


En ny metode til modellering af lægemiddel-målinteraktioner løser en skadelig bias for tidligere teknikker
"Opdagelse af stoffer er en meget lang proces. På hvert trin har du finder måske ud af, at din medicin ikke er god nok, og du skal søge en anden kandidat, "forklarer A*STARs Xiao-Li Li. Hans team vandt 'bedste papir' ved den internationale konference om bioinformatik i 2016 for en ny tilgang til at rette et iboende problem med maskinlæringsmetoder.
Computersimulering, eller 'in silico' lægemiddelopdagelsesteknikker, kan forbedre nøjagtigheden og reducere den trukne, enormt dyr vej til at bringe et lægemiddel på markedet - i gennemsnit mere end 12 år og 1,8 mia. US $.
Mange computersimuleringer kræver dog først 'træning' i datasæt af kendte lægemidler og deres mål. Disse data kan omfatte yderligere oplysninger om 3D-struktur, kemisk sammensætning, og andre molekylære egenskaber. På baggrund af tendenser fra denne database med kendte data, simuleringen kan derefter forudsige interaktioner mellem ukendte molekyler - hvilket fører til nye lægemidler og nye målproteiner.
Imidlertid, af alle lægemidler og mål i databasen, kun visse kombinationer vil interagere. Potentielle parringer opvejes langt af ikke-interagerende par, der omtales som 'ubalance mellem klasser'. Yderligere ubalance er til stede i form af forskellige og ulige subtyper af interaktion, kaldet 'inden for klassen ubalance'.
"Alle beregningsmodeller, der er designet til at optimere nøjagtigheden, vil være forudindtaget og vil have en tendens til at klassificere ukendte par i flertals- eller ikke-interaktionsklasser, "siger Li." Majoritetsklasser er bedre repræsenteret i data end minoritetsinteraktionsklasser - det skæver disse modeller og producerer fejl. Ubalance i data er et udfordrende problem. "
Li's team ved A*STAR Institute for Infocomm Research, søgt at overvinde dette ved at udvikle en 'ubalance-bevidst' algoritme, der mere præcist forudsagde lægemiddel-målinteraktioner baseret på en database med 12, 600 kendte interaktioner og omkring 18 millioner kendte ikke-interagerende par. Algoritmen var designet til bedre at genkende underrepræsenterede interaktionsgrupper og forbedre dataene i dem.
Ved at forbedre computermodellens evne til at fokusere på de mest nyttige data (interaktionerne), teamet skabte et system, der udkonkurrerede eksisterende modelleringsteknikker, forudsiger nyt, ukendte lægemiddel-interaktioner med høj nøjagtighed.
Fremtiden for maskinlæring afhænger af kunstig intelligens og avanceret læring såsom 'dyb læring'. Alligevel, som Li tilføjer:"data er nøglen. For yderligere at forbedre vores forudsigelsesevne, den første ting, vi kan gøre, er at indsamle mere relevante data om medicin og mål. "
 Varme artikler
Varme artikler
-
 Radikal afsaltningstilgang kan forstyrre vandindustrienIllustration, der beskriver ferskvandsproduktion fra hypersalinlake ved ekstraktion af temperatursvingende opløsningsmidler. Kredit:Chanhee Boo/Columbia Engineering Hypersalin saltlage - vand, der
Radikal afsaltningstilgang kan forstyrre vandindustrienIllustration, der beskriver ferskvandsproduktion fra hypersalinlake ved ekstraktion af temperatursvingende opløsningsmidler. Kredit:Chanhee Boo/Columbia Engineering Hypersalin saltlage - vand, der -
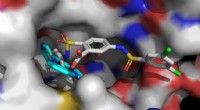 Mod udvikling af lægemidler til aldringsrelaterede sygdommeSirt6-aktivatorerne UBCS039 (cyan, foran til venstre) og MDL-801 (flerfarvet, foran til højre) er forankret i den samme bindingslomme på Sirt6. Det længere MDL-801-molekyle kontakter også tilstødende
Mod udvikling af lægemidler til aldringsrelaterede sygdommeSirt6-aktivatorerne UBCS039 (cyan, foran til venstre) og MDL-801 (flerfarvet, foran til højre) er forankret i den samme bindingslomme på Sirt6. Det længere MDL-801-molekyle kontakter også tilstødende -
 Ny teknologi kan hjælpe med at afvise vand, redde liv gennem forbedret medicinsk udstyrDette billede viser en vanddråbe på en skabt superhydrofob overflade, viser en meget høj kontaktvinkel. Purdue University-forskere udviklede en ny fremstillingsproces til at skabe interne hydrofobe ov
Ny teknologi kan hjælpe med at afvise vand, redde liv gennem forbedret medicinsk udstyrDette billede viser en vanddråbe på en skabt superhydrofob overflade, viser en meget høj kontaktvinkel. Purdue University-forskere udviklede en ny fremstillingsproces til at skabe interne hydrofobe ov -
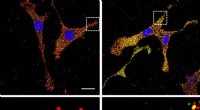 Billeddannelse af mRNA lige der, hvor det er lavet - på stedet for translationForskere bruger fluorescensprober til at overvåge stigninger i mRNA-ribosominteraktionsniveauer for et gen, der er forbundet med jernlagring som reaktion på jern (højre paneler). Målestok =20 μm. Kred
Billeddannelse af mRNA lige der, hvor det er lavet - på stedet for translationForskere bruger fluorescensprober til at overvåge stigninger i mRNA-ribosominteraktionsniveauer for et gen, der er forbundet med jernlagring som reaktion på jern (højre paneler). Målestok =20 μm. Kred
- Demonstration af et enkelt molekyle piezoelektrisk effekt
- Stiger skovhøsten i Europa? Naturens svar rejser tvivl om kontroversielle undersøgelsespåstande
- Hvad spiser Rosellas?
- Nye syntetiske biologiværktøjer låser op for kompleks anlægsteknik
- Ny bordpladeteknik sonderer de yderste elektroner af atomer dybt inde i faste stoffer
- At kende en transkønnet person kan påvirke ens politiske holdning, undersøgelse finder