


Hvor nøjagtig er din AI?

Den nye AI-evalueringsmetode ser på selve inputdataene for at finde ud af, om 'nøjagtigheden' af AI kan stole på. Kredit:Kyoto University / JB Brown
Efterhånden som AI's rolle i samfundet udvides, J B Brown fra Graduate School of Medicine rapporterer om en ny evalueringsmetode for den type AI, der forudsiger ja/positive/sande eller nej/negative/falske svar.
Browns papir, udgivet i Molekylær informatik , dekonstruerer brugen af AI og analyserer arten af den statistik, der bruges til at rapportere et AI-programs evner. Den nye teknik genererer også en sandsynlighed for præstationsniveauet givet evalueringsdata, besvare spørgsmål som:Hvad er sandsynligheden for at opnå mere nøjagtighed end 90 %?
Rapporter om nye AI-applikationer vises i nyhederne næsten dagligt, herunder i samfundet og videnskaben, finansiere, lægemidler, medicin, og sikkerhed.
"Mens rapporterede statistikker virker imponerende, forskerhold og dem, der vurderer resultaterne, støder på to problemer, " forklarer Brown. "For det første, at forstå, om AI opnåede sine resultater ved et tilfælde, og for det andet, at fortolke anvendelighed ud fra de rapporterede præstationsstatistikker."
For eksempel, hvis et AI-program er bygget til at forudsige, om nogen vil vinde i lotteriet eller ej, det kan altid forudsige et tab. Programmet kan opnå '99% nøjagtighed', men fortolkning er nøglen til at bestemme nøjagtigheden af konklusionen om, at programmet er nøjagtigt.
Men heri ligger problemet:i typisk AI-udvikling, evalueringen kan kun stole på, hvis der er lige mange positive og negative resultater. Hvis dataene er forspændt mod en af værdierne, det nuværende evalueringssystem vil overdrive systemets evner.
Så for at løse dette problem, Brown udviklede en ny teknik, der evaluerer ydeevnen kun baseret på selve inputdataene.
"Det nye ved denne teknik er, at den ikke afhænger af nogen type AI-teknologi, såsom dyb læring, " Brown beskriver. "Det kan hjælpe med at udvikle nye evalueringsmetrikker ved at se på, hvordan en metrik spiller sammen med balancen i forudsagte data. Vi kan så se, om de resulterende målinger kan være partiske."
Brown håber, at denne analyse ikke kun vil øge bevidstheden om, hvordan vi tænker om AI i fremtiden, men også at det bidrager til udviklingen af mere robuste AI-platforme.
Ud over nøjagtighedsmetrikken, Brown testede seks andre målinger i både teoretiske og anvendte scenarier, fandt ud af, at ingen enkelt metrik var universelt overlegen. Han siger, at nøglen til at bygge nyttige AI-platforme er at anlægge et multimetrisk syn på evaluering.
"AI kan hjælpe os med at forstå mange fænomener i verden, men for at det skal give os retning, vi skal vide, hvordan vi stiller de rigtige spørgsmål. Vi skal passe på med ikke at fokusere for meget på et enkelt tal som et mål for en AI's pålidelighed."
Browns program er frit tilgængeligt for offentligheden, forskere, og udviklere.
 Varme artikler
Varme artikler
-
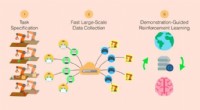 RoboTurk:En crowdsourcing -platform til efterligningslæring inden for robotikSystemoversigt over ROBOTURK. ROBOTURK muliggør hurtig imitation guidet færdighedsindlæring. Dette system består af følgende store trin:1) angivelse af en opgave, 2) indsamling af et stort sæt opgave
RoboTurk:En crowdsourcing -platform til efterligningslæring inden for robotikSystemoversigt over ROBOTURK. ROBOTURK muliggør hurtig imitation guidet færdighedsindlæring. Dette system består af følgende store trin:1) angivelse af en opgave, 2) indsamling af et stort sæt opgave -
 Bekæmpelse af drivhusgasserLektor Asegun Henry forsker i, hvordan man bruger varme metaller som smeltet tin til at lagre varme fra et koncentreret solenergisystem, så det kan bruges til at generere elektricitet efter behov. Kre
Bekæmpelse af drivhusgasserLektor Asegun Henry forsker i, hvordan man bruger varme metaller som smeltet tin til at lagre varme fra et koncentreret solenergisystem, så det kan bruges til at generere elektricitet efter behov. Kre -
 Facebooks Zuckerberg indrømmer fejl - men ingen undskyldning (Opdatering)administrerende direktør for Cambridge Analytica (CA) Alexander Nix, forlader kontorerne i det centrale London, tirsdag den 20 marts, 2018. Cambridge Analytica, er blevet anklaget for uretmæssig brug
Facebooks Zuckerberg indrømmer fejl - men ingen undskyldning (Opdatering)administrerende direktør for Cambridge Analytica (CA) Alexander Nix, forlader kontorerne i det centrale London, tirsdag den 20 marts, 2018. Cambridge Analytica, er blevet anklaget for uretmæssig brug -
 Energieffektiv effektelektronik:Galliumoxideffekttransistorer med rekordværdierGalliumoxidchip med transistorstrukturer og til måleformål, bearbejdet på FBH via projektionslitografi. Kredit:FBH/schurian.com Ferdinand-Braun-Institut (FBH) har opnået et gennembrud med transist
Energieffektiv effektelektronik:Galliumoxideffekttransistorer med rekordværdierGalliumoxidchip med transistorstrukturer og til måleformål, bearbejdet på FBH via projektionslitografi. Kredit:FBH/schurian.com Ferdinand-Braun-Institut (FBH) har opnået et gennembrud med transist
- Re-ordne enhver algebraisk ligning med en enkelt regel
- Byer vender sig til afsaltning for vandsikkerhed, men til hvilken pris?
- At øge offentlighedens tillid til videnskabsmænd afhænger af kommunikationsmetoder
- Studerer dværggalakser for at få det store overblik
- Negative effekter af fossilt brændstof
- Hvad afslører kemisk analyse om DNA?