


Brug af maskinlæring til at designe peptider
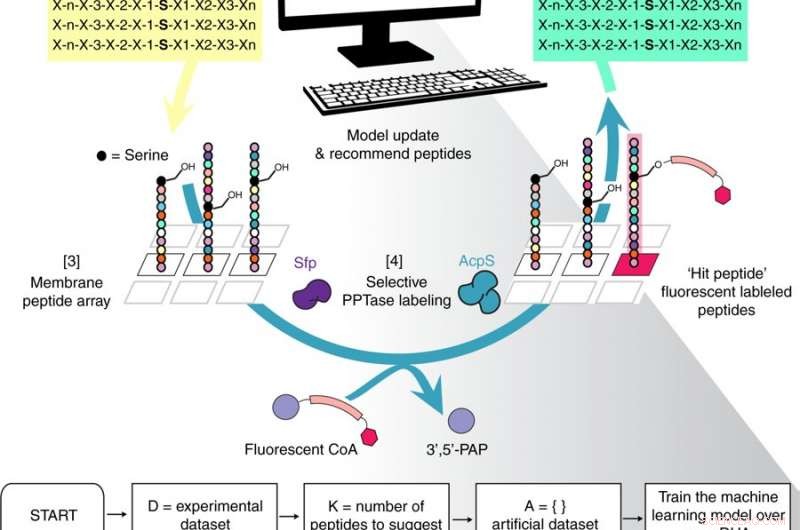
Oversigt over den iterative Peptid Optimering med Optimal Learning (POOL) metode workflow. Kredit: Naturkommunikation (2018). DOI:10.1038/s41467-018-07717-6
Forskere og ingeniører har længe været interesseret i at syntetisere peptider - kæder af aminosyrer, der er ansvarlige for at udføre mange funktioner i celler - for både at efterligne naturen og for at udføre nye aktiviteter. Et designet peptid, for eksempel, kan være et funktionelt lægemiddel, der virker i visse områder i kroppen uden at nedbryde, en vanskelig opgave for mange peptider.
Men metoder til at opdage og syntetisere peptider er dyre og tidskrævende, ofte involveret måneder eller år med gætværk og fiasko.
Northwestern University forskere, samarbejder med samarbejdspartnere på Cornell University og University of California, San Diego, har udviklet en ny måde at finde optimale peptidsekvenser på:ved at bruge en maskinlæringsalgoritme som samarbejdspartner.
Algoritmen analyserer eksperimentelle data og giver forslag til den næstbedste sekvens at prøve, skabe en frem og tilbage udvælgelsesproces, der drastisk reducerer den tid, der er nødvendig for at finde det optimale peptid.
Resultaterne, som kunne give en ny ramme for eksperimenter på tværs af materialevidenskab og kemi, blev udgivet i Naturkommunikation den 7. december.
"Vi ser dette som den næste bølge i, hvordan vi designer molekyler og materialer, " sagde Northwestern professor Nathan Gianneschi, en tilsvarende forfatter på papiret. "Vi kan kombinere det, vi kender fra intuitionen med kraften i en algoritme og finde løsningen med færre eksperimenter."
Gianneschi er Jacob og Rosaline Cohn-professor i afdelingen for kemi i Northwesterns Weinberg College of Arts and Sciences og i afdelingerne for materialevidenskab og ingeniørvidenskab og for biomedicinsk teknik ved Northwestern Engineering.
For at skabe metoden, Gianneschi, som også er associeret direktør for Northwestern's International Institute for Nanotechnology, gik sammen med Peter Frazier, en lektor ved Cornell, der arbejder med operationsforskning og maskinlæring, og Michael Burkart, en kemisk biolog og ekspert i enzymologi ved UC San Diego, at finde en bedre måde at lave peptider på, der kunne generere biomaterialer – specifikt nanostrukturer og mikrostrukturer, der kunne modificere proteiner på bestemte måder. Det første skridt var at finde de rigtige peptider, der ville fungere som enzymatiske substrater for disse strukturer.
Peptider er bygget af kæder af aminosyrer, der kan være så mange som 20 aminosyrer lange, med 20 forskellige muligheder for hver syre. Da sekvensen bestemmer peptidfunktionen, at finde ud af optimale sekvenser kræver dyre eksperimenter, der ofte udføres med gætværk.
Eksperimentalisterne, Gianneschi og Burkart, arbejdet sammen med Frazier over flere år for at udvikle et system, der kombinerede eksperimentelle data med en maskinlæringsalgoritme for at finde de bedste strategier til at skabe nye materialer.
Efter at Frazier havde designet algoritmen og de to arbejdede sammen om at træne den, eksperimentelerne udviklede en række af 100 peptider, udførte eksperimenter for at finde ud af, hvilke der virkede, som de var beregnet til, derefter fodret den information ind i algoritmen. Algoritmen anbefalede derefter, hvad der skulle ændres til den næste runde af peptidudvikling, og anbefalede også strategier, som den troede ville mislykkes.
"Nu begyndte vi at få selektivitet, " sagde Gianneschi. Ved at fuldføre denne proces flere gange, de var i stand til at finde de optimale peptider.
"I stedet for at gætte og se på millioner af peptider, vi var i stand til at se på hundredvis af peptider og meget hurtigt konvergere på sekvenser, der opførte sig på helt nye måder, " sagde han. Sammenlignet med tilfældige mutationer eller gætværk, algoritmemetoden var statistisk langt mere vellykket.
Selvom dette arbejde fokuserede på substrater, denne proces kan bruges til at opdage peptider til enhver form for formål, som medicinafgivelse, og måske endda bruges til at opdage DNA-sekvenser, såvel. Fordi enhver form for optimal sekvens kunne opdages, forskere er heller ikke begrænset til, hvilke aminosyresekvenser der findes i den genetiske kode.
Det næste trin vil være at automatisere hele processen. Gianneschi er også interesseret i at bruge metoden til at finde optimale overflader til polymerer, specifikt polymerer, der anvendes i medicinske implantater. At finde de rigtige overflader, der vil binde sig til væv eller muskler, kan hjælpe med at forhindre arvæv eller implantatafstødning.
"Du kunne i det væsentlige opdage sekvenser, der gør specifikke ting, som virkelig er kernen i, hvad peptider og nukleinsyrer gør i naturen, " sagde han. "Dette kan revolutionere, hvordan vi laver peptider."
 Varme artikler
Varme artikler
-
 Mini-centrifuge til enklere undersøgelse af blodceller åbner nye organ-på-chip-mulighederFlydende metal dråbe, bruges til at lave mini-centrifugen, sidder på kanalen, hvor prøver til sidst vil blive pumpet igennem. Kredit:RMIT University En simpel innovation på størrelse med et sandko
Mini-centrifuge til enklere undersøgelse af blodceller åbner nye organ-på-chip-mulighederFlydende metal dråbe, bruges til at lave mini-centrifugen, sidder på kanalen, hvor prøver til sidst vil blive pumpet igennem. Kredit:RMIT University En simpel innovation på størrelse med et sandko -
 Eksempler på sure buffereBufferopløsninger modstår ændring i pH. En opløsning af en syre og dens konjugatbase vil virke som en buffer; bufferens kapacitet afhænger af hvor meget af syren og den konjugerede base der er til ste
Eksempler på sure buffereBufferopløsninger modstår ændring i pH. En opløsning af en syre og dens konjugatbase vil virke som en buffer; bufferens kapacitet afhænger af hvor meget af syren og den konjugerede base der er til ste -
 En metalfri, bæredygtig tilgang til reduktion af kuldioxidRepræsentation af den proces, hvorved formiatsalte tjener som aktive og selektive katalysatorer til hydrosilylering af CO2. Kredit:ACS Sustainable Chem. Eng. Forskere i Japan har præsenteret en or
En metalfri, bæredygtig tilgang til reduktion af kuldioxidRepræsentation af den proces, hvorved formiatsalte tjener som aktive og selektive katalysatorer til hydrosilylering af CO2. Kredit:ACS Sustainable Chem. Eng. Forskere i Japan har præsenteret en or -
 Fremskridt i jagten på ukendte forbindelser i drikkevandKredit:CC0 Public Domain Et ukendt antal biprodukter dannes i drikkevandsbehandlingsprocessen, og forskere ved ikke, hvad mange af dem er. Imidlertid, ved hjælp af avanceret teknologi, forskere ve
Fremskridt i jagten på ukendte forbindelser i drikkevandKredit:CC0 Public Domain Et ukendt antal biprodukter dannes i drikkevandsbehandlingsprocessen, og forskere ved ikke, hvad mange af dem er. Imidlertid, ved hjælp af avanceret teknologi, forskere ve
- Blandede følelser i nye økonomier på smartphones, sociale medier
- Planteliv i barskoven
- Portland planlægger at foreslå det første forbud mod ansigtsgenkendelse, der påvirker private vi…
- Hvordan man fortæller, om en kardinalfugl er mand eller kvinde
- En mere sikker måde at implementere bakterier som miljøsensorer
- Indrammet af køn:Kvindelige kunstnere slettet fra toppriser, salg på kunstauktioner