


Model baner vej for hurtigere, mere effektive oversættelser af flere sprog
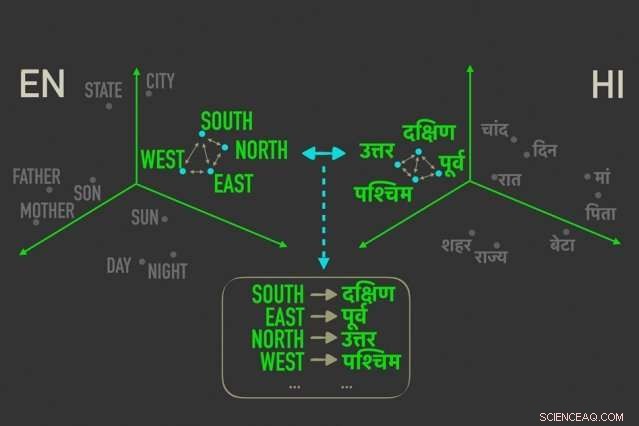
Den nye model måler afstande mellem ord med lignende betydning i "ordindlejringer, ”Og justerer derefter ordene i begge indlejringer, der er tættest korreleret af relative afstande, hvilket betyder, at de sandsynligvis er direkte oversættelser af hinanden. Kredit:Massachusetts Institute of Technology
MIT -forskere har udviklet en ny "uovervåget" sprogoversættelsesmodel - hvilket betyder, at den kører uden behov for menneskelige kommentarer og vejledning - der kan føre til hurtigere, mere effektive computerbaserede oversættelser af langt flere sprog.
Oversættelsessystemer fra Google, Facebook, og Amazon kræver, at træningsmodeller leder efter mønstre i millioner af dokumenter - såsom juridiske og politiske dokumenter, eller nyhedsartikler - der er blevet oversat til forskellige sprog af mennesker. Givet nye ord på ét sprog, de kan derefter finde de matchende ord og sætninger på det andet sprog.
Men disse translationelle data er tidskrævende og vanskelige at indsamle, og eksisterer ganske enkelt ikke for mange af de 7, 000 sprog, der tales på verdensplan. For nylig, forskere har udviklet "ensprogede" modeller, der laver oversættelser mellem tekster på to sprog, men uden direkte translationel information mellem de to.
I et papir, der i denne uge blev præsenteret på Conference on Empirical Methods in Natural Language Processing, forskere fra MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL) beskriver en model, der kører hurtigere og mere effektivt end disse ensprogede modeller.
Modellen udnytter en metrik i statistik, kaldet Gromov-Wasserstein afstand, der i det væsentlige måler afstande mellem punkter i et beregningsrum og matcher dem med lignende distancerede punkter i et andet rum. De anvender denne teknik til "ordindlejringer" på to sprog, som er ord repræsenteret som vektorer - grundlæggende rækker af tal - med ord med lignende betydning samlet tættere på hinanden. Derved, modellen justerer hurtigt ordene, eller vektorer, i begge indlejringer, der er tættest korreleret af relative afstande, hvilket betyder, at de sandsynligvis vil være direkte oversættelser.
I forsøg, forskernes model udført lige så præcist som state-of-the-art ensprogede modeller-og nogle gange mere præcist-men meget hurtigere og kun ved hjælp af en brøkdel af beregningskraften.
"Modellen ser ordene på de to sprog som sæt af vektorer, og kortlægger [disse vektorer] fra det ene sæt til det andet ved i det væsentlige at bevare relationer, "siger papirets medforfatter Tommi Jaakkola, en CSAIL -forsker og Thomas Siebel -professoren i Institut for Elektroteknik og Datalogi og Institut for Data, Systemer, og samfund. "Fremgangsmåden kunne hjælpe med at oversætte sprog med lav ressource eller dialekter, så længe de kommer med nok et sprogligt indhold. "
Modellen repræsenterer et skridt mod et af hovedmålene med maskinoversættelse, som er helt uden opsyn ordjustering, siger første forfatter David Alvarez-Melis, en CSAIL Ph.D. elev:"Hvis du ikke har data, der matcher to sprog ... kan du kortlægge to sprog og, ved hjælp af disse afstandsmålinger, juster dem. "
Forhold betyder mest
Tilpasning af ordindlejringer til maskinoversættelse uden opsyn er ikke et nyt koncept. Nyere arbejde træner neurale netværk til at matche vektorer direkte i ordindlejringer, eller matricer, fra to sprog sammen. Men disse metoder kræver en masse justeringer under træning for at få justeringerne helt rigtige, hvilket er ineffektivt og tidskrævende.
Måling og matchning af vektorer baseret på relationelle afstande, på den anden side, er en langt mere effektiv metode, der ikke kræver meget finjustering. Uanset hvor ordvektorer falder i en given matrix, forholdet mellem ordene, betyder deres afstande, vil forblive den samme. For eksempel, vektoren for "far" kan falde i helt forskellige områder i to matricer. Men vektorer for "far" og "mor" vil sandsynligvis altid være tæt sammen.
"Disse afstande er uforanderlige, "Alvarez-Melis siger." Ved at se på afstand, og ikke vektors absolutte position, så kan du springe justeringen over og gå direkte til at matche korrespondancerne mellem vektorer. "
Det er her, Gromov-Wasserstein kommer godt med. Teknikken er blevet brugt inden for datalogi til, sige, hjælper med at justere billedpixel i grafisk design. Men metriket virkede "skræddersyet" til ordjustering, Alvarez-Melis siger:"Hvis der er point, eller ord, der er tæt sammen i ét rum, Gromov-Wasserstein vil automatisk forsøge at finde den tilsvarende klynge af punkter i det andet rum. "
Til træning og test, forskerne brugte et datasæt med offentligt tilgængelige ordindlejringer, kaldet FASTTEXT, med 110 sprogpar. I disse indlejringer, og andre, ord, der forekommer oftere og oftere i lignende sammenhænge, har tæt matchende vektorer. "Mor" og "far" vil normalt være tæt sammen, men begge længere væk fra, sige, "hus."
Giver en "blød oversættelse"
Modellen noterer vektorer, der er nært beslægtede, men dog forskellige fra de andre, og tildeler en sandsynlighed for, at lignende distancerede vektorer i den anden indlejring vil svare. Det er lidt som en "blød oversættelse, "Alvarez-Melis siger, "fordi i stedet for bare at returnere en oversættelse af et enkelt ord, den fortæller dig 'denne vektor, eller ord, har en stærk korrespondance med dette ord, eller ord, på det andet sprog. '"
Et eksempel ville være i årets måneder, der optræder tæt sammen på mange sprog. Modellen vil se en klynge af 12 vektorer, der er samlet i en indlejring og en bemærkelsesværdigt lignende klynge i den anden indlejring. "Modellen ved ikke, at det er måneder, "Alvarez-Melis siger." Det ved bare, at der er en klynge på 12 punkter, der stemmer overens med en klynge på 12 punkter på det andet sprog, men de er forskellige fra resten af ordene, så de går nok godt sammen. Ved at finde disse korrespondancer for hvert ord, det justerer derefter hele rummet samtidigt. "
Forskerne håber, at arbejdet fungerer som en "gennemførlighedstjek, "Jaakkola siger, at anvende Gromov-Wasserstein-metoden til maskinoversættelsessystemer for at køre hurtigere, mere effektivt, og få adgang til mange flere sprog.
Derudover en mulig fordel ved modellen er, at den automatisk producerer en værdi, der kan tolkes som kvantificerende, på en numerisk skala, ligheden mellem sprog. Dette kan være nyttigt til lingvistiske undersøgelser, siger forskerne. Modellen beregner, hvor langt alle vektorer er fra hinanden i to indlejringer, som afhænger af sætningsstruktur og andre faktorer. Hvis vektorer alle er virkelig tætte, de scorer tættere på 0, og jo længere fra hinanden de er, jo højere score. Lignende romanske sprog som fransk og italiensk, for eksempel, score tæt på 1, mens klassisk kinesisk scorer mellem 6 og 9 med andre større sprog.
"Dette giver dig en dejlig, simpelt tal for, hvordan lignende sprog er ... og kan bruges til at drage indsigt i forholdene mellem sprog, "Siger Alvarez-Melis.
Denne historie er genudgivet med tilladelse fra MIT News (web.mit.edu/newsoffice/), et populært websted, der dækker nyheder om MIT -forskning, innovation og undervisning.
Sidste artikelFormskiftende modulær robot er mere end summen af dens dele
Næste artikelMaskiner, der lærer sprog mere som børn gør
 Varme artikler
Varme artikler
-
 Facebook, Google står over for et voksende undertrykkelse af onlineindholdI denne 18. april, 2017 filbillede, konferencemedarbejdere taler foran en demostand ved Facebooks årlige F8-udviklerkonference, i San Jose, Californien, Storbritannien for første gang mandag den 8. ap
Facebook, Google står over for et voksende undertrykkelse af onlineindholdI denne 18. april, 2017 filbillede, konferencemedarbejdere taler foran en demostand ved Facebooks årlige F8-udviklerkonference, i San Jose, Californien, Storbritannien for første gang mandag den 8. ap -
 At finde mennesker i video baseret på højde, klud farve, kønForeslået tilgang til personhentning ved hjælp af højde, klud farve og køn. Kredit:arXiv:1810.05080 [cs.CV] https://arxiv.org/abs/1810.05080 En særlig søgemetode lader dig finde mennesker i overvå
At finde mennesker i video baseret på højde, klud farve, kønForeslået tilgang til personhentning ved hjælp af højde, klud farve og køn. Kredit:arXiv:1810.05080 [cs.CV] https://arxiv.org/abs/1810.05080 En særlig søgemetode lader dig finde mennesker i overvå -
 Nissans nr. 3 stopper i et slag for genoplivningsbestræbelserNissan har skåret ned på sin helårsprognose for både salg og overskud, da den kæmper med svag efterspørgsel i Japan, USA og Europa Den øverste leder med ansvar for planerne om at genoplive krisera
Nissans nr. 3 stopper i et slag for genoplivningsbestræbelserNissan har skåret ned på sin helårsprognose for både salg og overskud, da den kæmper med svag efterspørgsel i Japan, USA og Europa Den øverste leder med ansvar for planerne om at genoplive krisera -
 Emoji bliver mere inkluderende, men ikke nødvendigvis mere repræsentativDen menneskelige race er langt mere mangfoldig, end emoji i øjeblikket repræsenterer. Kredit:Aratehortua/Shutterstock Mindst 230 nye emoji, når forskellige hudtoner og køn er inkluderet, forventes
Emoji bliver mere inkluderende, men ikke nødvendigvis mere repræsentativDen menneskelige race er langt mere mangfoldig, end emoji i øjeblikket repræsenterer. Kredit:Aratehortua/Shutterstock Mindst 230 nye emoji, når forskellige hudtoner og køn er inkluderet, forventes
- Hvad er forskellen mellem solstråler og solvind?
- Forskere udforsker RAMBleed-angreb i tyveri af data
- Hvad er stadierne af Cytokinesis?
- Sådan placeres en terningroot i en grafregner
- Nyt mineralsk klassifikationssystem fanger Jordens komplekse fortid
- Blivende mødre frygter for deres ufødte i smogkvalt Delhi