sange. Det genererede indhold inkluderede perkussive elementer, en sangstemme, der producerede sibilanter eller plosiver (dvs. "s" og "t" lyde) og guitarlyde.
I fremtiden kunne den model, de skabte, hjælpe med at reducere størrelsen af MP3-musikfiler betydeligt uden at ændre deres indhold eller skabe let opfattelige fejl. Dette kan have betydelige konsekvenser for lagring og transmission af musik på både streaming-apps (f.eks. Spotify, Apple Music osv.) og moderne elektroniske enheder, herunder smartphones, tablets og computere. + Udforsk yderligere
Google Lyra vil aktivere taleopkald for endnu en milliard brugere
© 2022 Science X Network
Sidste artikelAI, der kan lære det menneskelige sprogs mønstre
Næste artikelSød tilbagevenden:Tysk landmand får både solenergi og æbler
 Varme artikler
Varme artikler
-
 EU -nationer bør gribe chancen for at øge vedvarende energi:undersøgelseOmkostninger til solenergi, såsom denne facilitet i Allonnes, Frankrig, er faldet de seneste år EUs medlemsstater bør drage fordel af faldende omkostninger til vedvarende energi til at investere m
EU -nationer bør gribe chancen for at øge vedvarende energi:undersøgelseOmkostninger til solenergi, såsom denne facilitet i Allonnes, Frankrig, er faldet de seneste år EUs medlemsstater bør drage fordel af faldende omkostninger til vedvarende energi til at investere m -
 Forskere udforsker naturlig sprogbehandling for at vurdere skaktrækKomplet pipeline til træning af evalueringsmodellen. Kredit:arXiv:1907.08321 [cs.LG] Skak og kunstig intelligens er i nyhederne igen, denne gang i rapporter om et hold, der udforsker en model for
Forskere udforsker naturlig sprogbehandling for at vurdere skaktrækKomplet pipeline til træning af evalueringsmodellen. Kredit:arXiv:1907.08321 [cs.LG] Skak og kunstig intelligens er i nyhederne igen, denne gang i rapporter om et hold, der udforsker en model for -
 Google bekræfter, at de ønsker at frigive et betalingskortKredit:CC0 Public Domain Google håber, at du gerne vil have et mærkevarebetalingskort til din Google Pay-konto. Teknikgiganten gik sammen med Citibank og Stanford Federal Credit Union for at udfo
Google bekræfter, at de ønsker at frigive et betalingskortKredit:CC0 Public Domain Google håber, at du gerne vil have et mærkevarebetalingskort til din Google Pay-konto. Teknikgiganten gik sammen med Citibank og Stanford Federal Credit Union for at udfo -
 Sony køber det meste af EMI Music, at bruge $9B på billedsensorerSony Corp.-præsident Kenichiro Yoshida taler, mens karakterer fra Peanuts vises på en pressekonference i virksomhedens hovedkvarter tirsdag, 22. maj, 2018, i Tokyo. Elektronik- og underholdningsvirkso
Sony køber det meste af EMI Music, at bruge $9B på billedsensorerSony Corp.-præsident Kenichiro Yoshida taler, mens karakterer fra Peanuts vises på en pressekonference i virksomhedens hovedkvarter tirsdag, 22. maj, 2018, i Tokyo. Elektronik- og underholdningsvirkso
- Hvordan planter drikkevand?
- Fra krigselefanter til billig elektronik:Moderne globalisering har sine rødder i ældgamle handelsn…
- Stipendier gør bemærkelsesværdigt lidt for at gøre private skoler mere socialt inkluderende, und…
- Metoden samler cellulose nanofibre til et materiale, der er stærkere end edderkoppesilke
- Hvordan stratosfærisk liv lærer os om muligheden for ekstremt liv på andre verdener
- Stiksvampe giver nye spor til nitrogens skæbne i opvarmende tundra