


Open source-software til data fra højenergifysik

Foreslåede filamenter af mørkt stof, der omgiver Jupiter, kan være en del af de mystiske 95 procent af universets masseenergi. Kredit:NASA/JPL-Caltech
Det meste af universet er mørkt, med mørkt stof og mørk energi, der udgør mere end 95 procent af dets masse-energi. Alligevel ved vi lidt om mørkt stof og energi. For at finde svar, forskere udfører enorme højenergifysiske eksperimenter. At analysere resultaterne kræver højtydende computing – nogle gange afbalanceret med industrielle tendenser.
Efter fire år med at køre computere til Large Hadron Collider CMS-eksperimentet på CERN nær Genève, Schweiz - en del af værket, der afslørede Higgs-bosonen - Oliver Gutsche, en videnskabsmand ved Department of Energy's (DOE) Fermi National Accelerator Laboratory, vendte sig mod søgen efter mørkt stof. "Higgs-bosonen var blevet forudsagt, og vi vidste omtrent, hvor vi skulle lede, " siger han. "Med mørkt stof, vi ved ikke, hvad vi leder efter."
For at lære om mørkt stof, Gutsche har brug for flere data. Når disse oplysninger er tilgængelige, fysikere skal mine det. De udforsker beregningsværktøjer til jobbet, inklusive Apache Spark open source-software.
På jagt efter mørkt stof, fysikere studerer resultater fra kolliderende partikler. "Dette er trivielt at parallelisere, "at bryde jobbet i stykker for at få svar hurtigere, Gutsche forklarer. "To pc'er kan hver behandle en kollision, " hvilket betyder, at forskere kan bruge et computernet til at analysere data.
Meget af arbejdet i højenergifysik, selvom, afhænger af software, som forskerne udvikler. "Hvis vores kandidatstuderende og postdocs kun kender vores proprietære værktøjer, så får de problemer, hvis de går til industrien, "hvor sådan software ikke er tilgængelig, Gutsche bemærker. "Så jeg begyndte at se nærmere på Spark."
Spark er et datareduktionsværktøj lavet til ustrukturerede tekstfiler. Det skaber en udfordring – adgang til højenergifysikdata, som er i et objektorienteret format. Fermilabs datalogiforskere Saba Sehrish og Jim Kowalkowski tager fat på opgaven.
Spark lovede fra begyndelsen, med nogle særligt interessante funktioner, siger Sehrish. "Den ene var i hukommelsen, storskala distribueret behandling" gennem grænseflader på højt niveau, hvilket gør det nemt at bruge. "Du ønsker ikke, at videnskabsmænd skal bekymre sig om, hvordan man distribuerer data og skriver parallel kode, " siger hun. Spark tager sig af det.
En anden attraktiv funktion:Spark er en understøttet forskningsplatform ved National Energy Research Scientific Computing Center (NERSC), en DOE Office of Science brugerfacilitet ved DOE's Lawrence Berkeley National Laboratory. "Dette giver os et supportteam, der kan tune det, " siger Kowalkowski. Dataloger som Sehrish og Kowalkowski kan tilføje kapaciteter, men at få den underliggende kode til at fungere så effektivt som muligt kræver Spark-specialister, hvoraf nogle arbejder på NERSC.
Kowalkowski opsummerer Sparks ønskværdige funktioner som "automatiseret skalering, automatiseret parallelisme og en fornuftig programmeringsmodel."
Kort sagt, han og Sehrish ønsker at bygge et system, der giver forskere mulighed for at køre en analyse, der yder ekstremt godt på store maskiner uden komplikationer og gennem en nem brugergrænseflade.
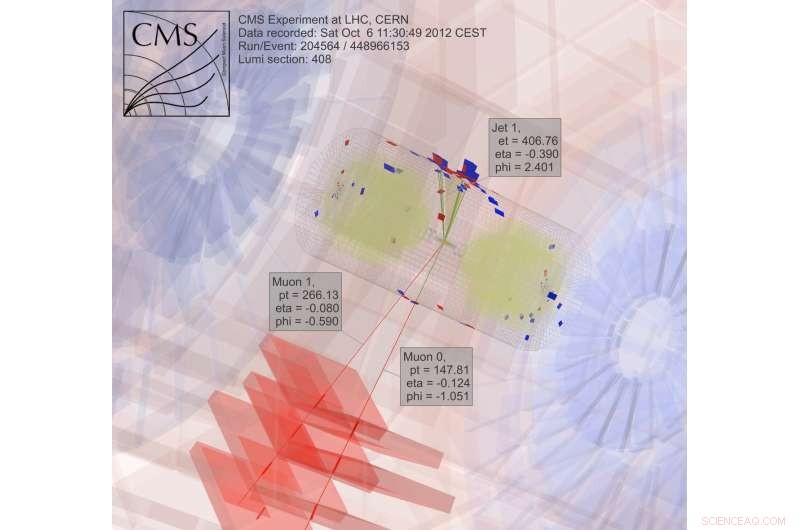
For at søge efter mørkt stof, forskere indsamler og analyserer resultater fra kolliderende partikler, en ekstremt beregningsmæssig intens proces. Kredit:CMS CERN
Bare det er nemt at bruge, selvom, er ikke nok, når man beskæftiger sig med data fra højenergifysik. Spark ser ud til at opfylde både brugervenlighed og præstationsmål til en vis grad. Forskere undersøger stadig nogle aspekter af dens ydeevne til højenergifysikapplikationer, men dataloger kan ikke få alt. "Der er et kompromis, " siger Sehrish. "Når du leder efter mere ydeevne, du bliver ikke brugervenlig."
Fermilab-forskerne valgte Spark som et første valg til at udforske big-data videnskab, og mørkt stof er blot den første applikation, der testes. "Vi har brug for flere sager til virkelig brug for at forstå gennemførligheden af at bruge Spark til en analyseopgave, " siger Sehrish. Med videnskabsmænd som Gutsche ved Fermilab, mørkt stof var et godt sted at starte. Sehrish og Kowalkowski ønsker at forenkle livet for videnskabsmænd, der driver analysen. "Vi arbejder sammen med forskere for at forstå deres data og arbejde med deres analyse, " siger Sehrish. "Så kan vi hjælpe dem med bedre at organisere datasæt, bedre organisere analyseopgaver."
Som et første skridt i den proces, Sehrish og Kowalkowski skal hente data fra højenergifysikeksperimenter ind i Spark. Bemærkninger Kowalkowski, "Du har petabytes af data i specifikke eksperimentelle formater, som du skal omdanne til noget nyttigt til en anden platform."
Startdataene for mørkt stof-implementeringen er formateret til computerplatforme med høj kapacitet, men Spark håndterer ikke den konfiguration. Så software skal læse det originale dataformat og konvertere det til noget, der fungerer godt med Spark.
Ved at gøre dette, Sehrish forklarer, "Du skal overveje enhver beslutning ved hvert trin, fordi hvordan du strukturerer dataene, hvordan du læser det ind i hukommelsen og designer og implementerer operationer til høj ydeevne, er alt sammen forbundet."
Hvert af disse datahåndteringstrin påvirker Sparks ydeevne. Selvom det er for tidligt at sige, hvor meget ydeevne der kan hentes fra Spark, når man analyserer mørkt stof-data, Sehrish og Kowalkowski ser, at Spark kan levere brugervenlig kode, der gør det muligt for højenergifysikforskere at starte et job på hundredtusindvis af kerner. "Spark er god i den henseende, " siger Sehrish. "Vi har også set god skalering – ikke spild af computerressourcer, da vi øger datasættets størrelse og antallet af noder."
Ingen ved, om dette vil være en levedygtig tilgang, før man bestemmer Sparks højeste ydeevne for disse applikationer. "Den vigtigste nøgle, "Kowalkowski siger, "er, at vi endnu ikke er overbevist om, at dette er teknologien til at gå fremad."
Faktisk, Selve gnisten ændrer sig. Dens omfattende open source-brug skaber en konstant og hurtig udviklingscyklus. Så Sehrish og Kowalkowski skal holde deres kode oppe med Sparks nye muligheder.
"Den konstante vækstcyklus med Spark er omkostningerne ved at arbejde med avanceret teknologi og noget med mange udviklingsinteresser, " siger Sehrish.
Der kan gå nogle år, før Sehrish og Kowalkowski træffer en beslutning om Spark. Konvertering af software skabt til high-throughput computing til gode højtydende computerværktøjer, der er nemme at bruge, kræver finjustering og teamarbejde mellem eksperimentelle og beregningsmæssige videnskabsmænd. Eller, du kan sige, det kræver mere end et skud i mørket.
 Varme artikler
Varme artikler
-
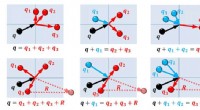 Forskere løser fire-phonon termisk konduktivitetshindringsnøgle til tekniske applikationerDisse diagrammer beskriver samspillet mellem fire fononer, kvantemekaniske fænomener relateret til virkningerne af varmeledning i faste materialer. I sådanne fire-fonon-interaktioner, ”En fonon deler
Forskere løser fire-phonon termisk konduktivitetshindringsnøgle til tekniske applikationerDisse diagrammer beskriver samspillet mellem fire fononer, kvantemekaniske fænomener relateret til virkningerne af varmeledning i faste materialer. I sådanne fire-fonon-interaktioner, ”En fonon deler -
 3-D virtuel udskæring af en antik violin afslører ældgamle lakeringsmetoderKredit:CC0 Public Domain Italienske violinfremstillere fra den fjerne fortid udviklede lakeringsteknikker, der gav deres instrumenter både en fremragende musikalsk tone og et imponerende udseende.
3-D virtuel udskæring af en antik violin afslører ældgamle lakeringsmetoderKredit:CC0 Public Domain Italienske violinfremstillere fra den fjerne fortid udviklede lakeringsteknikker, der gav deres instrumenter både en fremragende musikalsk tone og et imponerende udseende. -
 Hvorfor tilintetgjorde universet sig selv? Neutrinoer kan have svaretBegivenhedsvisning for en kandidat elektronneutrino. Kredit:T2K Alysia Marino og Eric Zimmerman, fysikere ved CU Boulder, har været på jagt efter neutrinoer i de sidste to årtier. Det er ikke let
Hvorfor tilintetgjorde universet sig selv? Neutrinoer kan have svaretBegivenhedsvisning for en kandidat elektronneutrino. Kredit:T2K Alysia Marino og Eric Zimmerman, fysikere ved CU Boulder, har været på jagt efter neutrinoer i de sidste to årtier. Det er ikke let -
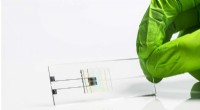 Fremstilling af fluorescerende chips ved hjælp af en inkjetprinterLommelaboratorium:Fraunhofer IOFs nye udskrivbare fluorescenssensorer håber at kunne tilbyde en hurtig og nem måde at opdage sygdomsmarkører i blodet. Kredit:Fraunhofer IOF Hver måltid er det samm
Fremstilling af fluorescerende chips ved hjælp af en inkjetprinterLommelaboratorium:Fraunhofer IOFs nye udskrivbare fluorescenssensorer håber at kunne tilbyde en hurtig og nem måde at opdage sygdomsmarkører i blodet. Kredit:Fraunhofer IOF Hver måltid er det samm
- Omfanget af menneskelig indflydelse på planeten har ændret forløbet af Jordens historie, forskere…
- Klimakrisen er kommet - så stop med at føle skyld og begynd at forestille dig din fremtid
- Optiske hemmeligheder af disulfid nanorør er beskrevet
- Mansplaining:Nye løsninger på et trættende gammelt problem
- Hvor kommer gas fra Amerika?
- Sårbare kvinder opsøger mest sandsynligt centre for seksuelle overgreb