


Hvor komplekst er dit liv? Dataloger fandt en måde at måle det på
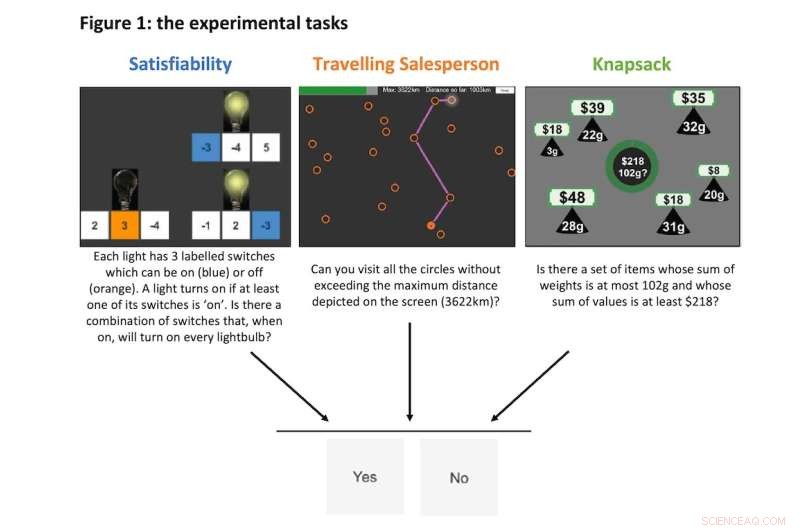
Her er eksempler på cases til de tre eksperimentelle opgaver, som hver krævede et ja eller nej svar fra vores forskningsdeltagere. Kredit:Juan Pablo Franco Ulloa/Karlo Doroc/Nitin Yadav
Nobelpristagers økonom Richard Thaler sagde berømt:"Folk er ikke dumme, verden er hård."
Faktisk støder vi rutinemæssigt på problemer i vores hverdag, der føles komplekse – fra at vælge den bedste el-plan til at beslutte, hvordan vi effektivt skal bruge vores penge.
Australier betaler hvert år hundredvis af millioner af dollars for at sammenligne websteder og forbrugerfokuserede grupper såsom CHOICE for at hjælpe dem med at træffe beslutninger om produkter og tjenester.
Men hvordan kan vi objektivt måle, hvor "komplekse" vores beslutninger egentlig er? Vores forskning, for nylig offentliggjort i Scientific Reports , tilbyder en potentiel måde at gøre dette på, ved at trække på koncepter fra computer- og systemvidenskab.
Hvorfor besvære at måle kompleksitet?
Der er flere faktorer, når det kommer til at måle kompleksitet i ethvert scenarie. For eksempel kan der være en række muligheder at vælge imellem, og hver mulighed kan have flere forskellige funktioner at overveje.
Antag, at du vil købe marmelade. Dette vil være nemt, hvis der kun er to smagsvarianter til rådighed, men svært, hvis der er dusinvis. Alligevel ville det være meget sværere at vælge en el-plan, selv med kun to muligheder.
Med andre ord, du kan ikke isolere en bestemt faktor, når du prøver at bestemme kompleksiteten af noget. Du skal overveje problemet som en helhed – og det kræver meget mere arbejde.
Evnen til nøjagtigt at måle kompleksitet kan have en lang række praktiske anvendelser, herunder at informere designet om:
- forordning om, hvor komplekse produkter skal være
- let at navigere i digitale systemer, herunder websteder, apps og smartenhedsprogrammer
- lette at forstå produkter. Disse kan være finansielle produkter (pensions- og forsikringsordninger, kreditkortordninger), fysiske produkter (enheder) eller virtuelle produkter (software)
- kunstig intelligens (AI), der giver råd, når problemer er for komplekse for mennesker. For eksempel kan en planlægger AI lade dig selv booke møder, før du hopper ind for at foreslå optimale mødetider og -steder baseret på din historik.
Sådan studerer vi menneskelig beslutningstagning
Datalogi kan hjælpe os med at løse problemer:information går ind, og en (eller flere) løsninger kommer ud. Mængden af beregning, der er nødvendig for dette, kan dog variere meget afhængigt af problemet.
Vi og vores kolleger brugte en præcis matematisk ramme, kaldet "beregningskompleksitetsteori", der kvantificerer, hvor meget beregning der er nødvendig for at løse et givet problem.
Ideen bag det er at måle mængden af beregningsressourcer (såsom tid eller hukommelse), en computeralgoritme har brug for, når den løser problemer. Jo mere tid eller hukommelse det har brug for, jo mere komplekst er problemet.
Når dette er etableret, kan problemer kategoriseres i "klasser" baseret på deres kompleksitet.
I vores arbejde var vi særligt interesserede i, hvordan kompleksitet (som bestemt gennem beregningsmæssig kompleksitetsteori) stemmer overens med den faktiske mængde indsats, folk skal lægge for at løse visse problemer.
Vi ønskede at vide, om beregningsmæssig kompleksitetsteori nøjagtigt kunne forudsige, hvor meget mennesker ville kæmpe i en bestemt situation, og hvor nøjagtig deres problemløsning ville være.
Test vores hypotese
Vi fokuserede på tre typer eksperimentelle opgaver, som du kan se eksempler på nedenfor. Alle disse opgavetyper ligger inden for en bredere klasse af komplekse problemer kaldet "NP-komplet" problemer.
Hver opgavetype kræver forskellige evner til at klare sig godt i. Specifikt:
- "tilfredsstillende"-opgaver kræver abstrakt logik
- Opgaver med "rejsende sælger" kræver rumlige navigationsfærdigheder og
- "knapsack"-opgaver kræver aritmetik.
Alle tre er allestedsnærværende i det virkelige liv og afspejler daglige problemer såsom softwaretest (tilfredshed), planlægning af en roadtrip (rejsende sælger) og shopping eller investering (knapsæk).
Vi rekrutterede 67 personer, delte dem op i tre grupper og fik hver gruppe til at løse mellem 64-72 forskellige variationer af en af de tre typer opgaver.
Vi brugte også beregningsmæssig kompleksitetsteori og computeralgoritmer til at finde ud af, hvilke opgaver der var "høj kompleksitet" for en computer, før vi sammenlignede disse med resultaterne fra vores menneskelige problemløsere.
Vi forventede – forudsat at teori om beregningskompleksitet er i overensstemmelse med hvordan rigtige mennesker løser problemer – at vores deltagere ville bruge mere tid på opgaver, der blev identificeret som værende "høj kompleksitet" for en computer. Vi forventede også lavere problemløsningsnøjagtighed på disse opgaver.
I begge tilfælde er det præcis, hvad vi fandt. I gennemsnit klarede folk sig dobbelt så godt i sagerne med den laveste kompleksitet sammenlignet med sagerne med den højeste kompleksitet.
Computervidenskab kan måle 'kompleksitet' for mennesker
Vores resultater tyder på, at indsats alene ikke er nok til at sikre, at nogen klarer sig godt på et komplekst problem. Nogle problemer vil være svære uanset hvad – og det er disse områder, hvor avancerede beslutningshjælpemidler og kunstig intelligens kan skinne.
Rent praktisk kunne det at være i stand til at måle kompleksiteten af en lang række opgaver hjælpe med at give folk den nødvendige støtte, de har brug for til at løse disse opgaver dagligt.
Det vigtigste resultat var, at vores beregningsmæssige kompleksitetsteori-baserede forudsigelser om, hvilke opgaver mennesker ville finde sværere, var konsistente på tværs af alle tre typer opgaver – på trods af at hver enkelt krævede forskellige evner at løse.
Desuden, hvis vi kan forudsige, hvor hårde mennesker vil finde opgaver inden for disse tre problemer, så burde det være i stand til at gøre det samme for de mere end 3.000 andre NP-komplette problemer.
Disse omfatter tilsvarende almindelige forhindringer såsom opgaveplanlægning, shopping, kredsløbsdesign og gameplay.
Nu skal forskningen omsættes i praksis
Selvom vores resultater er spændende, er der stadig lang vej igen. For det første brugte vores forskning hurtige og abstrakte opgaver i et kontrolleret laboratoriemiljø. Disse opgaver kan modellere valg i det virkelige liv, men de er ikke repræsentative for faktiske valg i det virkelige liv.
Det næste trin er at anvende lignende teknikker til opgaver, der mere ligner valg i det virkelige liv. Kan vi for eksempel bruge beregningsmæssig kompleksitetsteori til at måle kompleksiteten i at vælge mellem forskellige kreditkort?
Fremskridt på dette område kan hjælpe os med at låse op for nye måder at hjælpe folk med at træffe bedre valg hver dag på tværs af livets forskellige facetter. + Udforsk yderligere
Forskere udvikler algoritmer til at opdele opgaver for menneske-robothold
Denne artikel er genudgivet fra The Conversation under en Creative Commons-licens. Læs den originale artikel. 
 Varme artikler
Varme artikler
-
 EU:Facebook ændrer vilkår for at vise, at det tjener penge på dataI denne 29. marts, 2018 filfoto, logoet til Facebook vises på skærme på Nasdaq MarketSite, på Times Square i New York. Europa -Kommissionen siger, at Facebook har ændret det med småt i sine servicevil
EU:Facebook ændrer vilkår for at vise, at det tjener penge på dataI denne 29. marts, 2018 filfoto, logoet til Facebook vises på skærme på Nasdaq MarketSite, på Times Square i New York. Europa -Kommissionen siger, at Facebook har ændret det med småt i sine servicevil -
 Alexa, Cortana får endelig gang i samtalenKredit:CC0 Public Domain Amazons Alexa og Microsofts Cortana kommer snart til en smartenhed nær dig – sammen, med nye integrerede funktioner, der gør det muligt for de digitale assistenter at tale
Alexa, Cortana får endelig gang i samtalenKredit:CC0 Public Domain Amazons Alexa og Microsofts Cortana kommer snart til en smartenhed nær dig – sammen, med nye integrerede funktioner, der gør det muligt for de digitale assistenter at tale -
 Daimler sænker overskudsprognosen, skylden på tolden mellem USA og KinaDen tyske luksusbilproducent Daimler har reduceret sine forventninger til 2019 Den tyske luksusbilproducent Daimler har onsdag reduceret sin overskudsprognose for 2018. skyder skylden på nye tolds
Daimler sænker overskudsprognosen, skylden på tolden mellem USA og KinaDen tyske luksusbilproducent Daimler har reduceret sine forventninger til 2019 Den tyske luksusbilproducent Daimler har onsdag reduceret sin overskudsprognose for 2018. skyder skylden på nye tolds -
 Lyft gør op med en børsnotering, der ønsker at rejse 2,4 mia. DollarsLyft kunne vurderes til mere end 20 milliarder dollar under betingelserne i det første offentlige udbud Lyft sagde mandag, at det ville søge at rejse så meget som $ 2,4 milliarder i sit offentlige
Lyft gør op med en børsnotering, der ønsker at rejse 2,4 mia. DollarsLyft kunne vurderes til mere end 20 milliarder dollar under betingelserne i det første offentlige udbud Lyft sagde mandag, at det ville søge at rejse så meget som $ 2,4 milliarder i sit offentlige
- Undersøgelse udforsker regnbuebølger og identitetsgab i LGBTQ-liberale politiske perspektiver
- Antilock bremsesystem i arterier beskytter mod hjerteanfald
- Ny teknik til at studere molekyler og materialer på kvantesimulator opdaget
- Pulseringer registreret i en varm, helium-atmosfære hvid dværg
- Tusindvis af havfiskerbåde kunne bruge tvangsarbejde - vi brugte AI og satellitdata til at finde de…
- Australien bør lære af globalt brintfokus, siger rapporten