


Lås op for løftet om omtrentlig computing til on-chip AI-acceleration
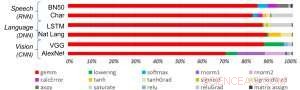
Figur 1. Deep learning algoritmer består af et spektrum af operationer. Selvom matrixmultiplikation er dominerende, optimering af ydeevneeffektiviteten og samtidig opretholdelse af nøjagtigheden kræver, at kernearkitekturen effektivt understøtter alle hjælpefunktionerne. Kredit:IBM
Nylige fremskridt inden for dyb læring og eksponentiel vækst i brugen af maskinlæring på tværs af applikationsdomæner har gjort AI-acceleration af afgørende betydning. IBM Research har bygget en pipeline af AI-hardwareacceleratorer for at imødekomme dette behov. På VLSI Circuits Symposium 2018, vi præsenterede en multi-TeraOPS-acceleratorkerne-byggesten, der kan skaleres på tværs af en bred vifte af AI-hardwaresystemer. Denne digitale AI -kerne har en parallel arkitektur, der sikrer meget høj udnyttelse og effektive computermotorer, der omhyggeligt udnytter reduceret præcision.
Tilnærmet computing er en central grundsætning i vores tilgang til at udnytte "fysikken i AI", hvor meget energieffektive computergevinster opnås ved specialbyggede arkitekturer, oprindeligt ved hjælp af digitale beregninger og senere inklusive analog og in-memory computing.
Historisk set, beregning har været afhængig af høj præcision 64- og 32-bit flydende komma aritmetik. Denne tilgang leverer nøjagtige beregninger til n'te decimalkomma, et niveau af nøjagtighed, der er afgørende for videnskabelige databehandlingsopgaver som at simulere det menneskelige hjerte eller beregne rumfærgens baner. Men har vi brug for dette nøjagtighedsniveau for almindelige dybe læringsopgaver? Kræver vores hjerne et billede i høj opløsning for at genkende et familiemedlem, eller en kat? Når vi indtaster en teksttråd til søgning, kræver vi præcision i den relative rangering af de 50, 002. mest nyttige svar vs 50, 003? Svaret er, at mange opgaver, herunder disse eksempler, kan udføres med omtrentlig databehandling.
Da fuldstændig præcision sjældent er påkrævet for almindelige dybe læringsarbejde, reduceret præcision er en naturlig retning. Beregningsbaserede byggeklodser med 16-bit præcisionsmotorer er 4x mindre end sammenlignelige blokke med 32-bit præcision; denne gevinst i områdeeffektivitet bliver et boost i ydeevne og strømeffektivitet for både AI-træning og udledning af arbejdsbelastninger. Enkelt sagt, i omtrentlig databehandling, vi kan handle numerisk præcision for beregningseffektivitet, forudsat at vi også udvikler algoritmiske forbedringer for at bevare modellens nøjagtighed. Denne tilgang supplerer også andre omtrentlige databehandlingsteknikker – inklusive nyere arbejde, der beskrev nye træningskompressionstilgange til at reducere kommunikationsoverhead, fører til 40-200x fremskyndelse i forhold til eksisterende metoder.
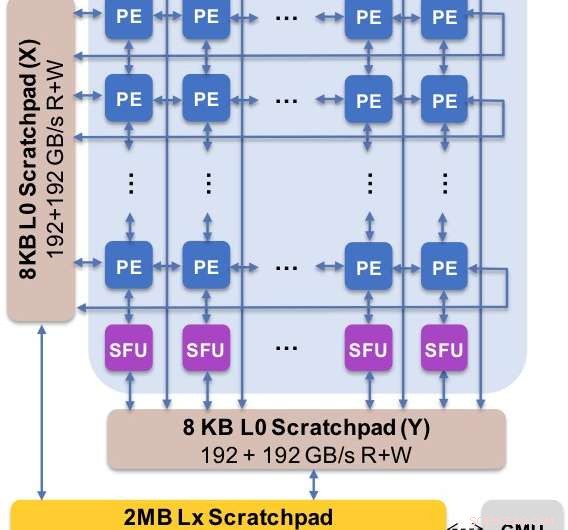
Figur 2. Kernearkitekturen fanger det tilpassede dataforløb med scratchpad -hierarki. Behandlingselementet (PE) udnytter reduceret præcision til matrixmultiplikationsoperationer og nogle aktiveringsfunktioner, hvorimod specialfunktionsenhederne (SFU) bevarer 32-bit flydende kommapræcision for de resterende vektoroperationer. Kredit:IBM
Vi præsenterede eksperimentelle resultater af vores digitale AI-kerne på 2018-symposiet om VLSI-kredsløb. Designet af vores nye kerne var styret af fire mål:
- End-to-end ydeevne:Parallel beregning, høj udnyttelse, høj databåndbredde
- Nøjagtighed af deep learning-modeller:Lige så nøjagtig som højpræcisionsimplementeringer
- Effekteffektivitet:Applikationskraft bør domineres af computerelementer
- Fleksibilitet og programmerbarhed:Tillad tuning af nuværende algoritmer samt udvikling af fremtidige deep learning algoritmer og modeller
Vores nye arkitektur er blevet optimeret til ikke kun matrixmultiplikation og foldningskerner, som har tendens til at dominere deep learning-beregninger, men også et spektrum af aktiveringsfunktioner, der er en del af deep learning-beregningsarbejdsbyrden. Desuden, vores arkitektur tilbyder understøttelse af native foldningsoperationer, tillader dyb læringstræning og inferensopgaver på billeder og taledata at køre med enestående effektivitet i kernen.
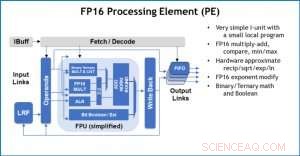
Figur 3. Behandlingselement (PE) med 16-bit flydende punkt (FP16) til matrixmultiplikationsoperationer, binær og ternær matematik, aktiveringsfunktioner og booleske operationer. Kredit:IBM
Som en illustration af, hvordan kernearkitekturen er blevet optimeret til en række deep learning-funktioner, Figur 1 viser opdelingen af operationstyper inden for deep learning-algoritmer på tværs af et spektrum af applikationsdomæner. De dominerende matrixmultiplikationskomponenter beregnes i kernearkitekturen ved at bruge en tilpasset datafloworganisation af behandlingselementerne vist i figur 2 og 3, hvor reducerede præcisionsberegninger effektivt kan udnyttes, hvorimod de resterende vektorfunktioner (alle de ikke-røde bjælker i figur 1) udføres i enten behandlingselementerne eller specialfunktionsenhederne vist i figur 3 eller 4, afhængig af præcisionsbehovet for den specifikke funktion.
Ved symposiet, vi viste hardwareresultater, der bekræfter, at denne tilgang med en enkelt arkitektur er i stand til både at træne og konkludere og understøtter modeller i flere domæner (f.eks. tale, vision, naturlig sprogbehandling). Mens andre grupper peger på "peak performance" af deres specialiserede AI-chips, men har vedvarende præstationsniveauer på en lille brøkdel af peak, vi har fokuseret på at maksimere vedvarende ydeevne og udnyttelse, da vedvarende ydeevne direkte omsættes til brugeroplevelse og svartider.
Vores testchip er vist i figur 5. Ved at bruge denne testchip, indbygget i 14LPP teknologi, vi har med succes demonstreret både træning og konklusioner, på tværs af et bredt dybt læringsbibliotek, udøver alle operationer, der almindeligvis anvendes i deep learning-opgaver, inklusive matrixmultiplikationer, foldninger og forskellige ikke-lineære aktiveringsfunktioner.
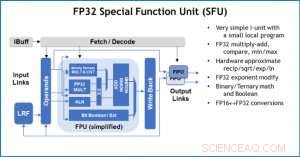
Figur 4. Special Function Unit (SFU) med 32-bit flydende komma (FP32) til visse vektorberegninger. Kredit:IBM
Vi fremhævede fleksibiliteten og multi-purpose kapaciteten i den digitale AI-kerne og native support til flere dataflow i VLSI-papiret, men denne tilgang er fuldt ud modulær. Denne AI -kerne kan integreres i SoC'er, CPU'er, eller mikrokontrollere og bruges til træning, slutning, eller begge. Chips, der bruger kernen, kan indsættes i datacenteret eller ved kanten.
Drevet af en grundlæggende forståelse af deep learning algoritmer hos IBM Research, vi forventer, at præcisionskravene til træning og inferens fortsætter med at skalere – hvilket vil drive kvanteeffektivitetsforbedringer i hardwarearkitekturer, der er nødvendige for AI. Stay tuned for more research from our team.
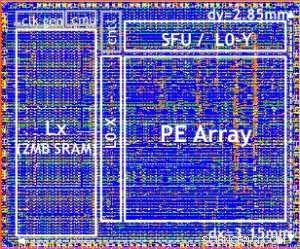
Figure 5. Digital AI Core testchip, based on 14LPP technology, including 5.75M gates, 1.00 flip-flops, 16KB L0 and 16KB of PE local registers. This chip was used to demonstrate both training and inferencing, across a wide range of AI workloads. Credit:IBM
 Varme artikler
Varme artikler
-
 Kommerciel flyrejse er sikrere end nogensinde før undersøgelse finderFlyveledere, der arbejder i Heathrow lufthavn i London. En ny undersøgelse af Arnold Barnett, George Eastman professor i ledelse ved MIT Sloan School of Management, konstaterer, at flyrejser har nået
Kommerciel flyrejse er sikrere end nogensinde før undersøgelse finderFlyveledere, der arbejder i Heathrow lufthavn i London. En ny undersøgelse af Arnold Barnett, George Eastman professor i ledelse ved MIT Sloan School of Management, konstaterer, at flyrejser har nået -
 En smart blød ortose for en stærkere rygErgoJack set fra siden. Kredit:Fraunhofer IPK Når arbejdere i Tyskland melder sig syge, rygsmerter er ofte skylden. Det rammer ofte medarbejdere inden for logistik, fremstilling og service, hvor f
En smart blød ortose for en stærkere rygErgoJack set fra siden. Kredit:Fraunhofer IPK Når arbejdere i Tyskland melder sig syge, rygsmerter er ofte skylden. Det rammer ofte medarbejdere inden for logistik, fremstilling og service, hvor f -
 Udtalelse:AI som HAL 9000 kan aldrig eksistere, fordi virkelige følelser ikke kan programmeresHAL 9000 er en af de mest kendte kunstige intelligensfigurer i moderne film. Denne overlegne form for følsom computer tager på mission til Jupiter, sammen med et menneskeligt besætning, i Stanley Ku
Udtalelse:AI som HAL 9000 kan aldrig eksistere, fordi virkelige følelser ikke kan programmeresHAL 9000 er en af de mest kendte kunstige intelligensfigurer i moderne film. Denne overlegne form for følsom computer tager på mission til Jupiter, sammen med et menneskeligt besætning, i Stanley Ku -
 Maskindetektering af menneske-objekt-interaktion i billeder og videoerJia-Bin Huang, assisterende professor i Bradley Department of Electrical and Computer Engineering og et fakultetsmedlem ved Discovery Analytics Center. Kredit:Virginia Tech Jia-Bin Huang, assister
Maskindetektering af menneske-objekt-interaktion i billeder og videoerJia-Bin Huang, assisterende professor i Bradley Department of Electrical and Computer Engineering og et fakultetsmedlem ved Discovery Analytics Center. Kredit:Virginia Tech Jia-Bin Huang, assister
- Canada kan bedre forberede sig på at omskole arbejdstagere, der er fordrevet af forstyrrende teknol…
- Et brændende kemisk anlæg kan være kun toppen af orkanen Lauras skader i dette område af olief…
- Materialer kan føre til selvhelbredende smartphones
- Ingeniører observerer laviner i nanopartikler for første gang
- En strukturel lyskontakt til magnetisme
- For at afsløre hemmelighederne bag exoplaneter, prøv at lytte til dem