


Deep learning strækker sig op til videnskabelige supercomputere

Forskere leverede en 15-petaflop dyb-læringssoftware og kørte den på Cori, en supercomputer ved National Energy Research Scientific Computing Center, en Department of Energy Office of Science brugerfacilitet. Kredit:Lawrence Berkeley National Laboratory
Maskinelæring, en form for kunstig intelligens, nyder hidtil uset succes i kommercielle applikationer. Imidlertid, brugen af maskinlæring i højtydende computing til videnskab har været begrænset. Hvorfor? Avancerede maskinlæringsværktøjer var ikke designet til store datasæt, som dem der bruges til at studere stjerner og planeter. Et team fra Intel, National Energy Research Scientific Computing Center (NERSC), og Stanford ændrede den situation. De udviklede den første 15-petaflop deep-learning software. De demonstrerede sin evne til at håndtere store datasæt via testkørsler på Cori-supercomputeren.
Brug af maskinlæringsteknikker på supercomputere, forskere kunne udtrække indsigt fra store, komplekse datasæt. Kraftige instrumenter, såsom acceleratorer, producere massive datasæt. Den nye software kan gøre verdens største supercomputere i stand til at passe sådanne data ind i deep learning-anvendelser. Den resulterende indsigt kan være til gavn for modellering af jordsystemer, fusionsenergi, og astrofysik.
Maskinlæringsteknikker rummer potentiale til at gøre det muligt for forskere at udvinde værdifuld indsigt fra store, komplekse datasæt, der produceres af acceleratorer, lyskilder, teleskoper, og computersimuleringer. Selvom disse teknikker har haft stor succes i en række kommercielle anvendelser, deres brug i højtydende databehandling til videnskab har været begrænset, fordi eksisterende værktøjer ikke var designet til at arbejde med de terabyte- til petabyte-størrelse datasæt, der findes i mange videnskabsdomæner.
For at løse dette problem et samarbejde mellem Intel, National Energy Research Scientific Computing Center, og Stanford University har arbejdet på at løse problemer, der opstår ved brug af deep learning-teknikker, en form for maskinlæring, på terabyte og petabyte datasæt. Holdet udviklede den første 15-petaflop deep-learning software. De demonstrerede dets skalerbarhed til dataintensive applikationer ved at udføre en række træningskørsler ved hjælp af store videnskabelige datasæt. Kørslerne brugte fysik- og klimabaserede datasæt på Cori, en supercomputer placeret på National Energy Research Scientific Computing Center. De opnåede en peak rate mellem 11,73 og 15,07 petaflops (enkelt præcision) og en gennemsnitlig vedvarende ydeevne på 11,41 til 13,47 petaflops. (En petaflop er millioner milliarder beregninger i sekundet.)
 Varme artikler
Varme artikler
-
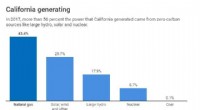 Californien sigter mod at blive kulstoffri i 2045 – er det muligt?Diagram:Samtalen, CC-BY-ND Kilde:California Energy Commission Californiens guvernør Jerry Brown har underskrevet en ny lov, der påbyder, at den elektricitet, staten forbruger, ikke forårsager kuls
Californien sigter mod at blive kulstoffri i 2045 – er det muligt?Diagram:Samtalen, CC-BY-ND Kilde:California Energy Commission Californiens guvernør Jerry Brown har underskrevet en ny lov, der påbyder, at den elektricitet, staten forbruger, ikke forårsager kuls -
 Storbritanniens telegigant BT -akser 13, 000 jobBT kaster 13, 000 job i løbet af de næste tre år, da det søger at skære yderligere 1,5 milliarder pund i omkostninger Britisk telekommunikations- og tv -selskab BT meddelte torsdag, at det vil øge
Storbritanniens telegigant BT -akser 13, 000 jobBT kaster 13, 000 job i løbet af de næste tre år, da det søger at skære yderligere 1,5 milliarder pund i omkostninger Britisk telekommunikations- og tv -selskab BT meddelte torsdag, at det vil øge -
 Klistermærket er klæbende tracker i Tile lineupHvor er fjernbetjeningen! Jeg leder bare efter kameraet. Fandt du vores ... du udfylder emnerne. På tidspunktet for denne skrivning, nogen et sted løber rundt og forsøger at finde noget. Mange me
Klistermærket er klæbende tracker i Tile lineupHvor er fjernbetjeningen! Jeg leder bare efter kameraet. Fandt du vores ... du udfylder emnerne. På tidspunktet for denne skrivning, nogen et sted løber rundt og forsøger at finde noget. Mange me -
 Amazon tilføjer Starbucks-direktør Rosalind Brewer til bordI denne 22. august, 2013, Foto, Sams Club President og CEO Rosalind Brewer stiller et spørgsmål under en paneldebat på Wal-Mart US Manufacturing Summit i Orlando, Fla. Amazon siger, at det har navngiv
Amazon tilføjer Starbucks-direktør Rosalind Brewer til bordI denne 22. august, 2013, Foto, Sams Club President og CEO Rosalind Brewer stiller et spørgsmål under en paneldebat på Wal-Mart US Manufacturing Summit i Orlando, Fla. Amazon siger, at det har navngiv
- Fordele og ulemper ved dyreforsøg
- Formskiftende protoceller antyder mekanikken i det tidlige liv
- Astronomer skaber 40 % mere kulstofemissioner end den gennemsnitlige australier. Sådan kan de forbe…
- Sådan oprettes Excel Beregning af grafer Hældning
- Sådan måles kvadratcentimeter
- Polyethylenproduktionsproces med høj densitet