


En ny tilgang til at overvinde multi-model glemme i dybe neurale netværk
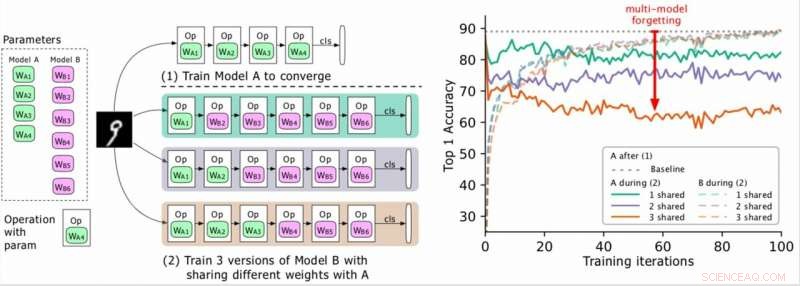
(Venstre) To modeller, der skal trænes (A, B), hvor A’s parametre er grønne og B’er i lilla, og B deler nogle parametre med A (angivet med grønt under fase 2). Forskerne træner først A til konvergens og derefter træner B. (Højre) Nøjagtighed af model A, efterhånden som træningen af B skrider frem. De forskellige farver svarer til forskellige antal delte lag. Nøjagtigheden af A falder dramatisk, især når flere lag deles, og forskerne omtaler dråben (den røde pil) som multi-model glemmer. Kredit:Benyahia, Yu et al.
I de seneste år, forskere har udviklet dybe neurale netværk, der kan udføre en række opgaver, herunder visuel genkendelse og naturlig sprogbehandling (NLP) opgaver. Selvom mange af disse modeller opnåede bemærkelsesværdige resultater, de klarer sig typisk kun godt på en bestemt opgave på grund af det, der kaldes "katastrofal glemme".
I det væsentlige, katastrofal glemme betyder, at når en model, der oprindeligt blev trænet i opgave A, senere blev uddannet i opgave B, dens ydeevne på opgave A vil falde markant. I et forudgivet papir om arXiv, forskere ved Swisscom og EPFL identificerede en ny form for glemme og foreslog en ny tilgang, der kunne hjælpe med at overvinde det via et statistisk begrundet vægttab af plasticitet.
"Da vi først begyndte at arbejde på vores projekt, at designe neurale arkitekturer automatisk var beregningsmæssigt dyrt og umuligt for de fleste virksomheder, "Yassine Benyahia og Kaicheng Yu, undersøgelsens primære efterforskere, fortalte TechXplore via e-mail. "Det oprindelige formål med vores undersøgelse var at identificere nye metoder til at reducere denne udgift. Da projektet startede, et papir fra Google hævdede at have drastisk reduceret den tid og de ressourcer, der kræves til at bygge neurale arkitekturer ved hjælp af en ny metode kaldet vægtdeling. Dette gjorde autoML muligt for forskere uden enorme GPU -klynger, tilskynde os til at studere dette emne mere i dybden. "
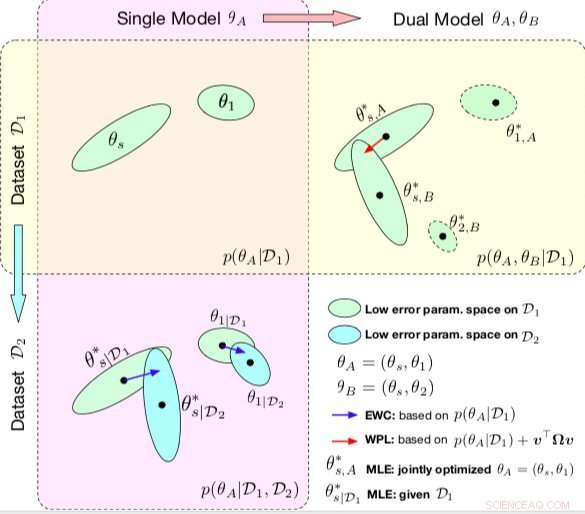
Sammenligning mellem EWC og WPL. Ellipserne i hver delplot repræsenterer parameterområder, der svarer til lav fejl. (Øverst til venstre) Begge metoder starter med en enkelt model, med parametre θA ={θs, θ1}, uddannet på et enkelt datasæt D1. (Nederst til venstre) EWC regulerer alle parametre baseret på p (θA | D1) for at træne den samme indledende model på et nyt datasæt D2. (Øverst til højre) Derimod, WPL gør brug af det indledende datasæt D1 og regulerer kun de delte parametre θs baseret på både p (θA | D1) og v> Ωv, mens parametrene θ2 kan bevæge sig frit. Kredit:Benyahia, Yu et al.
Under deres forskning i neurale netværksbaserede modeller, Benyahia, Yu og deres kolleger bemærkede et problem med vægtdeling. Når de trænede to modeller (f.eks. A og B) i rækkefølge, model A's ydelse faldt, mens model Bs ydeevne steg, eller omvendt. De viste, at dette fænomen, som de kaldte "multi-model forgetting, "kan hindre udførelsen af flere auto-ml-tilgange, herunder Googles effektive neurale arkitektursøgning (ENAS).
"Vi indså, at vægtdeling fik modeller til at påvirke hinanden negativt, hvilket fik arkitektursøgeprocessen til at være tættere på tilfældige, "Forklarer Benyahia og Yu." Vi havde også vores reserver til arkitektursøgning, hvor kun de endelige resultater belyses, og hvor der ikke er gode rammer til at evaluere kvaliteten af arkitektursøgningen på en fair måde. Vores tilgang kunne hjælpe med at løse dette glemte problem, da det er relateret til en kernemetode, som næsten alle nylige autoML -papirer er afhængige af, og vi betragter denne indflydelse som enorm for samfundet. "
I deres undersøgelse, forskerne modellerede multi-model, der glemte matematisk og afled et nyt tab, kaldes vægttab. Dette tab kan reducere multi-model glemmer væsentligt ved at regulere indlæringen af en model fælles parametre i henhold til deres betydning for tidligere modeller.
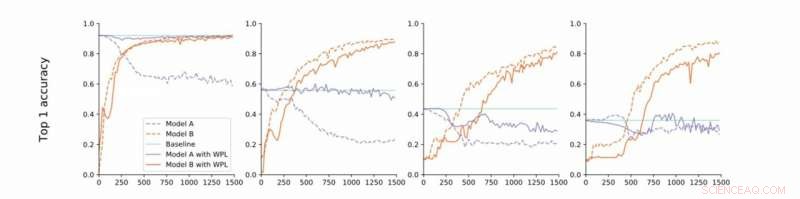
Fra streng til løs konvergens. Forskerne udfører eksperimenter på MNIST med modeller A og B med delte parametre og rapporterer nøjagtigheden af Model A før træning af Model B (baseline, grøn) og nøjagtigheden af model A og B, mens du træner Model B med (orange) eller uden (blå) WPL. I (a) viser de resultaterne for streng konvergens:A er oprindeligt uddannet til konvergens. De slækker derefter denne antagelse og træner A til omkring 55% (b), 43% (c), og 38% (d) af dens optimale nøjagtighed. WPL er yderst effektiv, når A er uddannet til mindst 40% af optimaliteten; under, Fisher -oplysningerne bliver for unøjagtige til at give pålidelige vægtvægte. Således hjælper WPL med at reducere multi-model glemmer, også når vægten ikke er optimal. WPL reducerede glemmer med op til 99,99% for (a) og (b), og med op til 2% for (c). Kredit:Benyahia, Yu et al.
"I bund og grund, på grund af overparameterisering af neurale netværk, vores tab reducerer parametre, der er 'mindre vigtige' for det endelige tab først, og holder de vigtigere uændrede, "Benyahia og Yu sagde." Model A's ydeevne er således upåvirket, mens model B's ydelse bliver ved med at stige. På små datasæt, vores model kan reducere glemme op til 99 procent, og på autoML -metoder, op til 80 procent midt i træningen. "
I en række tests, forskerne demonstrerede effektiviteten af deres tilgang til at reducere multi-model glemme, både i tilfælde, hvor to modeller trænes i rækkefølge og til neurale arkitektursøgninger. Deres fund tyder på, at tilføjelse af vægt plasticitet i neurale arkitektursøgninger kan forbedre ydeevnen for flere modeller betydeligt på både NLP og computer vision opgaver.
Undersøgelsen udført af Benyahia, Yu og deres kolleger kaster lys over spørgsmålet om katastrofal glemsel, især det, der opstår, når flere modeller trænes i rækkefølge. Efter at have modelleret dette problem matematisk, forskerne introducerede en løsning, der kunne overvinde den, eller i det mindste drastisk reducere dens indvirkning.
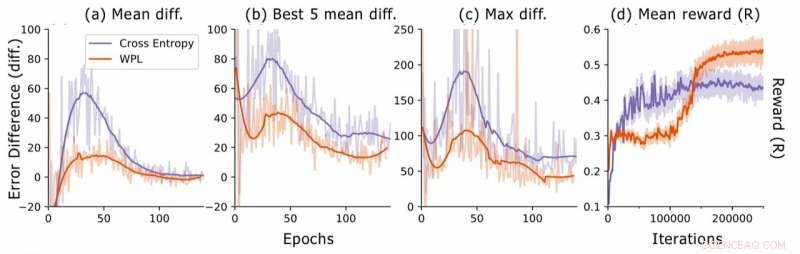
Fejlforskel under neural arkitektur søgning. For hver arkitektur, forskerne beregner RNN -fejlforskellene err2 − err1, hvor err1 er fejlen lige efter træning af denne arkitektur og err2 den ene trods alt trænes arkitekturer i den aktuelle epoke. De plotter (a) den gennemsnitlige forskel i forhold til alle modeller i stikprøven, (b) den gennemsnitlige forskel i forhold til de 5 modeller med laveste fejl1, og (c) den maksimale forskel i forhold til alle modeller. I (d), de tegner den gennemsnitlige belønning for de stikprøver, der er udtaget, som en funktion af træning af iterationer. Selvom WPL i første omgang fører til lavere belønninger, på grund af en stor vægt α i ligning (8), ved at reducere den glemmer det senere tillader controlleren at prøve bedre arkitekturer, som angivet af den højere belønning i anden halvleg. Kredit:Benyahia, Yu et al.
"Ved at glemme flere modeller, vores vejledende princip var at tænke i formler og ikke kun ved simpel intuition eller heuristik, "Benyahia og Yu sagde." Vi tror stærkt på, at denne 'tænkning i formler' kan føre forskere til store opdagelser. Det er derfor, for yderligere forskning, vi sigter mod at anvende denne tilgang på andre områder inden for maskinlæring. Ud over, Vi planlægger at tilpasse vores tab til de nyeste state-of-the-art autoML-metoder for at demonstrere dets effektivitet i løsningen af det vægtdelingsproblem, vi observerede. "
© 2019 Science X Network
Sidste artikelEt robotben, født uden forudgående viden, lærer at gå
Næste artikelRobo-journalistik vinder indpas i skiftende medielandskab
 Varme artikler
Varme artikler
-
 Journalister, der efterforsker Rusland målrettet af cyberangreb:ProtonMailEfterforskningswebstedet Bellingcat hjalp med at afsløre de russiske agenter, der er mistænkt for at have forgiftet eks-spionen Sergei Skripal Journalister, der efterforsker russisk militær efterr
Journalister, der efterforsker Rusland målrettet af cyberangreb:ProtonMailEfterforskningswebstedet Bellingcat hjalp med at afsløre de russiske agenter, der er mistænkt for at have forgiftet eks-spionen Sergei Skripal Journalister, der efterforsker russisk militær efterr -
 Det første helt digitale atomreaktorsystem i USA installeret på Purdue UniversityPurdues atomreaktor har nu digitale muligheder, der muliggør forebyggende vedligeholdelse, en længere facilitets levetid og big data-applikationer. Kredit:Purdue University/Vincent Walter Atomkraf
Det første helt digitale atomreaktorsystem i USA installeret på Purdue UniversityPurdues atomreaktor har nu digitale muligheder, der muliggør forebyggende vedligeholdelse, en længere facilitets levetid og big data-applikationer. Kredit:Purdue University/Vincent Walter Atomkraf -
 Jævn og stabil opladning af elbilerKredit:CC0 Public Domain Siwar Khemakhem, Mouna Rekik, og Lotfi Krichen fra Control and Energy Management Laboratory ved National Engineering School of Sfax, i Tunesien, undersøger potentialet for
Jævn og stabil opladning af elbilerKredit:CC0 Public Domain Siwar Khemakhem, Mouna Rekik, og Lotfi Krichen fra Control and Energy Management Laboratory ved National Engineering School of Sfax, i Tunesien, undersøger potentialet for -
 Elbiler som et eksempel på et markedssvigtEn Renault Zoe oplader. Det er i øjeblikket en af de bedst sælgende plug-in-elbiler i Europa, men hvad ville der ske, hvis subsidierne tørrede ud? Kredit:Werner Hillebrand-Hansen/Wikipedia Revol
Elbiler som et eksempel på et markedssvigtEn Renault Zoe oplader. Det er i øjeblikket en af de bedst sælgende plug-in-elbiler i Europa, men hvad ville der ske, hvis subsidierne tørrede ud? Kredit:Werner Hillebrand-Hansen/Wikipedia Revol
- En liste over interessante emner for landbrugstale
- Brug af kunstige neurale netværk (ANN'er) til at forudsige busankomsttider
- Forskere ændrer membranproteiner for at gøre dem nemmere at studere
- Hvordan fungerer et refraktometer?
- Fordele og ulemper ved termisk kraft
- Honeywell hævder at have bygget den kvantecomputer, der har den bedst ydelse