


Semantisk konceptopdagelse over hændelsesdatabaser

Sammenligning af konceptrangeringer for en Human Rights Watch-rapport. Kolonnen 'Ground truth' viser de otte hyppigst nævnte personer i rapporten 'Venezuelas humanitære krise', mens de andre kolonner viser værdier returneret af forskellige opdagelsesmetoder. Værdier, der er blandt de grundlæggende sandhedsbegreber, er angivet med mørke felter. Kontekstmetoden returnerer værdier, der alle er relevante (selvom de mangler i den originale artikel), der henviser til, at metoden med samtidig forekomst returnerer mange populære, men irrelevante begreber (f.eks. politikere med generelle udtalelser om emnet). Kredit:IBM
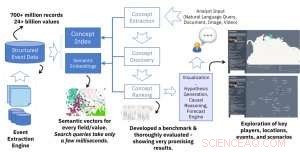
Hos IBM Research AI, vi byggede en AI-baseret løsning til at hjælpe analytikere med at udarbejde rapporter. Papiret, der beskriver dette værk, vandt for nylig prisen for bedste papir på "In-Use" Track of the 2018 Extended Semantic Web Conference (ESWC).
Analytikere har ofte til opgave at udarbejde omfattende og præcise rapporter om givne emner eller spørgsmål på højt niveau, som kan bruges af organisationer, virksomheder, eller offentlige myndigheder til at træffe informerede beslutninger, reducere risikoen forbundet med deres fremtidige planer. For at udarbejde sådanne rapporter, analytikere skal identificere emner, mennesker, organisationer, og begivenheder relateret til spørgsmålene. Som et eksempel, med henblik på at udarbejde en rapport om konsekvenserne af Brexit på Londons finansielle markeder, en analytiker skal være opmærksom på de vigtigste relaterede emner (f.eks. finansielle markeder, økonomi, Brexit, Brexit skilsmisselov), mennesker og organisationer (f.eks. Den Europæiske Union, beslutningstagere i EU og Storbritannien, personer involveret i Brexit-forhandlinger), og begivenheder (f.eks. Forhandlingsmøder, Parlamentsvalg i EU, etc.). En AI-assisteret løsning kan hjælpe analytikere med at udarbejde komplette rapporter og også undgå bias baseret på tidligere erfaringer. For eksempel, en analytiker kan gå glip af en vigtig informationskilde, hvis den ikke tidligere har været brugt effektivt.
Videninduktionsteamet hos IBM Research AI byggede løsningen ved hjælp af dyb læring og strukturerede begivenhedsdata. Holdet, ledet af Alfio Gliozzo, vandt også den prestigefyldte Semantic Web Challenge-pris sidste år.
Semantisk indlejring fra hændelsesdatabaser
Den centrale tekniske nyhed i dette arbejde er oprettelsen af semantiske embeddings ud af strukturerede hændelsesdata. Inputtet til vores semantiske indlejringsmotor er en stor struktureret datakilde (f.eks. databasetabeller med millioner af rækker), og outputtet er en stor samling af vektorer med en konstant størrelse (f.eks. 300), hvor hver vektor repræsenterer den semantiske kontekst af en værdi i de strukturerede data. Kerneideen ligner den populære og meget brugte idé om ordindlejringer i naturlig sprogbehandling, men i stedet for ord, vi repræsenterer værdier i de strukturerede data. Resultatet er en kraftfuld løsning, der muliggør hurtig og effektiv semantisk søgning på tværs af forskellige felter i databasen. En enkelt søgeforespørgsel tager kun et par millisekunder, men henter resultater baseret på mining af hundreder af millioner af poster og milliarder af værdier.
Mens vi eksperimenterede med forskellige neurale netværksmodeller til at bygge indlejringer, vi opnåede meget lovende resultater ved at bruge en simpel tilpasning af den originale skip-gram word2vec model. Dette er en effektiv lavvandet neural netværksmodel baseret på en arkitektur, der forudsiger konteksten (omgivende ord) givet et ord i et dokument. I vores arbejde, vi har ikke at gøre med tekstdokumenter, men med strukturerede databaseposter. For det, vi behøver ikke længere bruge et glidende vindue af en fast eller tilfældig størrelse for at fange konteksten. I strukturerede data, konteksten er defineret af alle værdierne i den samme række uanset kolonnepositionen, da to tilstødende kolonner i en database er lige så relaterede som alle andre to kolonner. Den anden forskel i vores indstillinger er behovet for at fange forskellige felter (eller kolonner) i databasen. Vores motor skal aktivere både generelle semantiske forespørgsler (dvs. returnere enhver databaseværdi relateret til den givne værdi) og feltspecifikke værdier (dvs. returnere værdier fra et givet felt relateret til inputværdien). For det, vi tildeler en type til vektorer bygget ud af hvert felt og bygger et indeks, der understøtter typespecifikke eller generiske forespørgsler.
Kredit:IBM
For det arbejde, der er beskrevet i vores papir, vi brugte tre offentligt tilgængelige hændelsesdatabaser som input:GDELT, ICEWS, og EventRegistry. Samlet set, disse databaser består af hundredvis af millioner poster (JSON-objekter eller databaserækker) og milliarder af værdier på tværs af forskellige felter (attributter). Ved at bruge vores indlejringsmotor, hver værdi bliver til en vektor, der repræsenterer konteksten i dataene.
En simpel hentningsforespørgsel
Man kan se, hvor godt konteksten fanges af vores motor ved hjælp af en simpel genfindingsforespørgsel. For eksempel, når du forespørger efter værdien "Hilary Clinton" (fejlstavet) i feltet "person" i GDLT GKG, det første hit eller mest lignende vektor er "Hilary Clinton" (fejlstavet) under felt "navn" og de næste mest lignende vektorer er "Hillary Clinton" (korrekt stavning) under felterne "person" og "navn". Dette skyldes den meget lignende kontekst af den fejlstavede værdi og den korrekte stavning, og også værdierne på tværs af felterne "navn" og "person". Resten af hits til ovenstående forespørgsel omfatter amerikanske politikere, især dem, der var aktive under det seneste præsidentvalg, samt relaterede organisationer, personer med lignende jobroller i fortiden, og familiemedlemmer.
Lighedssøgning på kombinerede forespørgsler
Selvfølgelig, vores løsning er i stand til at opnå meget mere end en simpel hentningsforespørgsel. I særdeleshed, man kan kombinere disse forespørgsler for at omdanne et sæt værdier udvundet fra en naturlig sprogforespørgsel til en vektor og udføre lighedssøgning. Vi evaluerede resultatet af denne tilgang ved hjælp af et benchmark bygget fra rapporter skrevet af menneskelige eksperter, og undersøgte vores motors evne til at returnere begreberne beskrevet i rapporterne ved at bruge rapportens titel som det eneste input. Resultaterne viste tydeligt overlegenheden af vores semantiske indlejringsbaserede konceptopdagelsestilgang sammenlignet med en basislinjetilgang, der kun er afhængig af værdiernes samtidige forekomst.
Nye applikationer i konceptopdagelse
Et meget interessant aspekt af vores ramme er, at enhver værdi og ethvert felt tildeles en vektor, der repræsenterer dens kontekst, som muliggør nye interessante applikationer. For eksempel, vi integrerede bredde- og længdegradskoordinater fra hændelser i databaserne i det samme semantiske rum af begreber, og arbejdede sammen med Visual AI Lab ledet af Mauro Martino for at bygge en visualiseringsramme, der fremhæver relaterede steder på et geografisk kort givet et spørgsmål i naturligt sprog. En anden interessant applikation, vi i øjeblikket undersøger, er at bruge de hentede koncepter og deres semantiske indlejringer som funktioner til en maskinlæringsmodel, som analytikeren skal bygge. Dette kan bruges i en automatiseret maskinlæring og datavidenskab (AutoML) motor, og støtte analytikere i et andet vigtigt aspekt af deres job. Vi planlægger at integrere denne løsning i IBM's Scenario Planning Advisor, et beslutningsstøttesystem for risikoanalytikere.
Denne historie er genudgivet med tilladelse fra IBM Research. Læs den originale historie her.
 Varme artikler
Varme artikler
-
 Tyskland, Frankrig presser på for at skabe europæisk industripolitikTysklands forbundskansler Angela Merkel ankommer til Digitalisering af Europa -topmødet 2019, hostet af Vodafone-virksomheden i Berlin, Tyskland, Tirsdag, 19. februar kl. 2019. (Foto/Markus Schreiber)
Tyskland, Frankrig presser på for at skabe europæisk industripolitikTysklands forbundskansler Angela Merkel ankommer til Digitalisering af Europa -topmødet 2019, hostet af Vodafone-virksomheden i Berlin, Tyskland, Tirsdag, 19. februar kl. 2019. (Foto/Markus Schreiber) -
 WhatsApp forsvarer kryptering, da det topper 2 milliarder brugereWhatsApp-mobilmeddelelsestjenesten ejet af Facebook sagde, at den har mere end to milliarder brugere, da den bekræftede sin forpligtelse til stærk kryptering Den Facebook-ejede beskedtjeneste What
WhatsApp forsvarer kryptering, da det topper 2 milliarder brugereWhatsApp-mobilmeddelelsestjenesten ejet af Facebook sagde, at den har mere end to milliarder brugere, da den bekræftede sin forpligtelse til stærk kryptering Den Facebook-ejede beskedtjeneste What -
 Facebook udruller globalt værktøj til at rydde tredjepartsdataFacebooks administrerende direktør Mark Zuckerberg siger, at verdens største sociale netværk udruller et nyt værktøj, der giver brugerne mulighed for at se og slette tredjepartsdata, det indsamler
Facebook udruller globalt værktøj til at rydde tredjepartsdataFacebooks administrerende direktør Mark Zuckerberg siger, at verdens største sociale netværk udruller et nyt værktøj, der giver brugerne mulighed for at se og slette tredjepartsdata, det indsamler -
 Nyt design til hoppende og vingeflapende mikrorobotterFrugtfluebotens vinge. Kredit:Bhushan &Tomlin. Forskere ved University of California (UC) Berkeley har for nylig designet to mikrobotter i insektskala, en der hopper og en anden der slår med sine
Nyt design til hoppende og vingeflapende mikrorobotterFrugtfluebotens vinge. Kredit:Bhushan &Tomlin. Forskere ved University of California (UC) Berkeley har for nylig designet to mikrobotter i insektskala, en der hopper og en anden der slår med sine
- Amazon står over for en ny rolle i viruskrise:livline
- Syntetisk antibiotikum, der kan tilpasses, udmanøvrerer resistente bakterier
- Udvidede emissionsfilamenter fundet i galaksen Markarian 6
- Hvordan udvindes granit?
- Når klimaet opvarmes, mus morf
- Hvor lang er en dag på Venus? Forskere knækker mysterier om vores nærmeste nabo