


Kan computere forstå komplekse ord og begreber? Ja, ifølge forskning
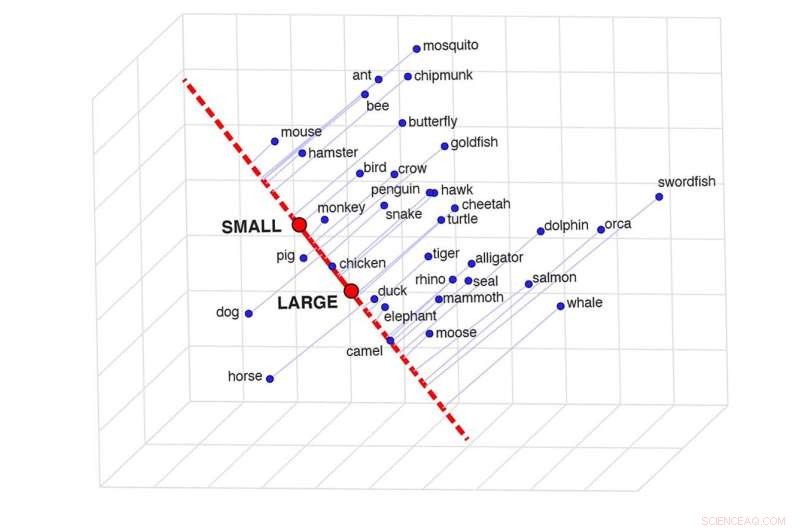
En skildring af semantisk projektion, som kan bestemme ligheden mellem to ord i en bestemt kontekst. Dette gitter viser, hvor ens visse dyr er baseret på deres størrelse. Kredit:Idan Blank/UCLA
I "Through the Looking Glass" siger Humpty Dumpty hånligt:"Når jeg bruger et ord, betyder det lige, hvad jeg vælger, at det skal betyde - hverken mere eller mindre." Alice svarer:"Spørgsmålet er, om du kan få ord til at betyde så mange forskellige ting."
Undersøgelsen af, hvad ord virkelig betyder, er år gammel. Det menneskelige sind skal analysere et net af detaljerede, fleksible oplysninger og bruge sofistikeret sund fornuft til at opfatte deres betydning.
Nu er et nyere problem relateret til ordenes betydning dukket op:Forskere studerer, om kunstig intelligens kan efterligne det menneskelige sind for at forstå ord, som folk gør. En ny undersøgelse foretaget af forskere ved UCLA, MIT og National Institutes of Health adresserer det spørgsmål.
Artiklen, offentliggjort i tidsskriftet Nature Human Behaviour , rapporterer, at kunstige intelligenssystemer faktisk kan lære meget komplicerede ordbetydninger, og forskerne opdagede et simpelt trick til at udtrække den komplekse viden. De fandt ud af, at det AI-system, de undersøgte, repræsenterer ordenes betydning på en måde, der er stærkt korreleret med menneskelig dømmekraft.
AI-systemet, som forfatterne undersøgte, er blevet brugt hyppigt i det sidste årti til at studere ords betydning. Den lærer at finde ud af ords betydninger ved at "læse" astronomiske mængder af indhold på internettet, der omfatter titusindvis af milliarder af ord.
Når ord ofte forekommer sammen - for eksempel "bord" og "stol" - lærer systemet, at deres betydninger hænger sammen. Og hvis ordpar forekommer sammen meget sjældent - som "tabel" og "planet" - lærer det, at de har meget forskellige betydninger.
Den tilgang virker som et logisk udgangspunkt, men tænk på, hvor godt mennesker ville forstå verden, hvis den eneste måde at forstå mening på var at tælle, hvor ofte ord forekommer i nærheden af hinanden, uden nogen som helst evne til at interagere med andre mennesker og vores miljø.
Idan Blank, en UCLA-assistentprofessor i psykologi og lingvistik, og studiets medlederforfatter, sagde, at forskerne satte sig for at lære, hvad systemet ved om de ord, det lærer, og hvilken slags "sund fornuft" det har.
Inden forskningen begyndte, sagde Blank, syntes systemet at have én væsentlig begrænsning:"For så vidt angår systemet, har hvert andet ord kun én numerisk værdi, der repræsenterer, hvor ens de er."
I modsætning hertil er menneskelig viden meget mere detaljeret og kompleks.
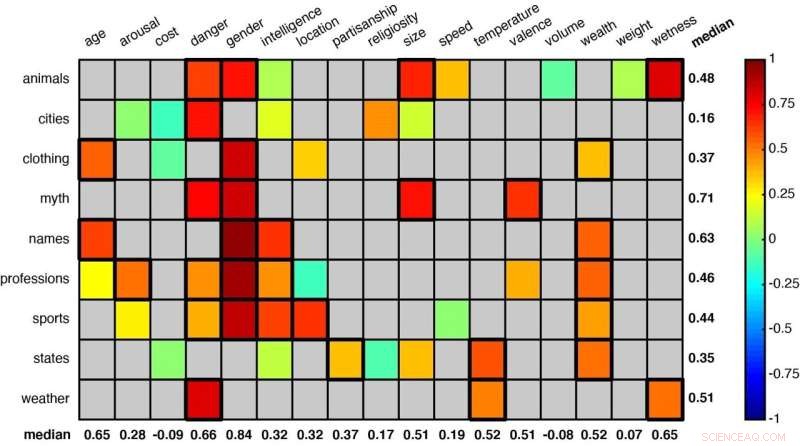
Et gitter, der viser nogle af de ordkategorier, som forskerne har analyseret. Statistisk signifikante parringer (som "dyr" og "fare" og "dyr" og "køn" i første række) er angivet med firkanter med en tykkere kant. Kredit:Idan Blank/UCLA
"Overvej vores viden om delfiner og alligatorer," sagde Blank. "Når vi sammenligner de to på en størrelsesskala, fra 'lille' til 'stor', er de relativt ens. Med hensyn til deres intelligens er de noget forskellige. Med hensyn til den fare, de udgør for os, på en skala fra 'sikker' til 'farlig', de adskiller sig meget. Så et ords betydning afhænger af konteksten.
"Vi ønskede at spørge, om dette system faktisk kender disse subtile forskelle - om dets idé om lighed er fleksibel på samme måde, som det er for mennesker."
For at finde ud af det udviklede forfatterne en teknik, de kalder "semantisk projektion." One can draw a line between the model's representations of the words "big" and "small," for example, and see where the representations of different animals fall on that line.
Using that method, the scientists studied 52 word groups to see whether the system could learn to sort meanings—like judging animals by either their size or how dangerous they are to humans, or classifying U.S. states by weather or by overall wealth.
Among the other word groupings were terms related to clothing, professions, sports, mythological creatures and first names. Each category was assigned multiple contexts or dimensions—size, danger, intelligence, age and speed, for example.
The researchers found that, across those many objects and contexts, their method proved very similar to human intuition. (To make that comparison, the researchers also asked cohorts of 25 people each to make similar assessments about each of the 52 word groups.)
Remarkably, the system learned to perceive that the names "Betty" and "George" are similar in terms of being relatively "old," but that they represented different genders. And that "weightlifting" and "fencing" are similar in that both typically take place indoors, but different in terms of how much intelligence they require.
"It is such a beautifully simple method and completely intuitive," Blank said. "The line between 'big' and 'small' is like a mental scale, and we put animals on that scale."
Blank said he actually didn't expect the technique to work but was delighted when it did.
"It turns out that this machine learning system is much smarter than we thought; it contains very complex forms of knowledge, and this knowledge is organized in a very intuitive structure," he said. "Just by keeping track of which words co-occur with one another in language, you can learn a lot about the world."
The study's co-authors are MIT cognitive neuroscientist Evelina Fedorenko, MIT graduate student Gabriel Grand, and Francisco Pereira, who leads the machine learning team at the National Institutes of Health's National Institute of Mental Health.
 Varme artikler
Varme artikler
-
 Flyvning efter den kolde krigVoyager-flyet blev brugt af Jeana Yeager og Dick Rutan i deres non-stop, jorden rundt flyvning. Se flere billeder af flyvningen. Peter M. Bowers samling Da det ottende årti af det tyvende århundrede
Flyvning efter den kolde krigVoyager-flyet blev brugt af Jeana Yeager og Dick Rutan i deres non-stop, jorden rundt flyvning. Se flere billeder af flyvningen. Peter M. Bowers samling Da det ottende årti af det tyvende århundrede -
 Sådan fungerer EVPEn forsker foretager lydoptagelser på Manteno State Mental Hospital. Foto med tilladelse til Southern Wisconsin Paranormal Research Group En januar nat i 2002, en gruppe paranormale efterforskere be
Sådan fungerer EVPEn forsker foretager lydoptagelser på Manteno State Mental Hospital. Foto med tilladelse til Southern Wisconsin Paranormal Research Group En januar nat i 2002, en gruppe paranormale efterforskere be -
 Tidsbombe i verden står over for konkurs:undersøgelseKredit:Unsplash/CC0 Public Domain Regeringer rundt om i verden kæmper for at redde virksomheder, der er ramt af coronavirus-lockdowns, men verden står ikke desto mindre over for en massiv stigning
Tidsbombe i verden står over for konkurs:undersøgelseKredit:Unsplash/CC0 Public Domain Regeringer rundt om i verden kæmper for at redde virksomheder, der er ramt af coronavirus-lockdowns, men verden står ikke desto mindre over for en massiv stigning -
 Venteområdeunderholdning og samarbejde mellem fysiske butikker øger profittenKredit:CC0 Public Domain Med populariteten af online shopping, det er ingen hemmelighed, at fysiske butikker kæmper for at forblive relevante. Underholdning i venteområdet er en måde, hvorpå de
Venteområdeunderholdning og samarbejde mellem fysiske butikker øger profittenKredit:CC0 Public Domain Med populariteten af online shopping, det er ingen hemmelighed, at fysiske butikker kæmper for at forblive relevante. Underholdning i venteområdet er en måde, hvorpå de
- En del af Stillehavet opvarmes ikke som forventet, købe hvorfor?
- Forskere udvikler en ny analog processor til højtydende computere
- Løsning af mysteriet om mørk energi:En ny opgave til et 45 år gammelt teleskop
- Fem nye gigantiske radiogalakser opdaget
- Kyllingeplast og vinlæder - giver affald nyt liv
- Hvordan man skelner mellem en mand og kvinde Sparrow