


En bio-inspireret tilgang til at forbedre læring i ANN'er
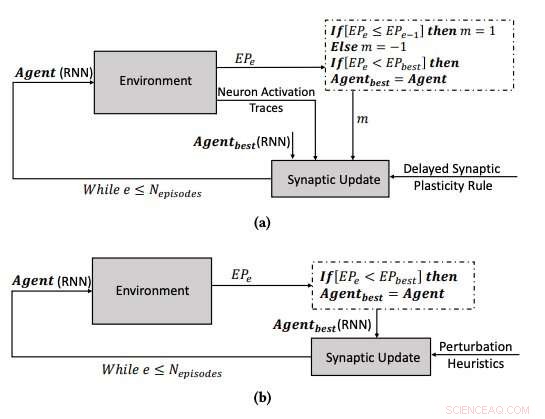
(a) Læringsprocessen ved hjælp af den forsinkede synaptiske plasticitet, og (b) indlæringsprocessen ved at optimere parametrene for RNN'erne ved hjælp af bakkeklatringsalgoritmen. Kredit:Yaman et al.
Den menneskelige hjerne ændrer sig konstant over tid, dannelse af nye synaptiske forbindelser baseret på erfaringer og information lært gennem et helt liv. I løbet af de sidste par år, Forskere i kunstig intelligens (AI) har forsøgt at reproducere denne fascinerende evne, kendt som 'plasticitet, ' i kunstige neurale netværk (ANN'er).
Forskere ved Eindhoven University of Technology (Tu/e) og University of Trento har for nylig foreslået en ny tilgang inspireret af biologiske mekanismer, der kunne forbedre læring i ANN'er. Deres studie, skitseret i et papir, der er forududgivet på arXiv, blev finansieret af EU's Horizon 2020 forsknings- og innovationsprogram.
"En af de fascinerende egenskaber ved biologiske neurale netværk (BNN'er) er deres plasticitet, som giver dem mulighed for at lære ved at ændre deres konfiguration baseret på erfaring, "Anil Yaman, en af de forskere, der har udført undersøgelsen, fortalte TechXplore. "Ifølge den nuværende fysiologiske forståelse, disse ændringer udføres på individuelle synapser baseret på de lokale interaktioner af neuroner. Imidlertid, fremkomsten af en sammenhængende global læringsadfærd fra disse individuelle interaktioner er ikke særlig godt forstået."
Inspireret af BNNs plasticitet og dens evolutionære proces, Yaman og hans kolleger ønskede at efterligne biologisk plausible indlæringsmekanismer i kunstige systemer. For at modellere plasticitet i ANN'er, forskere bruger typisk noget, der kaldes hebbiske læringsregler, som er regler, der opdaterer synapser baseret på neurale aktiveringer og forstærkningssignaler modtaget fra miljøet.

Flere uafhængige kørsler af læreprocesserne ved at bruge forskellige udviklede forsinket synaptiske plasticitetsregler (den bedste DSP-regel er vist med grønt). Kredit:Yaman et al.
Når forstærkningssignaler ikke er tilgængelige umiddelbart efter hver netværksoutput, imidlertid, nogle problemer kan opstå, gør det sværere for netværket at associere de relevante neuronaktiveringer med forstærkningssignalet. For at overvinde dette problem, kendt som 'det distale belønningsproblem,' ' forskerne udvidede hebbiske plasticitetsregler, så de ville muliggøre læring i distale belønningstilfælde. Deres tilgang, kaldet forsinket synaptisk plasticitet (DSP), bruger noget, der kaldes neuronaktiveringsspor (NAT'er) til at give yderligere lagring i hver synapse, samt at holde styr på neuronaktiveringer, når netværket udfører en bestemt opgave.
"Synaptiske plasticitetsregler er baseret på de lokale aktiveringer af neuroner og et forstærkningssignal, " forklarede Yaman. "Men, i de fleste indlæringsproblemer, forstærkningssignalerne modtages efter et vist tidsrum i stedet for umiddelbart efter hver handling af netværket. I dette tilfælde, det bliver problematisk at forbinde forstærkningssignalerne med aktiveringer af neuroner. I dette arbejde, vi foreslog at bruge det, vi kaldte 'neuronaktiveringsspor,' ' at gemme statistikken over neuronaktiveringer i hver synapse og informere de synaptiske plasticitetsregler om, hvordan man udfører forsinkede synaptiske ændringer."
Et af de mest meningsfulde aspekter af den tilgang, som Yaman og hans kolleger har udtænkt, er, at den ikke antager global information om det problem, som det neurale netværk vil løse. Desuden, den afhænger ikke af den specifikke ANN-arkitektur, og den er derfor meget generaliserbar.
"Praktisk set, vores undersøgelse kan lægge grundlaget for nye læringsskemaer, der kan bruges i en række neurale netværksapplikationer, såsom robotter og autonome køretøjer, og generelt i alle tilfælde, hvor en agent skal udføre adaptiv adfærd i mangel af en øjeblikkelig belønning opnået fra sine handlinger, " Giovanni Iacca, en anden forsker involveret i undersøgelsen, fortalte TechXplore. "For eksempel, i AI til videogaming, en handling på det aktuelle tidstrin fører måske ikke nødvendigvis til en belønning lige nu, men først efter nogen tid; en agent, der viser personligt tilpassede annoncer, får muligvis først en "belønning" fra brugeradfærden efter et stykke tid, etc.)."
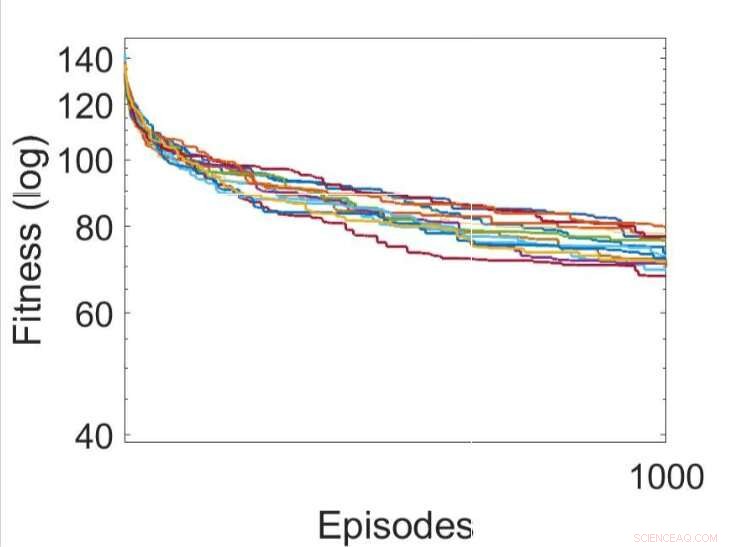
Flere uafhængige kørsler af læreprocesserne ved at optimere parametrene for RNN'erne ved hjælp af bakkeklatringsalgoritmen. Kredit:Yaman et al.
Forskerne testede deres nyligt tilpassede hebbiske plasticitetsregler i en simulering af et tredobbelt T-labyrint-miljø. I dette miljø, en agent styret af et simpelt tilbagevendende neuralt netværk (RNN) skal lære at finde en blandt otte mulige målpositioner, startende fra en tilfældig netværkskonfiguration.
Yaman, Iacca og deres kolleger sammenlignede ydeevnen opnået ved hjælp af deres tilgang med den, der blev opnået, når en agent blev trænet ved hjælp af en analog iterativ lokal søgealgoritme, kaldet bakkeklatring (HC). Den vigtigste forskel mellem HC-klatrealgoritmen og deres tilgang er, at førstnævnte ikke bruger nogen domæneviden (dvs. lokale aktiveringer af neuroner), mens sidstnævnte gør.
Resultaterne indsamlet af forskerne tyder på, at de synaptiske opdateringer udført af deres DSP-regler fører til mere effektiv træning og i sidste ende bedre ydeevne end HC-algoritmen. I fremtiden, deres tilgang kunne bidrage til at forbedre langsigtet læring i ANN'er, giver kunstige systemer mulighed for effektivt at bygge nye forbindelser baseret på deres erfaringer.
"Vi er hovedsageligt interesserede i at forstå den nye adfærd og indlæringsdynamikken i kunstige neurale netværk, og udvikle en sammenhængende model til at forklare, hvordan synaptisk plasticitet opstår i forskellige læringsscenarier, " sagde Yaman. "Jeg tror, der er enorme muligheder for fremtidig forskning på dette område, for eksempel vil det være interessant at skalere den foreslåede tilgang til store komplekse problemer (såvel som dybe netværk) og opnå biologisk inspirerede læringsmekanismer, der kræver den mindste mængde supervision (eller ingen overhovedet).
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Konvertering af affald, en restressource, til biobrændstoffer reducerer emissionerneFlyselskaber er begyndt at integrere affaldsbrændstoffer i den kommercielle luftfartsindustri, ledet af United Airlines partnerskab med AltAir Fuels i 2016. Kredit:United Airlines USA kunne produc
Konvertering af affald, en restressource, til biobrændstoffer reducerer emissionerneFlyselskaber er begyndt at integrere affaldsbrændstoffer i den kommercielle luftfartsindustri, ledet af United Airlines partnerskab med AltAir Fuels i 2016. Kredit:United Airlines USA kunne produc -
 Teknologistart-ups, der fejler hurtigt, lykkes hurtigereDet tog Thomas Edison utallige fejl, før det lykkedes ham at udvikle en salgbar pære. Kredit:Shutterstock Fejlraten for nye teknologibaserede virksomheder er chokerende høje. Det anslås, at 75 pro
Teknologistart-ups, der fejler hurtigt, lykkes hurtigereDet tog Thomas Edison utallige fejl, før det lykkedes ham at udvikle en salgbar pære. Kredit:Shutterstock Fejlraten for nye teknologibaserede virksomheder er chokerende høje. Det anslås, at 75 pro -
 Tesla -aktier falder efter amerikansk svindelsag mod MuskDen amerikanske Securities and Exchange Commission har anlagt sag mod Teslas Elon Musk for værdipapirbedrageri Tesla -aktier faldt fredag i den første session, siden amerikanske værdipapirregula
Tesla -aktier falder efter amerikansk svindelsag mod MuskDen amerikanske Securities and Exchange Commission har anlagt sag mod Teslas Elon Musk for værdipapirbedrageri Tesla -aktier faldt fredag i den første session, siden amerikanske værdipapirregula -
 Spaniens Telefonica tilbyder frivillig afskedigelse til 5, 000 ansatteTelefonica sagde, at deres afskedigelsesplan er en del af dens indsats for at tilpasse sin arbejdsstyrke til behovene for fremtidige udfordringer Den spanske telekomgigant Telefonica sagde tirsdag
Spaniens Telefonica tilbyder frivillig afskedigelse til 5, 000 ansatteTelefonica sagde, at deres afskedigelsesplan er en del af dens indsats for at tilpasse sin arbejdsstyrke til behovene for fremtidige udfordringer Den spanske telekomgigant Telefonica sagde tirsdag
- Sådan finder du pH for en given Molarity
- Halvdelen af Facebook-brugere siger, at de ikke forstår, hvordan nyhedsfeed fungerer
- Video:Hvad er øjenskorper lavet af?
- Humor er både en forhindring og en målestok for at forbedre AI, menneskelig interaktion
- Kulstofcykling i skovjordsforskning præsenteret
- Når menneskelivet begynder, er et spørgsmål om politik, ikke biologi