


IBM-forskere demonstrerer in-memory computing med 1 million enheder til applikationer i AI

En million processer er kortlagt til pixels i en 1000 × 1000 pixel sort-hvid skitse af Alan Turing. Pixels tændes og slukkes i overensstemmelse med de øjeblikkelige binære værdier af processerne. Kredit:Nature Communications
"In-memory computing" eller "computational memory" er et spirende koncept, der bruger de fysiske egenskaber af hukommelsesenheder til både lagring og behandling af information. Dette er i modstrid med de nuværende von Neumann systemer og enheder, såsom almindelige stationære computere, bærbare computere og endda mobiltelefoner, som flytter data frem og tilbage mellem hukommelsen og computerenheden, hvilket gør dem langsommere og mindre energieffektive.
I dag, IBM Research annoncerer, at dets forskere har påvist, at en uovervåget maskinlæringsalgoritme, kører på en million phase change memory (PCM) enheder, med succes fundet tidsmæssige korrelationer i ukendte datastrømme. Sammenlignet med avancerede klassiske computere, denne prototypeteknologi forventes at give 200x forbedringer i både hastighed og energieffektivitet, hvilket gør den særdeles velegnet til at muliggøre ultratæt, lav strøm, og massivt parallelle computersystemer til applikationer i AI.
Forskerne brugte PCM-enheder lavet af en germanium antimon tellurid-legering, som er stablet og klemt mellem to elektroder. Når forskerne tilfører en lille elektrisk strøm til materialet, de opvarmer det, som ændrer sin tilstand fra amorf (med et uordnet atomarrangement) til krystallinsk (med en ordnet atomkonfiguration). IBM-forskerne har brugt krystalliseringsdynamikken til at udføre beregninger på plads.
"Dette er et vigtigt skridt fremad i vores forskning af AIs fysik, som udforsker nye hardwarematerialer, enheder og arkitekturer, " siger Dr. Evangelos Eleftheriou, en IBM Fellow og medforfatter til papiret. "Efterhånden som CMOS-skaleringslovene bryder sammen på grund af teknologiske begrænsninger, en radikal afvigelse fra processor-hukommelse-dikotomien er nødvendig for at omgå begrænsningerne for nutidens computere. I betragtning af enkelheden, høj hastighed og lav energi af vores in-memory computing tilgang, det er bemærkelsesværdigt, at vores resultater er så lig vores benchmark klassiske tilgang, der køres på en von Neumann-computer."
Detaljerne er forklaret i deres papir, der vises i dag i peer-review-tidsskriftet Naturkommunikation . For at demonstrere teknologien, forfatterne valgte to tidsbaserede eksempler og sammenlignede deres resultater med traditionelle maskinlæringsmetoder, såsom k-betyder klyngedannelse:
- Simulerede data:en million binære (0 eller 1) tilfældige processer organiseret på et 2-D-gitter baseret på en 1000 x 1000 pixel, sort og hvid, profiltegning af den berømte britiske matematiker Alan Turing. IBM-forskerne fik derefter pixels til at blinke til og fra med samme hastighed, men de sorte pixels tændte og slukkede på en svagt korreleret måde. Det betyder, at når en sort pixel blinker, der er lidt større sandsynlighed for, at en anden sort pixel også blinker. De tilfældige processer blev tildelt en million PCM-enheder, og en simpel indlæringsalgoritme blev implementeret. For hvert blink, PCM-arrayet lærte, og PCM-enhederne svarende til de korrelerede processer gik til en højkonduktanstilstand. På denne måde konduktanskortet for PCM-enhederne genskaber tegningen af Alan Turing. (se billedet ovenfor)
- Real-World Data:faktiske nedbørsdata, indsamlet over en periode på seks måneder fra 270 vejrstationer over hele USA i en times intervaller. Hvis det regner inden for en time, det var mærket "1", og hvis det ikke var "0". Klassisk k-betyder clustering og in-memory computing-tilgangen blev enige om klassificeringen af 245 ud af de 270 vejrstationer. In-memory computing klassificerede 12 stationer som ukorrelerede, der var blevet markeret korreleret med k-betyder klyngetilgangen. Tilsvarende in-memory computing-tilgangen klassificerede 13 stationer som korrelerede, der var blevet markeret ukorrelerede ved k-betyder klyngedannelse.
"Hukommelse er hidtil blevet betragtet som et sted, hvor vi blot gemmer information. Men i dette arbejde, vi viser endegyldigt, hvordan vi kan udnytte disse hukommelsesenheders fysik til også at udføre en beregningsprimitiv på et ret højt niveau. Resultatet af beregningen gemmes også i hukommelsesenhederne, og i denne forstand er konceptet løst inspireret af, hvordan hjernen beregner." sagde Dr. Abu Sebastian, udforskende hukommelse og kognitiv teknologi videnskabsmand, IBM Research og hovedforfatter af papiret.
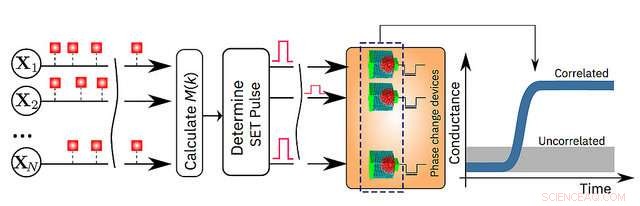
En skematisk illustration af in-memory computing-algoritmen. Kredit:IBM Research
 Varme artikler
Varme artikler
-
 Triboelektriske nanogeneratorer øger massespektrometriydelsenEt bevis på konceptet triboelektrisk nanogenerator producerer elektriske ladninger for et massespektrometer. Georgia Tech-forskere har vist, at udskiftning af konventionelle strømforsyninger med TENG-
Triboelektriske nanogeneratorer øger massespektrometriydelsenEt bevis på konceptet triboelektrisk nanogenerator producerer elektriske ladninger for et massespektrometer. Georgia Tech-forskere har vist, at udskiftning af konventionelle strømforsyninger med TENG- -
 Det fineste guldstøv i verdenSMT-billede af jernoxidoverfladen - med guldatomer på toppen (Phys.org) -- Forskere ved Wiens teknologiske universitet fandt en metode til at lokalisere enkelte guldatomer på en overflade. Dette s
Det fineste guldstøv i verdenSMT-billede af jernoxidoverfladen - med guldatomer på toppen (Phys.org) -- Forskere ved Wiens teknologiske universitet fandt en metode til at lokalisere enkelte guldatomer på en overflade. Dette s -
 Ingeniører opfinder en metode til at kontrollere lysudbredelse i bølgeledereEt par realiserede bølgeledertilstandskonvertere. Enhederne består af fasede arrays af guld nano-antenner mønstret på silicium bølgeledere. Hændelse og konverterede bølgeledertilstande vises til venst
Ingeniører opfinder en metode til at kontrollere lysudbredelse i bølgeledereEt par realiserede bølgeledertilstandskonvertere. Enhederne består af fasede arrays af guld nano-antenner mønstret på silicium bølgeledere. Hændelse og konverterede bølgeledertilstande vises til venst -
 En klynge på tyve atomer af guld visualiseret for første gangTetraeder med 20 guldatomer. Billedkredit:University of Birmingham (Phys.org) - Forskere ved University of Birmingham har udviklet en metode til at visualisere guld på nanoskalaen ved hjælp af en
En klynge på tyve atomer af guld visualiseret for første gangTetraeder med 20 guldatomer. Billedkredit:University of Birmingham (Phys.org) - Forskere ved University of Birmingham har udviklet en metode til at visualisere guld på nanoskalaen ved hjælp af en
- Forskere udvikler værktøjer til at skærpe 3D-visning af store RNA-molekyler
- Sådan måler du tætheden af en planet
- Kemiens Alexa:Forskere på hurtig vej til at bygge åbent netværk
- Undersøgelse:Bred bipartisan støtte til mærkning af sociale medier for at imødegå misinformatio…
- Mexico:Bygherrer bulldozerer udkanten af Teotihuacan-ruinerne
- Pas på kløften – Rapid Burster-adfærd forklaret