


Hjerne-inspireret AI inspirerer til indsigt om hjernen (og omvendt)
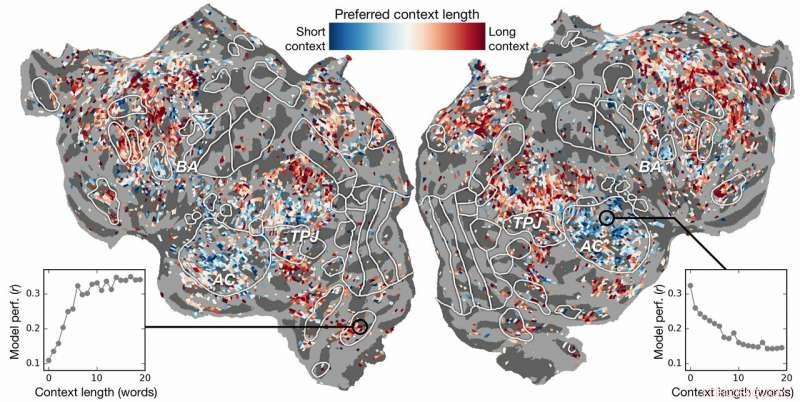
Kontekstlængdepræference på tværs af cortex. Et indeks for præference for kontekstlængde beregnes for hver voxel i ét emne og projiceres på det pågældende emnes kortikale overflade. Voxels vist i blåt modelleres bedst ved at bruge kort kontekst, mens røde voxels bedst modelleres med lang kontekst. Kredit:Huth lab, UT Austin
Kan kunstig intelligens (AI) hjælpe os med at forstå, hvordan hjernen forstår sprog? Kan neurovidenskab hjælpe os med at forstå, hvorfor AI og neurale netværk er effektive til at forudsige menneskelig opfattelse?
Forskning fra Alexander Huth og Shailee Jain fra University of Texas i Austin (UT Austin) tyder på, at begge dele er mulige.
I et papir præsenteret på 2018-konferencen om neurale informationsbehandlingssystemer (NeurIPS), forskerne beskrev resultaterne af eksperimenter, der brugte kunstige neurale netværk til at forudsige med større nøjagtighed end nogensinde før, hvordan forskellige områder i hjernen reagerer på specifikke ord.
"Når der kommer ord ind i vores hoveder, vi danner ideer om, hvad nogen siger til os, og vi ønsker at forstå, hvordan det kommer til os inde i hjernen, " sagde Huth, assisterende professor i neurovidenskab og datalogi ved UT Austin. "Det ser ud til, at der burde være systemer til det, men praktisk talt det er bare ikke sådan sprog fungerer. Som alt inden for biologi, det er meget svært at reducere til et simpelt sæt ligninger."
Arbejdet anvendte en type tilbagevendende neuralt netværk kaldet lang korttidshukommelse (LSTM), der i sine beregninger inkluderer forholdet mellem hvert ord og det, der kom før, for bedre at bevare konteksten.
"Hvis et ord har flere betydninger, du udleder betydningen af det ord for den pågældende sætning afhængigt af, hvad der blev sagt tidligere, " sagde Jain, en ph.d. studerende i Huths laboratorium ved UT Austin. "Vores hypotese er, at dette ville føre til bedre forudsigelser af hjerneaktivitet, fordi hjernen bekymrer sig om kontekst."
Det lyder indlysende, men i årtier har neurovidenskabelige eksperimenter betragtet hjernens reaktion på individuelle ord uden en følelse af deres forbindelse til kæder af ord eller sætninger. (Huth beskriver vigtigheden af at lave "den virkelige verden neurovidenskab" i et papir fra marts 2019 i Journal of Cognitive Neuroscience .)
I deres arbejde, forskerne kørte eksperimenter for at teste, og i sidste ende forudsige, hvordan forskellige områder i hjernen ville reagere, når man lytter til historier (specifikt, Moth Radio Hour). De brugte data indsamlet fra fMRI-maskiner (funktionel magnetisk resonansbilleddannelse), der fanger ændringer i blodets iltningsniveau i hjernen baseret på, hvor aktive grupper af neuroner er. Dette fungerer som en korrespondent for, hvor sprogbegreber er "repræsenteret" i hjernen.
Brug af kraftfulde supercomputere på Texas Advanced Computing Center (TACC), de trænede en sprogmodel ved hjælp af LSTM-metoden, så den effektivt kunne forudsige, hvilket ord der ville komme næste gang – en opgave, der ligner Googles autofuldførelsessøgninger, som det menneskelige sind er særlig dygtig til.
"I forsøget på at forudsige det næste ord, denne model skal implicit lære alle de andre ting om, hvordan sprog fungerer, " sagde Huth, "som hvilke ord har tendens til at følge andre ord, uden faktisk at få adgang til hjernen eller nogen data om hjernen."
Baseret på både sprogmodellen og fMRI-data, de trænede et system, der kunne forudsige, hvordan hjernen ville reagere, når den hører hvert ord i en ny historie for første gang.
Tidligere indsats havde vist, at det er muligt at lokalisere sprogreaktioner i hjernen effektivt. Imidlertid, den nye forskning viste, at tilføjelse af det kontekstuelle element - i dette tilfælde op til 20 ord, der kom før - forbedrede forudsigelser af hjerneaktivitet betydeligt. De fandt ud af, at deres forudsigelser forbedres, selv når den mindste mængde kontekst blev brugt. Jo mere kontekst der gives, jo bedre nøjagtighed er deres forudsigelser.
"Vores analyse viste, at hvis LSTM inkorporerer flere ord, så bliver den bedre til at forudsige det næste ord, " sagde Jain, "hvilket betyder, at det skal indeholde oplysninger fra alle ord i fortiden."
Forskningen gik videre. Det undersøgte, hvilke dele af hjernen, der var mere følsomme over for mængden af inkluderet kontekst. De fandt, for eksempel, at begreber, der synes at være lokaliseret til den auditive cortex, var mindre afhængige af konteksten.
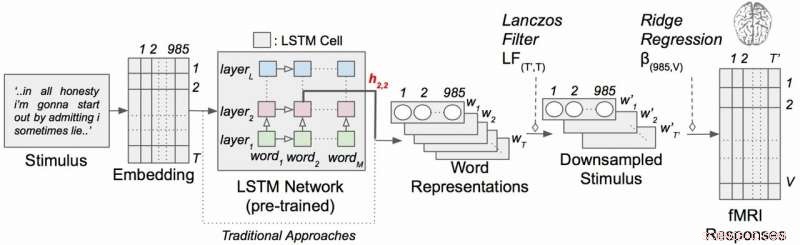
Kontekstuel sprogkodningsmodel med narrative stimuli. Hvert ord i historien projiceres først ind i et 985-dimensionelt indlejringsrum. Sekvenser af ordrepræsentationer føres derefter ind i et LSTM-netværk, der var fortrænet som sprogmodel. Kredit:Huth lab, UT Austin
"Hvis du hører ordet hund, dette område er ligeglad med, hvad de 10 ord var før det, det kommer bare til at reagere på lyden af ordet hund", Huth forklarede.
På den anden side, hjerneområder, der beskæftiger sig med tænkning på højere niveau, var lettere at udpege, når mere kontekst blev inkluderet. Dette understøtter teorier om sindet og sprogforståelse.
"Der var en rigtig fin overensstemmelse mellem hierarki af det kunstige netværk og hierarki i hjernen, som vi fandt interessant, " sagde Huth.
Naturlig sprogbehandling – eller NLP – har taget store fremskridt i de seneste år. Men når det kommer til at besvare spørgsmål, have naturlige samtaler, eller analysere følelserne i skrevne tekster, NLP har stadig lang vej igen. Forskerne mener, at deres LSTM-udviklede sprogmodel kan hjælpe på disse områder.
LSTM (og neurale netværk generelt) fungerer ved at tildele værdier i højdimensionelt rum til individuelle komponenter (her, ord), så hver komponent kan defineres ved dens tusindvis af forskellige relationer til mange andre ting.
Forskerne trænede sprogmodellen ved at fodre den med titusinder af millioner af ord fra Reddit-indlæg. Deres system lavede derefter forudsigelser for, hvordan tusindvis af voxels (tredimensionelle pixels) i hjernen på seks forsøgspersoner ville reagere på et andet sæt historier, som hverken modellen eller individerne havde hørt før. Fordi de var interesserede i virkningerne af kontekstlængde og virkningen af individuelle lag i det neurale netværk, de testede i det væsentlige 60 forskellige faktorer (20 længder af kontekstbevarelse og tre forskellige lagdimensioner) for hvert emne.
Alt dette fører til beregningsproblemer af enorm skala, kræver enorme mængder computerkraft, hukommelse, opbevaring, og datahentning. TACC's ressourcer var velegnede til problemet. Forskerne brugte Maverick-supercomputeren, som indeholder både GPU'er og CPU'er til computeropgaverne, og Corral, en lagrings- og datastyringsressource, at bevare og distribuere dataene. Ved at parallelisere problemet på tværs af mange processorer, de var i stand til at køre beregningseksperimentet på uger i stedet for år.
"For at udvikle disse modeller effektivt, du har brug for en masse træningsdata, " sagde Huth. "Det betyder, at du skal gennemgå hele dit datasæt, hver gang du vil opdatere vægtene. Og det er i sagens natur meget langsomt, hvis du ikke bruger parallelle ressourcer som dem hos TACC."
Hvis det lyder komplekst, godt – det er det.
Dette får Huth og Jain til at overveje en mere strømlinet version af systemet, hvor i stedet for at udvikle en sprogforudsigelsesmodel og derefter anvende den på hjernen, de udvikler en model, der direkte forudsiger hjernens reaktion. De kalder dette et ende-til-ende-system, og det er her, Huth og Jain håber at gå hen i deres fremtidige forskning. En sådan model ville forbedre dens ydeevne direkte på hjernens reaktioner. En forkert forudsigelse af hjerneaktivitet ville give feedback til modellen og anspore til forbedringer.
"Hvis dette virker, så er det muligt, at dette netværk kunne lære at læse tekst eller indtage sprog på samme måde, som vores hjerner gør, " sagde Huth. "Forestil dig Google Oversæt, men den forstår hvad du siger i stedet for bare at lære et sæt regler."
Med et sådant system på plads, Huth mener, at det kun er et spørgsmål om tid, før et tankelæsesystem, der kan omsætte hjerneaktivitet til sprog, er gennemførligt. I mellemtiden, de får indsigt i både neurovidenskab og kunstig intelligens fra deres eksperimenter.
"Hjernen er en meget effektiv regnemaskine, og formålet med kunstig intelligens er at bygge maskiner, der er rigtig gode til alle de opgaver, en hjerne kan udføre, " sagde Jain. "Men, vi forstår ikke meget om hjernen. Så, vi forsøger at bruge kunstig intelligens til først at stille spørgsmålstegn ved, hvordan hjernen fungerer, og så, baseret på den indsigt, vi opnår gennem denne forhørsmetode, og gennem teoretisk neurovidenskab, vi bruger disse resultater til at udvikle bedre kunstig intelligens.
"Idéen er at forstå kognitive systemer, både biologiske og kunstige, og at bruge dem sammen til at forstå og bygge bedre maskiner."
Sidste artikelElbiler som et eksempel på et markedssvigt
Næste artikelMIT-holds plukke- og placeringssystem er på et andet niveau
 Varme artikler
Varme artikler
-
 Undersøgelse tester ydeevnen af elektrisk fast drivmiddelFotografi af PTFE (venstre) og HIPEP (højre) drivmiddelprøver brugt i testen. Kredit:University of Illinois Department of Aerospace Engineering Elektriske faste drivmidler er ved at blive udforske
Undersøgelse tester ydeevnen af elektrisk fast drivmiddelFotografi af PTFE (venstre) og HIPEP (højre) drivmiddelprøver brugt i testen. Kredit:University of Illinois Department of Aerospace Engineering Elektriske faste drivmidler er ved at blive udforske -
 Retten beordrer dieselforbud på større Berlin-vejeBerlins berømte Friedrichstrasse er omfattet af dieselforbuddet Berlin kan udelukke dieselbilister fra større hovedveje næste år, efter at en domstol tirsdag beordrede den tyske hovedstad til at f
Retten beordrer dieselforbud på større Berlin-vejeBerlins berømte Friedrichstrasse er omfattet af dieselforbuddet Berlin kan udelukke dieselbilister fra større hovedveje næste år, efter at en domstol tirsdag beordrede den tyske hovedstad til at f -
 Snapchat tjekker for bedrag i politiske annoncerSnapchat siger, at det forbyder politiske annoncer, der er vildledende og bruger et internt team til at gennemgå sådanne betalte beskeder Snap på mandag bekræftede, at det kontrollerer politiske a
Snapchat tjekker for bedrag i politiske annoncerSnapchat siger, at det forbyder politiske annoncer, der er vildledende og bruger et internt team til at gennemgå sådanne betalte beskeder Snap på mandag bekræftede, at det kontrollerer politiske a -
 GM minder om 1,2 mio. Pickupper, SUV'er til servostyringsproblemDenne 25. januar, 2010, fil foto, viser et General Motors Co. -logo under et pressemøde i Detroit. General Motors torsdag, 13. september kl. 2018, husker mere end en million store pickupper og SUVer i
GM minder om 1,2 mio. Pickupper, SUV'er til servostyringsproblemDenne 25. januar, 2010, fil foto, viser et General Motors Co. -logo under et pressemøde i Detroit. General Motors torsdag, 13. september kl. 2018, husker mere end en million store pickupper og SUVer i
- Forskere finder nye mindre planeter ud over Neptun
- Effekterne af Lunar Eclipses
- USA tapper den tidligere anklager som vagthund over Chinas ZTE
- Gratis bredbånd:Internetadgang er nu en menneskeret, uanset hvem der betaler regningerne
- Franske parlamentsmedlemmer giver tilbage at give onlineplatforme 24 timer til at fjerne hadefulde y…
- Hvad betyder hydrogeneret?