


Forsker udvikler en chatbot med ekspertise i nanomaterialer

En forsker er netop færdig med at skrive en videnskabelig artikel. Hun ved, at hendes arbejde kan drage fordel af et andet perspektiv. Overså hun noget? Eller måske er der en anvendelse af hendes forskning, hun ikke havde tænkt på. Et andet sæt øjne ville være fantastisk, men selv de venligste samarbejdspartnere vil måske ikke være i stand til at spare tid til at læse alle de nødvendige baggrundspublikationer for at indhente det.
Kevin Yager – leder af gruppen af elektroniske nanomaterialer ved Center for Functional Nanomaterials (CFN), et US Department of Energy (DOE) Office of Science User Facility ved DOE's Brookhaven National Laboratory – har forestillet sig, hvordan de seneste fremskridt inden for kunstig intelligens (AI) og maskinlæring (ML) kunne hjælpe videnskabelig brainstorming og idéer. For at opnå dette har han udviklet en chatbot med viden om den slags videnskab, han har været engageret i.
Hurtige fremskridt inden for AI og ML har givet plads til programmer, der kan generere kreativ tekst og nyttig softwarekode. Disse generelle chatbots har for nylig fanget offentlighedens fantasi. Eksisterende chatbots – baseret på store, forskellige sprogmodeller – mangler detaljeret viden om videnskabelige underdomæner.
Ved at udnytte en metode til dokumenthentning er Yagers bot vidende om områder inden for nanomaterialevidenskab, som andre bots ikke er. Detaljerne om dette projekt, og hvordan andre videnskabsmænd kan udnytte denne AI-kollega til deres eget arbejde, er for nylig blevet offentliggjort i Digital Discovery .
Roboternes opståen
"CFN har i lang tid undersøgt nye måder at udnytte AI/ML til at accelerere opdagelse af nanomateriale. I øjeblikket hjælper det os med hurtigt at identificere, katalogisere og vælge prøver, automatisere eksperimenter, styre udstyr og opdage nye materialer. Esther Tsai, en videnskabsmand i gruppen af elektroniske nanomaterialer på CFN, er ved at udvikle en AI-ledsager til at hjælpe med at fremskynde materialeforskningseksperimenter ved National Synchrotron Light Source II (NSLS-II)." NSLS-II er en anden DOE Office of Science-brugerfacilitet på Brookhaven Lab.
Hos CFN har der været meget arbejde med AI/ML, der kan hjælpe med at drive eksperimenter gennem brug af automatisering, kontroller, robotteknologi og analyse, men at have et program, der var dygtig til videnskabelig tekst, var noget, forskerne ikke havde udforsket lige så dybt. At være i stand til hurtigt at dokumentere, forstå og formidle information om et eksperiment kan hjælpe på en række måder – lige fra at nedbryde sprogbarrierer til at spare tid ved at opsummere større stykker arbejde.
Hold øje med dit sprog
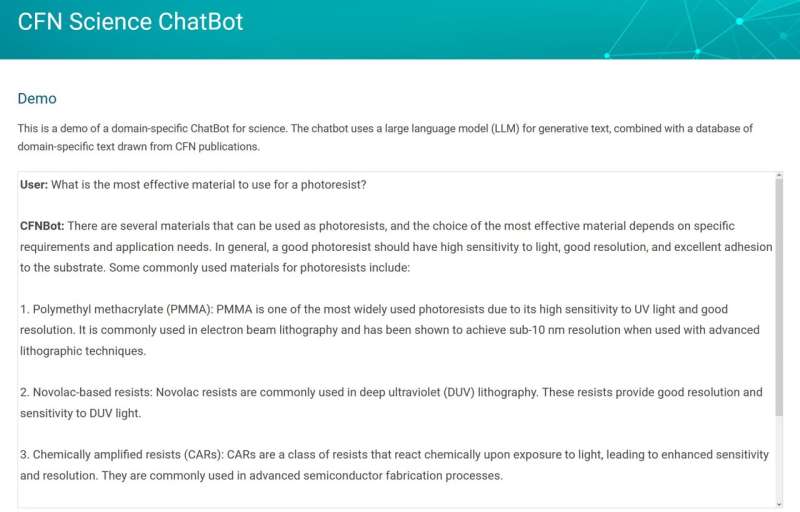
For at bygge en specialiseret chatbot krævede programmet domænespecifik tekst – sprog taget fra områder, som botten er beregnet til at fokusere på. I dette tilfælde er teksten videnskabelige publikationer. Domænespecifik tekst hjælper AI-modellen med at forstå ny terminologi og definitioner og introducerer den til grænseoverskridende videnskabelige begreber. Vigtigst er det, at dette kuraterede sæt dokumenter gør AI-modellen i stand til at basere sine ræsonnementer ved hjælp af pålidelige fakta.
For at efterligne naturligt menneskeligt sprog trænes AI-modeller på eksisterende tekst, hvilket gør dem i stand til at lære sprogets struktur, huske forskellige fakta og udvikle en primitiv form for ræsonnement. I stedet for møjsommeligt at genoptræne AI-modellen på nanovidenskabstekst, gav Yager den muligheden for at slå relevant information op i et udvalgt sæt publikationer. At forsyne den med et bibliotek med relevante data var kun halvdelen af kampen. For at bruge denne tekst nøjagtigt og effektivt, ville botten have brug for en måde at tyde den korrekte kontekst på.
"En udfordring, der er fælles med sprogmodeller, er, at de nogle gange 'hallucinerer' plausible, men usande ting," forklarede Yager. "Dette har været et kerneproblem at løse for en chatbot, der bruges i forskning i modsætning til en, der laver noget som at skrive poesi. Vi ønsker ikke, at det skal opdigte fakta eller citater. Dette skulle løses. Løsningen på dette var noget, vi kalder 'indlejring', en måde at kategorisere og sammenkæde information hurtigt bag kulisserne."
Indlejring er en proces, der omdanner ord og sætninger til numeriske værdier. Den resulterende "indlejringsvektor" kvantificerer betydningen af teksten. Når en bruger stiller chatbotten et spørgsmål, sendes det også til ML-indlejringsmodellen for at beregne dens vektorværdi. Denne vektor bruges til at søge gennem en forudberegnet database med tekststykker fra videnskabelige artikler, der på samme måde var indlejret. Botten bruger derefter tekstuddrag, den finder, som er semantisk relateret til spørgsmålet for at få en mere fuldstændig forståelse af konteksten.
Brugerens forespørgsel og tekstuddragene kombineres til en "prompt", der sendes til en stor sprogmodel, et ekspansivt program, der skaber tekst baseret på naturligt menneskeligt sprog, som genererer det endelige svar. Indlejringen sikrer, at den tekst, der trækkes, er relevant i forbindelse med brugerens spørgsmål. Ved at levere tekststykker fra hoveddelen af dokumenter, der er tillid til, genererer chatbotten svar, der er faktuelle og hentede.
"Programmet skal være som en referencebibliotekar," sagde Yager. "Den skal i høj grad stole på dokumenterne for at give kildesvar. Den skal være i stand til nøjagtigt at fortolke, hvad folk spørger og være i stand til effektivt at sammensætte konteksten af disse spørgsmål for at hente de mest relevante oplysninger. Selvom svarene måske ikke være perfekt endnu, den er allerede i stand til at besvare udfordrende spørgsmål og sætte gang i nogle interessante tanker, mens den planlægger nye projekter og forskning."
Botter, der styrker mennesker
CFN udvikler AI/ML-systemer som værktøjer, der kan befri menneskelige forskere til at arbejde med mere udfordrende og interessante problemer og til at få mere ud af deres begrænsede tid, mens computere automatiserer gentagne opgaver i baggrunden. Der er stadig mange ubekendte om denne nye måde at arbejde på, men disse spørgsmål er starten på vigtige diskussioner, som forskere har lige nu for at sikre, at AI/ML-brug er sikker og etisk.
"Der er en række opgaver, som en domænespecifik chatbot som denne kunne klare fra en videnskabsmands arbejdsbyrde. Klassificering og organisering af dokumenter, opsummering af publikationer, påpegning af relevant information og at få fart på et nyt aktuelt område er blot nogle få potentielle muligheder. ansøgninger," bemærkede Yager. "Jeg er dog spændt på at se, hvor alt dette vil gå hen. Vi kunne aldrig have forestillet os, hvor vi er nu for tre år siden, og jeg ser frem til, hvor vi vil være tre år fra nu."
For forskere, der er interesseret i at prøve denne software af selv, kan kildekoden til CFN's chatbot og tilhørende værktøjer findes i dette GitHub-lager.
Flere oplysninger: Kevin G. Yager, domænespecifikke chatbots til videnskab ved hjælp af indlejringer, Digital Discovery (2023). DOI:10.1039/D3DD00112A
Leveret af Brookhaven National Laboratory
Sidste artikelHøst mere solenergi med todimensionelle superkrystaller
Næste artikel3D-modeller til at placere nanopartikler i din håndflade
 Varme artikler
Varme artikler
-
 Papirsuperkondensator kan drive fremtidens papirelektronikFotos til venstre og i midten viser papirsuperkondensatoren trykt på Xerox-papir. Det højre billede viser papirsuperkondensatoren trykt på avispapir. Billedkredit:Liangbing Hu, et al. ©2010 AIP. (
Papirsuperkondensator kan drive fremtidens papirelektronikFotos til venstre og i midten viser papirsuperkondensatoren trykt på Xerox-papir. Det højre billede viser papirsuperkondensatoren trykt på avispapir. Billedkredit:Liangbing Hu, et al. ©2010 AIP. ( -
 Belastning af hukommelsen:Prototype stamme -konstruerede materialer er fremtiden for datalagringEn sammenligning af den elektriske koblingsstrøm og koblingstider for de anstrengte supergitteres grænsefladefaseskifthukommelse med andre state-of-the-art faseændringshukommelsesmaterialer. Kredit:Zh
Belastning af hukommelsen:Prototype stamme -konstruerede materialer er fremtiden for datalagringEn sammenligning af den elektriske koblingsstrøm og koblingstider for de anstrengte supergitteres grænsefladefaseskifthukommelse med andre state-of-the-art faseændringshukommelsesmaterialer. Kredit:Zh -
 Rynker og krøller gør grafen bedreRynker og krøller, introduceret ved at placere grafen på krympende polymerer, kan forbedre grafens egenskaber. Kredit:Hurt and Wong Labs / Brown Unviversity Krølle et stykke papir, og det er sands
Rynker og krøller gør grafen bedreRynker og krøller, introduceret ved at placere grafen på krympende polymerer, kan forbedre grafens egenskaber. Kredit:Hurt and Wong Labs / Brown Unviversity Krølle et stykke papir, og det er sands -
 Udnyttelse af sol- og vindenergi i én enhed kan drive tingenes internetKredit:American Chemical Society Tingenes Internet kunne gøre byer klogere ved at forbinde et omfattende netværk af små kommunikationsenheder for at gøre livet mere effektivt. Men alle disse maski
Udnyttelse af sol- og vindenergi i én enhed kan drive tingenes internetKredit:American Chemical Society Tingenes Internet kunne gøre byer klogere ved at forbinde et omfattende netværk af små kommunikationsenheder for at gøre livet mere effektivt. Men alle disse maski
- Flyt over, 'Laurel eller Yanny':Undersøgelse ser på, hvorfor vi hører tale som sang efter mange g…
- Stillehavets tyfoner kan blive intensiveret mere end tidligere forventet
- Kan New York Citys skyskrabere rumme vertikalt landbrug?
- Forskerhold begynder at designe et letfordærveligt fødevaresmart emballagesystem til transport
- Systemtilgang hjælper med at vurdere folkesundhedsvirkningerne af klimaændringer, miljøpolitik
- Menneskelig adfærd på operationsstuer er parallel med primater i hierarki og køn